Context-Aware Clustering using Large Language Models
2405.00988
0
0
🔗
Abstract
Despite the remarkable success of Large Language Models (LLMs) in text understanding and generation, their potential for text clustering tasks remains underexplored. We observed that powerful closed-source LLMs provide good quality clusterings of entity sets but are not scalable due to the massive compute power required and the associated costs. Thus, we propose CACTUS (Context-Aware ClusTering with aUgmented triplet losS), a systematic approach that leverages open-source LLMs for efficient and effective supervised clustering of entity subsets, particularly focusing on text-based entities. Existing text clustering methods fail to effectively capture the context provided by the entity subset. Moreover, though there are several language modeling based approaches for clustering, very few are designed for the task of supervised clustering. This paper introduces a novel approach towards clustering entity subsets using LLMs by capturing context via a scalable inter-entity attention mechanism. We propose a novel augmented triplet loss function tailored for supervised clustering, which addresses the inherent challenges of directly applying the triplet loss to this problem. Furthermore, we introduce a self-supervised clustering task based on text augmentation techniques to improve the generalization of our model. For evaluation, we collect ground truth clusterings from a closed-source LLM and transfer this knowledge to an open-source LLM under the supervised clustering framework, allowing a faster and cheaper open-source model to perform the same task. Experiments on various e-commerce query and product clustering datasets demonstrate that our proposed approach significantly outperforms existing unsupervised and supervised baselines under various external clustering evaluation metrics.
Create account to get full access
Overview
- The paper explores the potential of Large Language Models (LLMs) for text clustering tasks, which have been underexplored despite the remarkable success of LLMs in text understanding and generation.
- The researchers observed that powerful closed-source LLMs provide good quality clusterings of entity sets, but they are not scalable due to the massive compute power required and the associated costs.
- To address this, the paper proposes CACTUS (Context-Aware ClusTering with aUgmented triplet losS), a systematic approach that leverages open-source LLMs for efficient and effective supervised clustering of entity subsets, particularly focusing on text-based entities.
Plain English Explanation
Large Language Models (LLMs) have become incredibly powerful at understanding and generating text, but their potential for organizing and grouping text-based entities into meaningful clusters has not been fully explored. The researchers noticed that while high-powered, closed-source LLMs can group entities well, this process is not scalable because it requires massive computing resources and is very costly.
To make this text clustering capability more accessible, the researchers developed CACTUS, a new approach that uses open-source LLMs to efficiently and effectively group text-based entities into clusters. The key innovation is that CACTUS captures the context between entities using a scalable attention mechanism, and it introduces a novel loss function tailored for supervised clustering to address the inherent challenges of directly applying existing techniques.
The researchers also developed a self-supervised clustering task based on text augmentation techniques to help the model generalize better. This allows an open-source LLM to perform the same clustering tasks as the powerful closed-source models, but at a fraction of the cost and computing power.
Technical Explanation
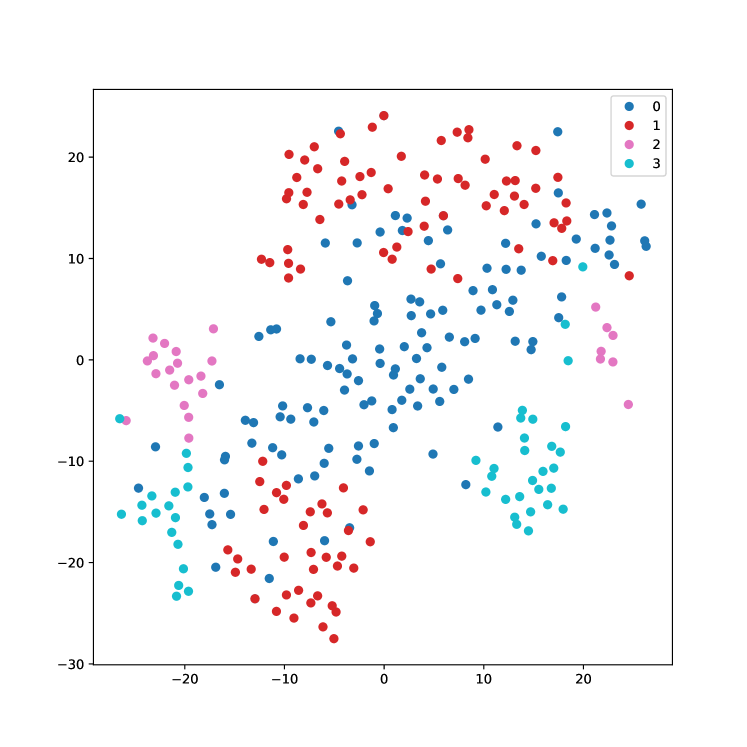
The paper introduces CACTUS, a novel approach for efficiently and effectively clustering text-based entities using open-source LLMs. Existing text clustering methods often fail to effectively capture the context provided by the entity subset, and while there are several language modeling-based approaches for clustering, very few are designed for the specific task of supervised clustering.
CACTUS addresses these limitations by leveraging an inter-entity attention mechanism to capture the relevant context, and a novel augmented triplet loss function tailored for supervised clustering. This loss function helps to overcome the challenges of directly applying the standard triplet loss to the supervised clustering problem.
Furthermore, the researchers introduce a self-supervised clustering task based on text augmentation techniques, which helps to improve the generalization of the CACTUS model. This allows the open-source LLM to perform the same clustering tasks as powerful closed-source models, but at a much lower cost and with greater scalability.
The paper evaluates CACTUS on various e-commerce query and product clustering datasets, demonstrating that it significantly outperforms existing unsupervised and supervised baselines under various external clustering evaluation metrics.
Critical Analysis
The paper presents a compelling approach to leveraging open-source LLMs for effective and scalable text-based entity clustering. The key innovations, such as the inter-entity attention mechanism and the augmented triplet loss function, appear to be well-designed and thoughtfully implemented.
One potential limitation of the research is that it relies on transferring knowledge from closed-source LLMs, which may not be feasible in all real-world scenarios. The researchers acknowledge this and suggest exploring ways to train the model entirely using open-source resources, potentially through harnessing the power of large language model uncertainty or contextual categorization enhancement through LLMs' latent space.
Additionally, the paper could have delved deeper into the potential biases or limitations of the LLMs used, and how those may impact the clustering results. Exploring the context-enhanced language models for generating multi-paper or LTNER: Large Language Model Tagging Named Entity approaches could provide valuable insights in this regard.
Overall, the research presented in this paper is a significant step forward in making powerful text clustering capabilities accessible to a wider range of applications and researchers through the use of open-source LLMs.
Conclusion
The paper introduces CACTUS, a novel approach that leverages open-source LLMs for efficient and effective supervised clustering of text-based entities. By capturing the relevant context between entities and employing a tailored loss function, CACTUS outperforms existing baselines on various e-commerce datasets.
This research has the potential to democratize the use of advanced text clustering techniques, allowing a broader range of applications and researchers to benefit from the power of LLMs without the need for massive computational resources. As the field of language modeling continues to evolve, the insights and methods presented in this paper can pave the way for further advancements in making large-scale text understanding and organization more accessible and scalable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ZeroDL: Zero-shot Distribution Learning for Text Clustering via Large Language Models
Hwiyeol Jo, Hyunwoo Lee, Taiwoo Park
0
0
The recent advancements in large language models (LLMs) have brought significant progress in solving NLP tasks. Notably, in-context learning (ICL) is the key enabling mechanism for LLMs to understand specific tasks and grasping nuances. In this paper, we propose a simple yet effective method to contextualize a task toward a specific LLM, by (1) observing how a given LLM describes (all or a part of) target datasets, i.e., open-ended zero-shot inference, and (2) aggregating the open-ended inference results by the LLM, and (3) finally incorporate the aggregated meta-information for the actual task. We show the effectiveness of this approach in text clustering tasks, and also highlight the importance of the contextualization through examples of the above procedure.
6/21/2024

Supervised Knowledge Makes Large Language Models Better In-context Learners
Linyi Yang, Shuibai Zhang, Zhuohao Yu, Guangsheng Bao, Yidong Wang, Jindong Wang, Ruochen Xu, Wei Ye, Xing Xie, Weizhu Chen, Yue Zhang
0
0
Large Language Models (LLMs) exhibit emerging in-context learning abilities through prompt engineering. The recent progress in large-scale generative models has further expanded their use in real-world language applications. However, the critical challenge of improving the generalizability and factuality of LLMs in natural language understanding and question answering remains under-explored. While previous in-context learning research has focused on enhancing models to adhere to users' specific instructions and quality expectations, and to avoid undesired outputs, little to no work has explored the use of task-Specific fine-tuned Language Models (SLMs) to improve LLMs' in-context learning during the inference stage. Our primary contribution is the establishment of a simple yet effective framework that enhances the reliability of LLMs as it: 1) generalizes out-of-distribution data, 2) elucidates how LLMs benefit from discriminative models, and 3) minimizes hallucinations in generative tasks. Using our proposed plug-in method, enhanced versions of Llama 2 and ChatGPT surpass their original versions regarding generalizability and factuality. We offer a comprehensive suite of resources, including 16 curated datasets, prompts, model checkpoints, and LLM outputs across 9 distinct tasks. The code and data are released at: https://github.com/YangLinyi/Supervised-Knowledge-Makes-Large-Language-Models-Better-In-context-Learners. Our empirical analysis sheds light on the advantages of incorporating discriminative models into LLMs and highlights the potential of our methodology in fostering more reliable LLMs.
4/12/2024
Text clustering with LLM embeddings
Alina Petukhova, Jo~ao P. Matos-Carvalho, Nuno Fachada
0
0
Text clustering is an important approach for organising the growing amount of digital content, helping to structure and find hidden patterns in uncategorised data. However, the effectiveness of text clustering heavily relies on the choice of textual embeddings and clustering algorithms. We argue that recent advances in large language models (LLMs) can potentially improve this task. In this research, we investigated how different textual embeddings -- particularly those used in LLMs -- and clustering algorithms affect how text datasets are clustered. A series of experiments were conducted to assess how embeddings influence clustering results, the role played by dimensionality reduction through summarisation, and model size adjustment. Findings reveal that LLM embeddings excel at capturing subtleties in structured language, while BERT leads the lightweight options in performance. In addition, we observe that increasing model dimensionality and employing summarization techniques do not consistently lead to improvements in clustering efficiency, suggesting that these strategies require careful analysis to use in real-life models. These results highlight a complex balance between the need for refined text representation and computational feasibility in text clustering applications. This study extends traditional text clustering frameworks by incorporating embeddings from LLMs, providing a path for improved methodologies, while informing new avenues for future research in various types of textual analysis.
5/31/2024
Harnessing the Power of Large Language Model for Uncertainty Aware Graph Processing
Zhenyu Qian, Yiming Qian, Yuting Song, Fei Gao, Hai Jin, Chen Yu, Xia Xie
0
0
Handling graph data is one of the most difficult tasks. Traditional techniques, such as those based on geometry and matrix factorization, rely on assumptions about the data relations that become inadequate when handling large and complex graph data. On the other hand, deep learning approaches demonstrate promising results in handling large graph data, but they often fall short of providing interpretable explanations. To equip the graph processing with both high accuracy and explainability, we introduce a novel approach that harnesses the power of a large language model (LLM), enhanced by an uncertainty-aware module to provide a confidence score on the generated answer. We experiment with our approach on two graph processing tasks: few-shot knowledge graph completion and graph classification. Our results demonstrate that through parameter efficient fine-tuning, the LLM surpasses state-of-the-art algorithms by a substantial margin across ten diverse benchmark datasets. Moreover, to address the challenge of explainability, we propose an uncertainty estimation based on perturbation, along with a calibration scheme to quantify the confidence scores of the generated answers. Our confidence measure achieves an AUC of 0.8 or higher on seven out of the ten datasets in predicting the correctness of the answer generated by LLM.
4/15/2024