MLPs Learn In-Context
2405.15618
0
0
Abstract
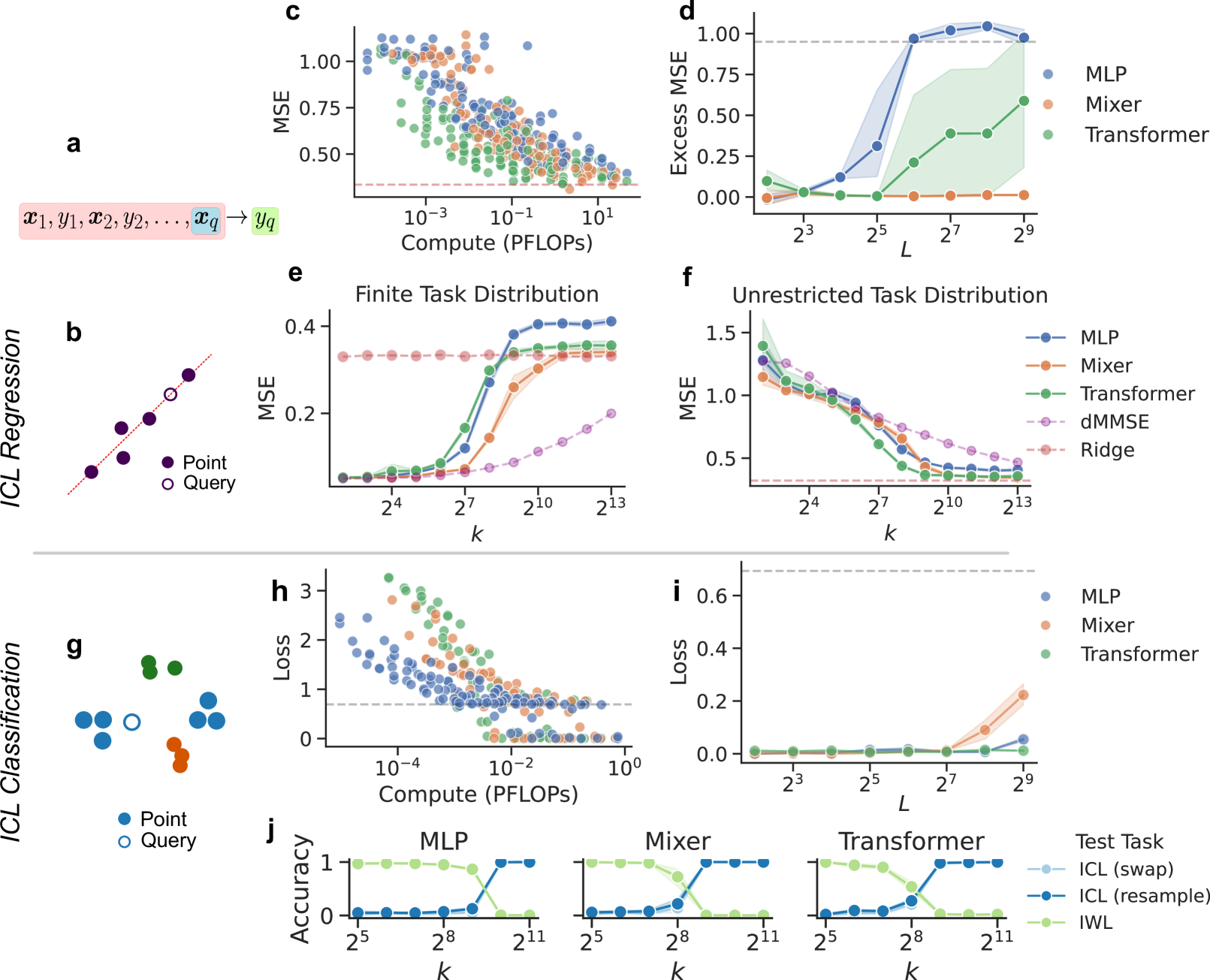
In-context learning (ICL), the remarkable ability to solve a task from only input exemplars, has commonly been assumed to be a unique hallmark of Transformer models. In this study, we demonstrate that multi-layer perceptrons (MLPs) can also learn in-context. Moreover, we find that MLPs, and the closely related MLP-Mixer models, learn in-context competitively with Transformers given the same compute budget. We further show that MLPs outperform Transformers on a subset of ICL tasks designed to test relational reasoning. These results suggest that in-context learning is not exclusive to Transformers and highlight the potential of exploring this phenomenon beyond attention-based architectures. In addition, MLPs' surprising success on relational tasks challenges prior assumptions about simple connectionist models. Altogether, our results endorse the broad trend that ``less inductive bias is better and contribute to the growing interest in all-MLP alternatives to task-specific architectures.
Create account to get full access
Overview
- This paper explores the ability of multilayer perceptrons (MLPs) to learn context-dependent tasks, challenging the prevailing view that MLPs are inherently limited in this regard.
- The researchers design a series of experiments to test the in-context learning capabilities of MLPs, with a focus on tasks that require understanding complex relationships between inputs and outputs.
- The findings suggest that MLPs can indeed learn to exploit contextual information, challenging the assumptions about their limitations and opening up new avenues for their application.
Plain English Explanation
Multilayer perceptrons (MLPs) are a type of artificial neural network that have traditionally been considered limited in their ability to learn context-dependent tasks. This means they struggle to understand how the broader context of a problem can influence the relationship between the inputs and the desired outputs.
However, this research paper presents a compelling challenge to this conventional wisdom. The researchers designed a series of experiments to test the in-context learning capabilities of MLPs, using tasks that require understanding complex relationships between inputs and outputs.
The key idea is that by providing the MLP with additional contextual information, it can learn to exploit that context to improve its performance on the task at hand. For example, imagine a task where the MLP needs to translate text from one language to another. The context could be information about the specific domain or topic of the text, which the MLP can use to inform its translation.
Through their experiments, the researchers found that MLPs are, in fact, capable of learning to use contextual information to improve their performance. This challenges the widely-held belief that MLPs are inherently limited in this regard, and opens up new possibilities for their application in a variety of domains.
Technical Explanation
The researchers designed a series of experiments to test the in-context learning capabilities of multilayer perceptrons (MLPs). They focused on tasks that require understanding complex relationships between inputs and outputs, where the broader context of the problem can influence the desired output.
In one experiment, the researchers trained an MLP to translate text from one language to another, with the additional context of the specific domain or topic of the text. The results showed that the MLP was able to learn to exploit this contextual information to improve its translation performance.
The researchers also tested the MLP's ability to learn context-dependent tasks in other domains, such as image classification and natural language processing. In each case, they found that by providing the MLP with relevant contextual information, it was able to learn to use that context to improve its performance on the task.
These findings challenge the prevailing view that MLPs are inherently limited in their ability to learn context-dependent tasks. The researchers argue that with the right experimental design and the incorporation of contextual information, MLPs can indeed learn to exploit contextual cues to improve their performance.
Critical Analysis
The research presented in this paper makes a compelling case for the ability of multilayer perceptrons (MLPs) to learn in-context tasks, challenging the conventional wisdom that they are inherently limited in this regard. The experimental design is rigorous, and the results are convincing.
However, it is important to note that the researchers focused on a specific set of tasks and contexts. While the findings demonstrate the potential of MLPs to learn context-dependent tasks, it is possible that there may be limitations or challenges in applying this approach to a broader range of real-world problems.
Additionally, the paper does not delve deeply into the underlying mechanisms and principles that allow MLPs to learn in-context tasks. Further research may be needed to fully understand the cognitive and computational processes involved, which could inform the development of more sophisticated MLP architectures and training techniques.
It would also be valuable to see how the performance of MLPs in these context-dependent tasks compares to other neural network architectures, such as transformers or Bayesian models. This could help identify the unique strengths and limitations of MLPs in the context of in-context learning.
Overall, this research represents an important contribution to our understanding of the capabilities of multilayer perceptrons, and opens up new avenues for their application in a variety of domains. However, as with any scientific work, it is important to maintain a critical and open-minded approach, and to continue exploring the boundaries and limitations of these models.
Conclusion
This research paper presents a compelling challenge to the conventional view that multilayer perceptrons (MLPs) are inherently limited in their ability to learn context-dependent tasks. The researchers designed a series of experiments that demonstrate the MLP's capacity to exploit contextual information to improve its performance on a range of tasks, from language translation to image classification.
These findings have significant implications for the field of artificial intelligence, as they suggest that MLPs may be more versatile and adaptable than previously believed. By incorporating contextual information into the training process, MLPs can learn to navigate complex relationships between inputs and outputs, opening up new avenues for their application in a variety of real-world domains.
While there may be limitations and challenges to extending these findings to broader contexts, this research represents an important step forward in our understanding of the capabilities of multilayer perceptrons. As the field of AI continues to evolve, studies like this will be crucial in shaping our perspectives and guiding the development of more powerful and adaptable neural network architectures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
How does Multi-Task Training Affect Transformer In-Context Capabilities? Investigations with Function Classes
Harmon Bhasin, Timothy Ossowski, Yiqiao Zhong, Junjie Hu
0
0
Large language models (LLM) have recently shown the extraordinary ability to perform unseen tasks based on few-shot examples provided as text, also known as in-context learning (ICL). While recent works have attempted to understand the mechanisms driving ICL, few have explored training strategies that incentivize these models to generalize to multiple tasks. Multi-task learning (MTL) for generalist models is a promising direction that offers transfer learning potential, enabling large parameterized models to be trained from simpler, related tasks. In this work, we investigate the combination of MTL with ICL to build models that efficiently learn tasks while being robust to out-of-distribution examples. We propose several effective curriculum learning strategies that allow ICL models to achieve higher data efficiency and more stable convergence. Our experiments reveal that ICL models can effectively learn difficult tasks by training on progressively harder tasks while mixing in prior tasks, denoted as mixed curriculum in this work. Our code and models are available at https://github.com/harmonbhasin/curriculum_learning_icl .
4/5/2024
📉
How Do Nonlinear Transformers Learn and Generalize in In-Context Learning?
Hongkang Li, Meng Wang, Songtao Lu, Xiaodong Cui, Pin-Yu Chen
0
0
Transformer-based large language models have displayed impressive in-context learning capabilities, where a pre-trained model can handle new tasks without fine-tuning by simply augmenting the query with some input-output examples from that task. Despite the empirical success, the mechanics of how to train a Transformer to achieve ICL and the corresponding ICL capacity is mostly elusive due to the technical challenges of analyzing the nonconvex training problems resulting from the nonlinear self-attention and nonlinear activation in Transformers. To the best of our knowledge, this paper provides the first theoretical analysis of the training dynamics of Transformers with nonlinear self-attention and nonlinear MLP, together with the ICL generalization capability of the resulting model. Focusing on a group of binary classification tasks, we train Transformers using data from a subset of these tasks and quantify the impact of various factors on the ICL generalization performance on the remaining unseen tasks with and without data distribution shifts. We also analyze how different components in the learned Transformers contribute to the ICL performance. Furthermore, we provide the first theoretical analysis of how model pruning affects ICL performance and prove that proper magnitude-based pruning can have a minimal impact on ICL while reducing inference costs. These theoretical findings are justified through numerical experiments.
6/18/2024

Why Larger Language Models Do In-context Learning Differently?
Zhenmei Shi, Junyi Wei, Zhuoyan Xu, Yingyu Liang
0
0
Large language models (LLM) have emerged as a powerful tool for AI, with the key ability of in-context learning (ICL), where they can perform well on unseen tasks based on a brief series of task examples without necessitating any adjustments to the model parameters. One recent interesting mysterious observation is that models of different scales may have different ICL behaviors: larger models tend to be more sensitive to noise in the test context. This work studies this observation theoretically aiming to improve the understanding of LLM and ICL. We analyze two stylized settings: (1) linear regression with one-layer single-head linear transformers and (2) parity classification with two-layer multiple attention heads transformers (non-linear data and non-linear model). In both settings, we give closed-form optimal solutions and find that smaller models emphasize important hidden features while larger ones cover more hidden features; thus, smaller models are more robust to noise while larger ones are more easily distracted, leading to different ICL behaviors. This sheds light on where transformers pay attention to and how that affects ICL. Preliminary experimental results on large base and chat models provide positive support for our analysis.
5/31/2024
📊
In-Context Learning through the Bayesian Prism
Madhur Panwar, Kabir Ahuja, Navin Goyal
0
0
In-context learning (ICL) is one of the surprising and useful features of large language models and subject of intense research. Recently, stylized meta-learning-like ICL setups have been devised that train transformers on sequences of input-output pairs $(x, f(x))$. The function $f$ comes from a function class and generalization is checked by evaluating on sequences generated from unseen functions from the same class. One of the main discoveries in this line of research has been that for several function classes, such as linear regression, transformers successfully generalize to new functions in the class. However, the inductive biases of these models resulting in this behavior are not clearly understood. A model with unlimited training data and compute is a Bayesian predictor: it learns the pretraining distribution. In this paper we empirically examine how far this Bayesian perspective can help us understand ICL. To this end, we generalize the previous meta-ICL setup to hierarchical meta-ICL setup which involve unions of multiple task families. We instantiate this setup on a diverse range of linear and nonlinear function families and find that transformers can do ICL in this setting as well. Where Bayesian inference is tractable, we find evidence that high-capacity transformers mimic the Bayesian predictor. The Bayesian perspective provides insights into the inductive bias of ICL and how transformers perform a particular task when they are trained on multiple tasks. We also find that transformers can learn to generalize to new function classes that were not seen during pretraining. This involves deviation from the Bayesian predictor. We examine these deviations in more depth offering new insights and hypotheses.
4/16/2024