In-Context In-Context Learning with Transformer Neural Processes
2406.13493
0
0
🧠
Abstract
Neural processes (NPs) are a powerful family of meta-learning models that seek to approximate the posterior predictive map of the ground-truth stochastic process from which each dataset in a meta-dataset is sampled. There are many cases in which practitioners, besides having access to the dataset of interest, may also have access to other datasets that share similarities with it. In this case, integrating these datasets into the NP can improve predictions. We equip NPs with this functionality and describe this paradigm as in-context in-context learning. Standard NP architectures, such as the convolutional conditional NP (ConvCNP) or the family of transformer neural processes (TNPs), are not capable of in-context in-context learning, as they are only able to condition on a single dataset. We address this shortcoming by developing the in-context in-context learning pseudo-token TNP (ICICL-TNP). The ICICL-TNP builds on the family of PT-TNPs, which utilise pseudo-token-based transformer architectures to sidestep the quadratic computational complexity associated with regular transformer architectures. Importantly, the ICICL-TNP is capable of conditioning on both sets of datapoints and sets of datasets, enabling it to perform in-context in-context learning. We demonstrate the importance of in-context in-context learning and the effectiveness of the ICICL-TNP in a number of experiments.
Create account to get full access
Overview
- Neural Processes (NPs) are a type of meta-learning model that aim to approximate the underlying stochastic process of a dataset.
- In some cases, practitioners may have access to additional datasets that share similarities with the primary dataset of interest.
- Integrating these related datasets into the NP model can improve its predictive performance, a concept known as in-context in-context learning.
- Standard NP architectures, such as the Convolutional Conditional NP (ConvCNP) or Transformer Neural Processes (TNPs), are not capable of this type of in-context in-context learning.
- The paper introduces the In-Context In-Context Learning Pseudo-Token Transformer Neural Process (ICICL-TNP), which addresses this limitation by enabling conditioning on both individual datasets and sets of datasets.
Plain English Explanation
Neural Processes (NPs) are a type of machine learning model that aim to capture the underlying patterns and uncertainty in a dataset. Imagine you have a set of data points, like the daily temperatures in a city over time. An NP model would try to learn the general process that generated this data, so it could make predictions about future temperatures or temperatures in a different location.
Now, let's say you have access to not just the temperature data, but also other datasets that are similar, like precipitation or humidity. Integrating this additional context could help the NP model make better predictions about the temperature data. This is the idea behind "in-context in-context learning" - using related datasets to improve the learning and performance of the primary model.
However, existing NP architectures, like the Convolutional Conditional NP or Transformer Neural Processes, are not designed to handle this type of in-context learning. They can only condition on a single dataset at a time.
To address this limitation, the researchers developed a new model called the In-Context In-Context Learning Pseudo-Token Transformer Neural Process (ICICL-TNP). This model builds on the Pseudo-Token Transformer Neural Process (PT-TNP) architecture, which uses a more efficient transformer-based approach. The ICICL-TNP can condition on both individual datasets and sets of related datasets, enabling it to perform the in-context in-context learning that is crucial for many real-world applications.
Technical Explanation
The key innovation of the ICICL-TNP is its ability to condition on both individual datasets and sets of datasets, enabling it to perform in-context in-context learning. This is in contrast to standard NP architectures, such as the ConvCNP or family of TNPs, which can only condition on a single dataset at a time.
The ICICL-TNP builds on the PT-TNP architecture, which uses a pseudo-token-based transformer to improve computational efficiency compared to regular transformer models. The ICICL-TNP takes this a step further by introducing additional pseudo-tokens to represent the sets of datasets, in addition to the pseudo-tokens representing individual datapoints.
This allows the ICICL-TNP to learn and reason about the relationships between the primary dataset and the related datasets, which can lead to improved predictive performance. The researchers demonstrate the effectiveness of the ICICL-TNP in a series of experiments, showing its advantages over existing NP models in settings where in-context in-context learning is beneficial.
Critical Analysis
The paper introduces a novel and potentially impactful extension to the NP framework, addressing an important limitation of existing architectures. The ability to condition on both individual datasets and sets of datasets is a valuable capability that could unlock new applications for NPs.
That said, the paper does not provide a comprehensive analysis of the limitations or potential issues with the ICICL-TNP approach. For example, it would be helpful to understand how the model scales as the number of datasets or dataset size increases, as this could impact its practical applicability. Additionally, the paper does not explore the interpretability or explainability of the ICICL-TNP, which is an important consideration for many real-world use cases.
Further research could also investigate the generalizability of the ICICL-TNP approach to other types of meta-learning models, or explore ways to make the in-context in-context learning process more transparent and understandable to users.
Conclusion
The ICICL-TNP represents an important advancement in the field of meta-learning, addressing a key limitation of standard NP architectures. By enabling conditioning on both individual datasets and sets of datasets, the ICICL-TNP opens up new possibilities for leveraging related data to improve predictive performance, with potential applications in a wide range of domains.
While the paper demonstrates the effectiveness of the ICICL-TNP, further research is needed to fully understand its limitations and explore ways to make the in-context in-context learning process more accessible and interpretable. As the field of meta-learning continues to evolve, innovations like the ICICL-TNP will play a crucial role in unlocking the power of contextual information and driving progress in a variety of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
MLPs Learn In-Context
William L. Tong, Cengiz Pehlevan
0
0
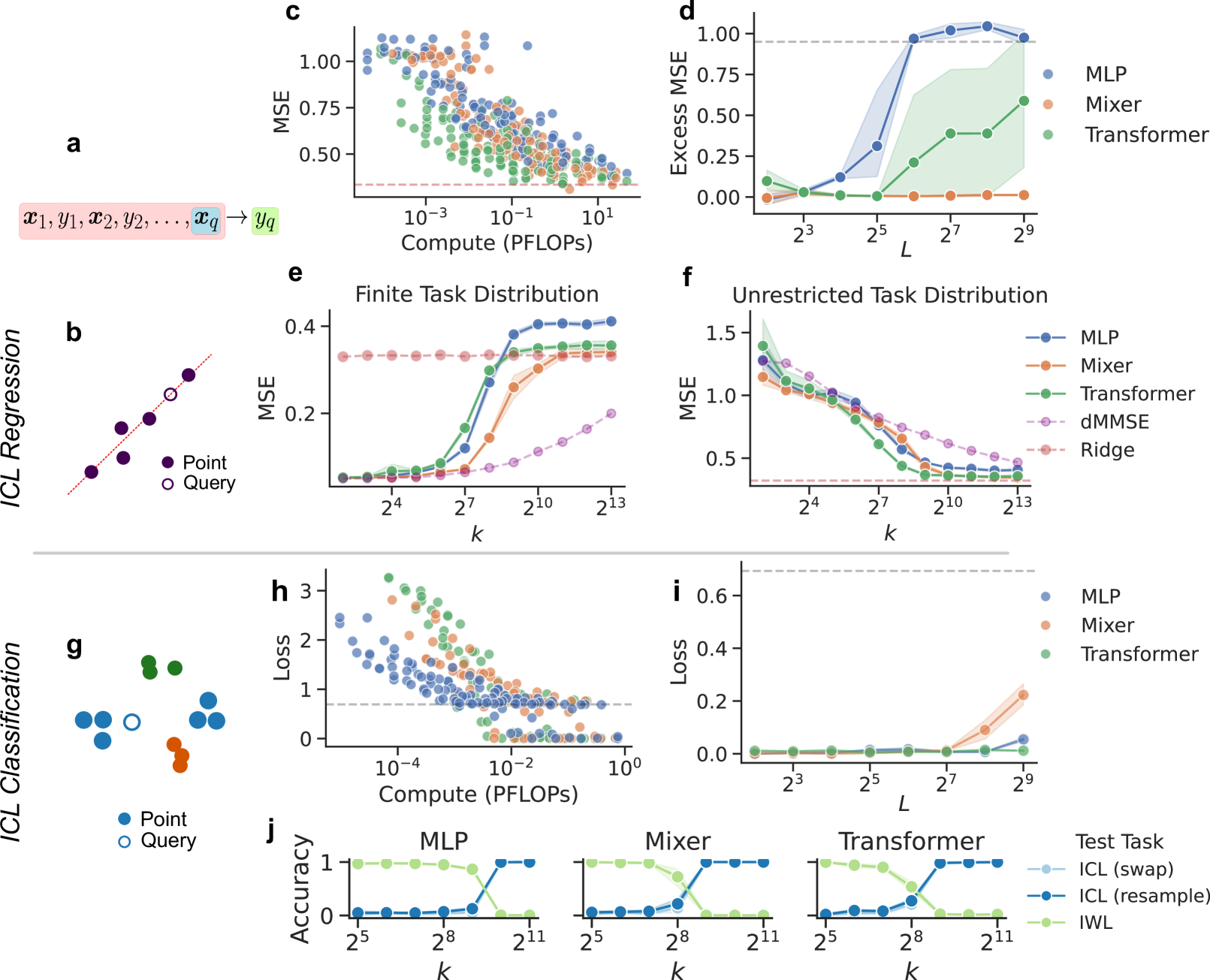
In-context learning (ICL), the remarkable ability to solve a task from only input exemplars, has commonly been assumed to be a unique hallmark of Transformer models. In this study, we demonstrate that multi-layer perceptrons (MLPs) can also learn in-context. Moreover, we find that MLPs, and the closely related MLP-Mixer models, learn in-context competitively with Transformers given the same compute budget. We further show that MLPs outperform Transformers on a subset of ICL tasks designed to test relational reasoning. These results suggest that in-context learning is not exclusive to Transformers and highlight the potential of exploring this phenomenon beyond attention-based architectures. In addition, MLPs' surprising success on relational tasks challenges prior assumptions about simple connectionist models. Altogether, our results endorse the broad trend that ``less inductive bias is better and contribute to the growing interest in all-MLP alternatives to task-specific architectures.
5/27/2024
📊
In-Context Learning through the Bayesian Prism
Madhur Panwar, Kabir Ahuja, Navin Goyal
0
0
In-context learning (ICL) is one of the surprising and useful features of large language models and subject of intense research. Recently, stylized meta-learning-like ICL setups have been devised that train transformers on sequences of input-output pairs $(x, f(x))$. The function $f$ comes from a function class and generalization is checked by evaluating on sequences generated from unseen functions from the same class. One of the main discoveries in this line of research has been that for several function classes, such as linear regression, transformers successfully generalize to new functions in the class. However, the inductive biases of these models resulting in this behavior are not clearly understood. A model with unlimited training data and compute is a Bayesian predictor: it learns the pretraining distribution. In this paper we empirically examine how far this Bayesian perspective can help us understand ICL. To this end, we generalize the previous meta-ICL setup to hierarchical meta-ICL setup which involve unions of multiple task families. We instantiate this setup on a diverse range of linear and nonlinear function families and find that transformers can do ICL in this setting as well. Where Bayesian inference is tractable, we find evidence that high-capacity transformers mimic the Bayesian predictor. The Bayesian perspective provides insights into the inductive bias of ICL and how transformers perform a particular task when they are trained on multiple tasks. We also find that transformers can learn to generalize to new function classes that were not seen during pretraining. This involves deviation from the Bayesian predictor. We examine these deviations in more depth offering new insights and hypotheses.
4/16/2024
🌿
A Survey on In-context Learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, Zhifang Sui
0
0
With the increasing capabilities of large language models (LLMs), in-context learning (ICL) has emerged as a new paradigm for natural language processing (NLP), where LLMs make predictions based on contexts augmented with a few examples. It has been a significant trend to explore ICL to evaluate and extrapolate the ability of LLMs. In this paper, we aim to survey and summarize the progress and challenges of ICL. We first present a formal definition of ICL and clarify its correlation to related studies. Then, we organize and discuss advanced techniques, including training strategies, prompt designing strategies, and related analysis. Additionally, we explore various ICL application scenarios, such as data engineering and knowledge updating. Finally, we address the challenges of ICL and suggest potential directions for further research. We hope that our work can encourage more research on uncovering how ICL works and improving ICL.
6/19/2024
Locally Differentially Private In-Context Learning
Chunyan Zheng, Keke Sun, Wenhao Zhao, Haibo Zhou, Lixin Jiang, Shaoyang Song, Chunlai Zhou
0
0
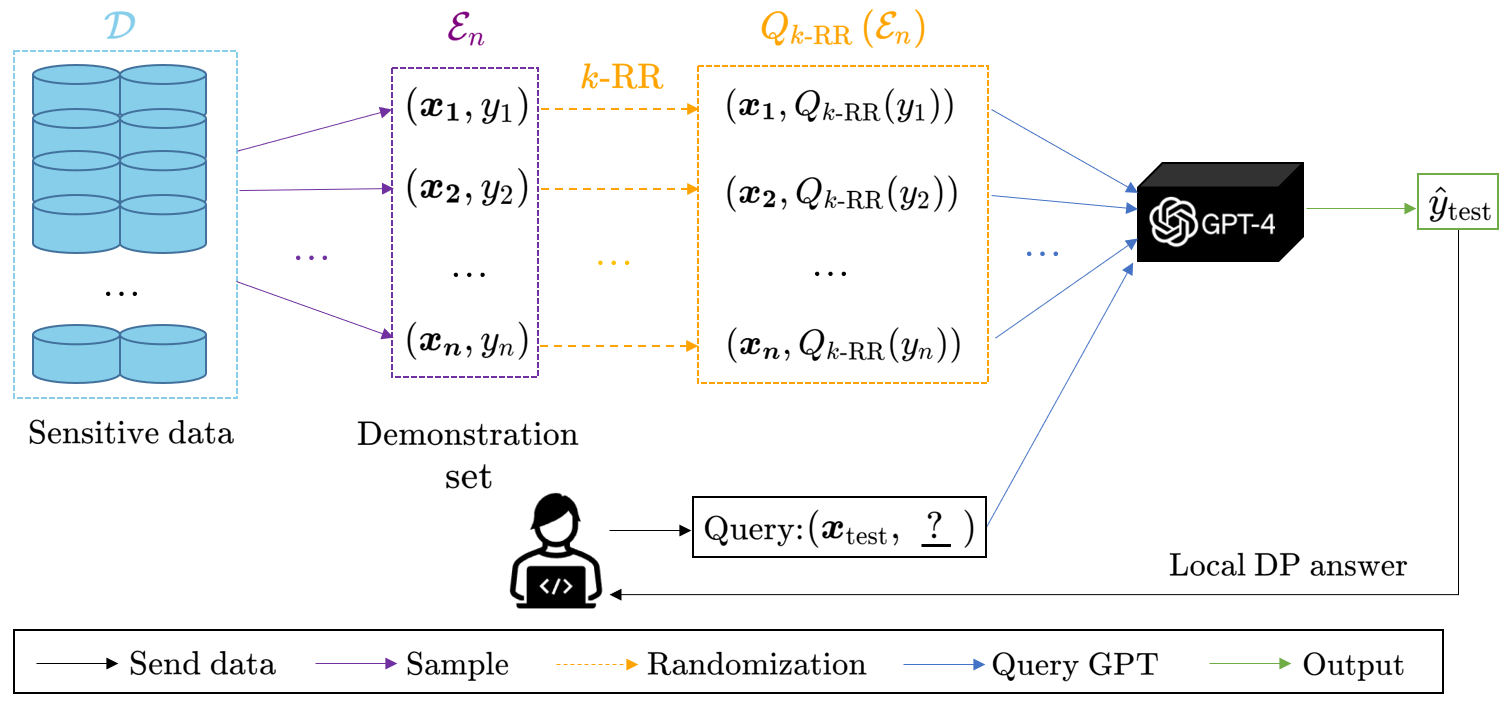
Large pretrained language models (LLMs) have shown surprising In-Context Learning (ICL) ability. An important application in deploying large language models is to augment LLMs with a private database for some specific task. The main problem with this promising commercial use is that LLMs have been shown to memorize their training data and their prompt data are vulnerable to membership inference attacks (MIA) and prompt leaking attacks. In order to deal with this problem, we treat LLMs as untrusted in privacy and propose a locally differentially private framework of in-context learning(LDP-ICL) in the settings where labels are sensitive. Considering the mechanisms of in-context learning in Transformers by gradient descent, we provide an analysis of the trade-off between privacy and utility in such LDP-ICL for classification. Moreover, we apply LDP-ICL to the discrete distribution estimation problem. In the end, we perform several experiments to demonstrate our analysis results.
5/9/2024