Contact-aware Human Motion Generation from Textual Descriptions

0

Sign in to get full access
Overview
- This paper presents a novel approach for generating human motion from textual descriptions.
- It introduces a contact-aware model that can generate realistic and physically plausible 3D human motions based on text input.
- The model takes into account the interactions between the human body and the environment, enabling it to generate motions that respect physical constraints.
Plain English Explanation
The research team has developed a system that can generate 3D human motions based on textual descriptions. Rather than simply animating a character to perform a described action, their contact-aware model considers how the human body would physically interact with the environment.
For example, if the text describes someone "sitting on a chair," the model will make sure the character's body realistically makes contact with the chair and follows the physical constraints of sitting down. This attention to detail results in more natural and believable motions compared to previous text-to-motion approaches.
The researchers trained their model on a large dataset of human-object interactions and used physics-based simulation to ensure the generated motions respect the laws of physics. This allows the system to edit existing 3D human motions in a semantically meaningful way based on new text instructions.
Technical Explanation
The key innovation of this work is the integration of contact modeling into a text-driven human motion generation framework. Previous approaches have generated motions solely based on the textual description, without considering the physical interactions between the human body and the environment.
The researchers developed a neural network architecture that takes in a textual description as input and outputs a 3D human motion sequence. The model consists of several components:
- Text Encoder: This module encodes the input text into a compact feature representation.
- Contact Modeling: This component predicts the contacts between the human body and the environment based on the text features.
- Motion Generation: This module generates the final 3D human motion sequence, conditioned on both the text features and the predicted contacts.
The contact modeling component is critical, as it allows the system to generate motions that respect physical constraints and produce more realistic, natural-looking results. The researchers trained this module on a large dataset of human-object interactions, enabling the model to learn the typical contact patterns associated with different actions and scenarios.
During inference, the full pipeline takes a textual description as input, predicts the relevant contacts, and then generates the corresponding 3D human motion sequence. The model can also be used to edit existing motions by adjusting the textual description and re-generating the motion.
Critical Analysis
The primary strength of this work is its ability to generate physically plausible human motions from text input, thanks to the integration of contact modeling. This is an important advance over previous text-to-motion approaches, which often produced motions that lacked realism and physical grounding.
However, the paper does not extensively discuss the limitations of the proposed approach. For example, the dataset used for training the contact modeling component may not cover the full range of possible human-environment interactions, which could limit the model's generalization capabilities.
Additionally, the paper does not provide a detailed analysis of failure cases or edge cases where the model might struggle. It would be valuable to understand the types of textual descriptions or scenarios that pose challenges for the system.
Further research could also explore ways to make the text-to-motion generation process more interactive, allowing users to iteratively refine the output by providing additional text instructions or feedback. This could lead to more versatile and user-friendly motion editing tools.
Conclusion
This paper presents a significant step forward in the field of text-driven human motion generation by introducing a contact-aware model that can produce physically realistic 3D motions. The integration of contact modeling is a key innovation that enables the system to generate more natural and believable animations compared to previous approaches.
The potential applications of this technology are broad, ranging from interactive animation tools to virtual reality experiences and even robotics. As the field of text-to-motion generation continues to evolve, approaches like the one described in this paper will play an important role in bridging the gap between language and embodied physical interactions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Contact-aware Human Motion Generation from Textual Descriptions
Sihan Ma, Qiong Cao, Jing Zhang, Dacheng Tao
This paper addresses the problem of generating 3D interactive human motion from text. Given a textual description depicting the actions of different body parts in contact with static objects, we synthesize sequences of 3D body poses that are visually natural and physically plausible. Yet, this task poses a significant challenge due to the inadequate consideration of interactions by physical contacts in both motion and textual descriptions, leading to unnatural and implausible sequences. To tackle this challenge, we create a novel dataset named RICH-CAT, representing Contact-Aware Texts constructed from the RICH dataset. RICH-CAT comprises high-quality motion, accurate human-object contact labels, and detailed textual descriptions, encompassing over 8,500 motion-text pairs across 26 indoor/outdoor actions. Leveraging RICH-CAT, we propose a novel approach named CATMO for text-driven interactive human motion synthesis that explicitly integrates human body contacts as evidence. We employ two VQ-VAE models to encode motion and body contact sequences into distinct yet complementary latent spaces and an intertwined GPT for generating human motions and contacts in a mutually conditioned manner. Additionally, we introduce a pre-trained text encoder to learn textual embeddings that better discriminate among various contact types, allowing for more precise control over synthesized motions and contacts. Our experiments demonstrate the superior performance of our approach compared to existing text-to-motion methods, producing stable, contact-aware motion sequences. Code and data will be available for research purposes at https://xymsh.github.io/RICH-CAT/
Read more9/17/2024
⚙️
0
Generating Human Motion in 3D Scenes from Text Descriptions
Zhi Cen, Huaijin Pi, Sida Peng, Zehong Shen, Minghui Yang, Shuai Zhu, Hujun Bao, Xiaowei Zhou
Generating human motions from textual descriptions has gained growing research interest due to its wide range of applications. However, only a few works consider human-scene interactions together with text conditions, which is crucial for visual and physical realism. This paper focuses on the task of generating human motions in 3D indoor scenes given text descriptions of the human-scene interactions. This task presents challenges due to the multi-modality nature of text, scene, and motion, as well as the need for spatial reasoning. To address these challenges, we propose a new approach that decomposes the complex problem into two more manageable sub-problems: (1) language grounding of the target object and (2) object-centric motion generation. For language grounding of the target object, we leverage the power of large language models. For motion generation, we design an object-centric scene representation for the generative model to focus on the target object, thereby reducing the scene complexity and facilitating the modeling of the relationship between human motions and the object. Experiments demonstrate the better motion quality of our approach compared to baselines and validate our design choices.
Read more5/14/2024
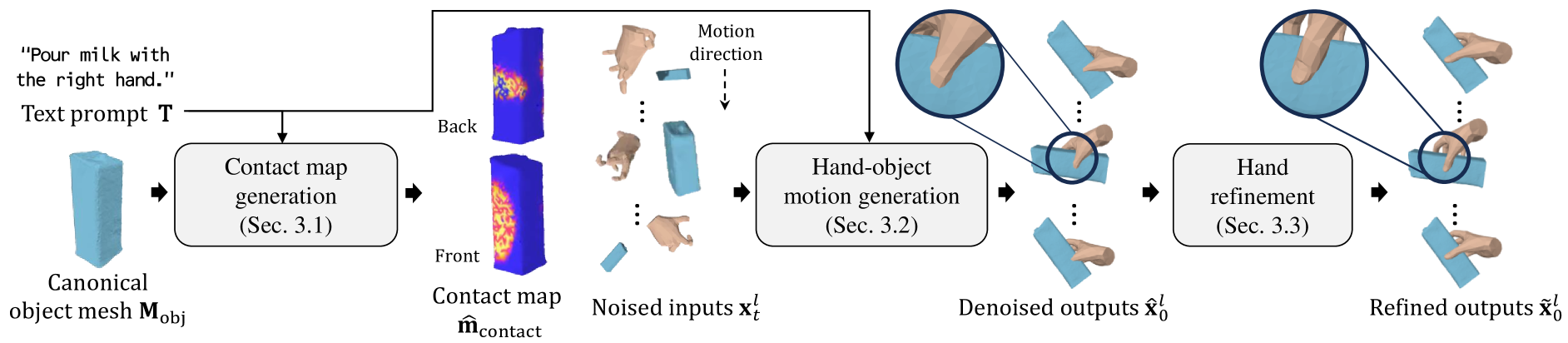
0
Text2HOI: Text-guided 3D Motion Generation for Hand-Object Interaction
Junuk Cha, Jihyeon Kim, Jae Shin Yoon, Seungryul Baek
This paper introduces the first text-guided work for generating the sequence of hand-object interaction in 3D. The main challenge arises from the lack of labeled data where existing ground-truth datasets are nowhere near generalizable in interaction type and object category, which inhibits the modeling of diverse 3D hand-object interaction with the correct physical implication (e.g., contacts and semantics) from text prompts. To address this challenge, we propose to decompose the interaction generation task into two subtasks: hand-object contact generation; and hand-object motion generation. For contact generation, a VAE-based network takes as input a text and an object mesh, and generates the probability of contacts between the surfaces of hands and the object during the interaction. The network learns a variety of local geometry structure of diverse objects that is independent of the objects' category, and thus, it is applicable to general objects. For motion generation, a Transformer-based diffusion model utilizes this 3D contact map as a strong prior for generating physically plausible hand-object motion as a function of text prompts by learning from the augmented labeled dataset; where we annotate text labels from many existing 3D hand and object motion data. Finally, we further introduce a hand refiner module that minimizes the distance between the object surface and hand joints to improve the temporal stability of the object-hand contacts and to suppress the penetration artifacts. In the experiments, we demonstrate that our method can generate more realistic and diverse interactions compared to other baseline methods. We also show that our method is applicable to unseen objects. We will release our model and newly labeled data as a strong foundation for future research. Codes and data are available in: https://github.com/JunukCha/Text2HOI.
Read more4/3/2024

0
MotionFix: Text-Driven 3D Human Motion Editing
Nikos Athanasiou, Alp'ar Ceske, Markos Diomataris, Michael J. Black, Gul Varol
The focus of this paper is 3D motion editing. Given a 3D human motion and a textual description of the desired modification, our goal is to generate an edited motion as described by the text. The challenges include the lack of training data and the design of a model that faithfully edits the source motion. In this paper, we address both these challenges. We build a methodology to semi-automatically collect a dataset of triplets in the form of (i) a source motion, (ii) a target motion, and (iii) an edit text, and create the new MotionFix dataset. Having access to such data allows us to train a conditional diffusion model, TMED, that takes both the source motion and the edit text as input. We further build various baselines trained only on text-motion pairs datasets, and show superior performance of our model trained on triplets. We introduce new retrieval-based metrics for motion editing and establish a new benchmark on the evaluation set of MotionFix. Our results are encouraging, paving the way for further research on finegrained motion generation. Code and models will be made publicly available.
Read more8/2/2024