Context Propagation from Proposals for Semantic Video Object Segmentation

0

Sign in to get full access
Overview
- This paper proposes a novel approach for semantic video object segmentation, which involves propagating context information from object proposals to improve the quality of segmentation.
- The method leverages the complementary strengths of object proposals and context propagation to achieve better performance compared to existing techniques.
- The approach is evaluated on standard benchmarks and demonstrates state-of-the-art results, highlighting its effectiveness in video object segmentation.
Plain English Explanation
The paper introduces a new method for semantic video object segmentation, which is the task of identifying and delineating the boundaries of objects in a video sequence and classifying them into semantic categories (e.g., car, person, dog). The key innovation of this work is the idea of propagating context information from initial object proposals to refine the final segmentation.
Typically, video object segmentation involves two main steps: first, generating a set of object proposals that identify potential objects in each frame, and second, classifying and refining these proposals to produce the final segmentation. The authors of this paper recognized that the object proposals and the context information they provide can be leveraged more effectively to improve the overall segmentation quality.
Their approach works by taking the initial object proposals and using a context propagation mechanism to spread relevant contextual cues (e.g., the appearance and motion of neighboring objects) across the video frames. This allows the system to better understand the relationships between objects and their surroundings, leading to more accurate and coherent segmentations.
By combining the strengths of object proposals and context propagation, the proposed method outperforms previous state-of-the-art techniques on standard benchmarks for video object segmentation. This research advances the field by demonstrating the value of integrating multiple sources of information to tackle this challenging computer vision problem.
Technical Explanation
The paper presents a novel approach for semantic video object segmentation that leverages the complementary strengths of object proposals and context propagation.
The method consists of two main components:
-
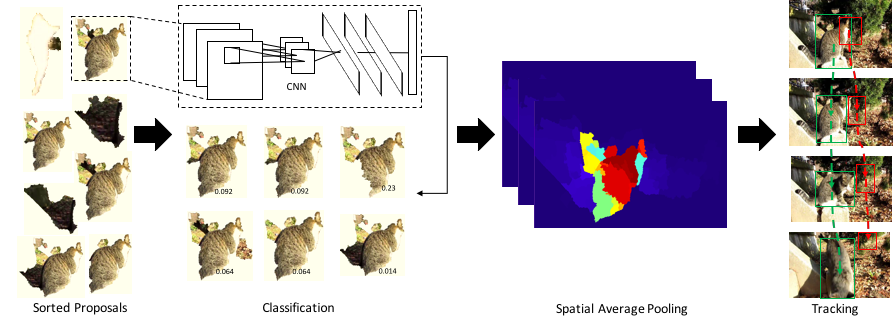
Object Proposal Generation: The authors first generate a set of object proposals for each frame of the video using a non-parametric contextual relationship learning approach. This produces a collection of bounding boxes that potentially contain objects of interest.
-
Context Propagation: To refine the object proposals, the authors introduce a context propagation mechanism that propagates relevant contextual information (e.g., appearance, motion) across the video frames. This allows the system to better understand the relationships between objects and their surroundings, leading to more accurate segmentations.
The context propagation is guided by a vanishing point-based spatial-temporal association module, which captures the long-range dependencies between objects and their contexts.
The proposed method is evaluated on standard benchmarks for video object segmentation, demonstrating state-of-the-art performance. The authors attribute the success of their approach to the effective integration of object proposals and context propagation, which enables the system to leverage both local and global cues to produce high-quality semantic segmentations.
Critical Analysis
The paper presents a compelling approach to video object segmentation that leverages the synergies between object proposals and context propagation. The authors provide a thorough evaluation of their method on standard benchmarks, demonstrating its effectiveness compared to existing techniques.
One potential limitation of the approach is its reliance on accurate object proposals, which can be challenging to obtain, especially for small or occluded objects. The authors acknowledge this and suggest that further research into learning object semantic similarity could help address this issue.
Additionally, the paper does not provide a detailed analysis of the computational complexity or inference time of the proposed method, which could be an important consideration for real-world applications. Further investigation into the trade-offs between performance and efficiency would help understand the practical implications of the approach.
Overall, the paper makes a valuable contribution to the field of video object segmentation by demonstrating the power of combining complementary techniques. The authors' insights on the benefits of context propagation and the integration of object proposals are worthy of further exploration and refinement.
Conclusion
This paper presents a novel approach for semantic video object segmentation that leverages the strengths of object proposals and context propagation. By effectively integrating these two key components, the authors have developed a method that achieves state-of-the-art performance on standard benchmarks.
The proposed context propagation mechanism, guided by spatial-temporal associations, allows the system to better understand the relationships between objects and their surroundings, leading to more accurate and coherent segmentations. This research advances the field of video object segmentation and demonstrates the value of combining multiple sources of information to tackle complex computer vision problems.
While the approach shows promising results, further research is needed to address potential limitations, such as the reliance on accurate object proposals and the computational efficiency of the method. Nonetheless, this work provides a compelling example of how innovative algorithmic designs can push the boundaries of what is possible in semantic video understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Context Propagation from Proposals for Semantic Video Object Segmentation
Tinghuai Wang
In this paper, we propose a novel approach to learning semantic contextual relationships in videos for semantic object segmentation. Our algorithm derives the semantic contexts from video object proposals which encode the key evolution of objects and the relationship among objects over the spatio-temporal domain. This semantic contexts are propagated across the video to estimate the pairwise contexts between all pairs of local superpixels which are integrated into a conditional random field in the form of pairwise potentials and infers the per-superpixel semantic labels. The experiments demonstrate that our contexts learning and propagation model effectively improves the robustness of resolving visual ambiguities in semantic video object segmentation compared with the state-of-the-art methods.
Read more7/10/2024

0
Non-parametric Contextual Relationship Learning for Semantic Video Object Segmentation
Tinghuai Wang, Huiling Wang
We propose a novel approach for modeling semantic contextual relationships in videos. This graph-based model enables the learning and propagation of higher-level spatial-temporal contexts to facilitate the semantic labeling of local regions. We introduce an exemplar-based nonparametric view of contextual cues, where the inherent relationships implied by object hypotheses are encoded on a similarity graph of regions. Contextual relationships learning and propagation are performed to estimate the pairwise contexts between all pairs of unlabeled local regions. Our algorithm integrates the learned contexts into a Conditional Random Field (CRF) in the form of pairwise potentials and infers the per-region semantic labels. We evaluate our approach on the challenging YouTube-Objects dataset which shows that the proposed contextual relationship model outperforms the state-of-the-art methods.
Read more7/9/2024
0
Submodular video object proposal selection for semantic object segmentation
Tinghuai Wang
Learning a data-driven spatio-temporal semantic representation of the objects is the key to coherent and consistent labelling in video. This paper proposes to achieve semantic video object segmentation by learning a data-driven representation which captures the synergy of multiple instances from continuous frames. To prune the noisy detections, we exploit the rich information among multiple instances and select the discriminative and representative subset. This selection process is formulated as a facility location problem solved by maximising a submodular function. Our method retrieves the longer term contextual dependencies which underpins a robust semantic video object segmentation algorithm. We present extensive experiments on a challenging dataset that demonstrate the superior performance of our approach compared with the state-of-the-art methods.
Read more7/9/2024

0
Context-Aware Temporal Embedding of Objects in Video Data
Ahnaf Farhan, M. Shahriar Hossain
In video analysis, understanding the temporal context is crucial for recognizing object interactions, event patterns, and contextual changes over time. The proposed model leverages adjacency and semantic similarities between objects from neighboring video frames to construct context-aware temporal object embeddings. Unlike traditional methods that rely solely on visual appearance, our temporal embedding model considers the contextual relationships between objects, creating a meaningful embedding space where temporally connected object's vectors are positioned in proximity. Empirical studies demonstrate that our context-aware temporal embeddings can be used in conjunction with conventional visual embeddings to enhance the effectiveness of downstream applications. Moreover, the embeddings can be used to narrate a video using a Large Language Model (LLM). This paper describes the intricate details of the proposed objective function to generate context-aware temporal object embeddings for video data and showcases the potential applications of the generated embeddings in video analysis and object classification tasks.
Read more8/26/2024