Contextrast: Contextual Contrastive Learning for Semantic Segmentation

0

Sign in to get full access
Overview
- The paper proposes a novel method called "Contextrast" for semantic segmentation, which combines contextual information and contrastive learning.
- Semantic segmentation is the task of assigning a semantic label to each pixel in an image, which is an important computer vision problem with many applications.
- Contextrast aims to learn more discriminative visual representations by taking into account the relationships between nearby pixels and their semantic context.
Plain English Explanation
The paper introduces a new technique called "Contextrast" for semantic segmentation. Semantic segmentation is the process of analyzing an image and assigning a category label (like "car," "tree," or "person") to every single pixel. This is a fundamental task in computer vision with many real-world applications, like self-driving cars, medical image analysis, and image editing.
The key insight behind Contextrast is that the meaning of a pixel doesn't just depend on its own visual features, but also on the context provided by the surrounding pixels. For example, if you see a small brown shape in an image, it could be a tree trunk, a wooden post, or a animal's leg - the surrounding pixels give crucial information to determine the right semantic label.
Contextrast tries to capture this contextual information by training the model to not just recognize individual pixels, but also understand how they relate to their neighbors. It does this through a contrastive learning approach, where the model has to distinguish between semantically similar and dissimilar pixel neighborhoods.
The authors show that this contextual contrastive learning leads to more powerful visual representations that boost the performance of semantic segmentation models, achieving state-of-the-art results on several benchmark datasets. The technique is general and could potentially be applied to other computer vision tasks that benefit from understanding the relationships between different image regions.
Technical Explanation
The key technical contribution of the paper is the Contextrast framework, which incorporates contextual information into contrastive learning for semantic segmentation. The authors observe that existing contrastive learning approaches for segmentation often focus narrowly on the visual features of individual pixels, without considering the semantic relationships between neighboring regions.
To address this, Contextrast defines a contrastive objective that encourages the model to learn pixel-level representations that are not just visually similar, but also semantically coherent within a local neighborhood. Specifically, for each pixel, Contextrast samples a "positive" neighborhood containing semantically related pixels, and a set of "negative" neighborhoods containing dissimilar pixels. The model is then trained to maximize the similarity between the representation of the positive neighborhood and minimize the similarity to the negative neighborhoods.
The authors demonstrate the effectiveness of this approach through extensive experiments on several popular semantic segmentation benchmarks, including Cityscapes, ADE20K, and Pascal VOC. Contextrast outperforms previous state-of-the-art methods by a significant margin, showcasing the benefits of incorporating contextual information through contrastive learning.
Additionally, the paper provides detailed ablation studies to analyze the contributions of different components of the Contextrast framework. For example, the authors evaluate the impact of the neighborhood size, the relative weighting of local and global contrastive losses, and the use of different sampling strategies for positive and negative examples.
Critical Analysis
The Contextrast paper makes a compelling case for the importance of contextual information in semantic segmentation and presents a novel contrastive learning approach to capture this context. The experimental results demonstrate the effectiveness of the method and suggest that it could be a promising direction for further research.
That said, the paper does not address some potential limitations and avenues for future work. For instance, the authors do not explore how Contextrast might perform on more challenging or diverse datasets, such as those with significant occlusions, unusual perspectives, or a wider variety of object categories. Additionally, the computational complexity of the contrastive learning objective could be a concern, especially for real-time applications.
Another area for further investigation is the interpretability of the learned representations. While the paper shows that Contextrast improves segmentation performance, it would be valuable to understand how the model is leveraging contextual information and which types of contextual cues are most important for different scenarios.
Despite these minor limitations, the Contextrast paper represents an important contribution to the field of semantic segmentation and contrastive learning. By demonstrating the benefits of incorporating contextual information, the authors have opened up new avenues for research and practical applications in computer vision.
Conclusion
The Contextrast paper presents a novel approach to semantic segmentation that combines contextual information and contrastive learning. By training the model to recognize not just individual pixels, but also their relationships to neighboring regions, Contextrast is able to learn more discriminative visual representations that lead to state-of-the-art segmentation performance.
The key insight of the paper is that the meaning of a pixel depends not only on its own visual features, but also on the semantic context provided by the surrounding pixels. Contextrast leverages this intuition through a contrastive learning objective that encourages the model to distinguish between semantically similar and dissimilar pixel neighborhoods.
The impressive results of Contextrast on several benchmark datasets suggest that this approach could have a significant impact on a wide range of computer vision applications, from autonomous driving to medical image analysis. By highlighting the importance of contextual information, the paper also opens up new directions for multi-scale and multi-modal contrastive learning techniques in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Contextrast: Contextual Contrastive Learning for Semantic Segmentation
Changki Sung, Wanhee Kim, Jungho An, Wooju Lee, Hyungtae Lim, Hyun Myung
Despite great improvements in semantic segmentation, challenges persist because of the lack of local/global contexts and the relationship between them. In this paper, we propose Contextrast, a contrastive learning-based semantic segmentation method that allows to capture local/global contexts and comprehend their relationships. Our proposed method comprises two parts: a) contextual contrastive learning (CCL) and b) boundary-aware negative (BANE) sampling. Contextual contrastive learning obtains local/global context from multi-scale feature aggregation and inter/intra-relationship of features for better discrimination capabilities. Meanwhile, BANE sampling selects embedding features along the boundaries of incorrectly predicted regions to employ them as harder negative samples on our contrastive learning, resolving segmentation issues along the boundary region by exploiting fine-grained details. We demonstrate that our Contextrast substantially enhances the performance of semantic segmentation networks, outperforming state-of-the-art contrastive learning approaches on diverse public datasets, e.g. Cityscapes, CamVid, PASCAL-C, COCO-Stuff, and ADE20K, without an increase in computational cost during inference.
Read more4/17/2024

0
Contrastive Learning Subspace for Text Clustering
Qian Yong, Chen Chen, Xiabing Zhou
Contrastive learning has been frequently investigated to learn effective representations for text clustering tasks. While existing contrastive learning-based text clustering methods only focus on modeling instance-wise semantic similarity relationships, they ignore contextual information and underlying relationships among all instances that needs to be clustered. In this paper, we propose a novel text clustering approach called Subspace Contrastive Learning (SCL) which models cluster-wise relationships among instances. Specifically, the proposed SCL consists of two main modules: (1) a self-expressive module that constructs virtual positive samples and (2) a contrastive learning module that further learns a discriminative subspace to capture task-specific cluster-wise relationships among texts. Experimental results show that the proposed SCL method not only has achieved superior results on multiple task clustering datasets but also has less complexity in positive sample construction.
Read more8/27/2024

0
Weakly-supervised Semantic Segmentation via Dual-stream Contrastive Learning of Cross-image Contextual Information
Qi Lai, Chi-Man Vong
Weakly supervised semantic segmentation (WSSS) aims at learning a semantic segmentation model with only image-level tags. Despite intensive research on deep learning approaches over a decade, there is still a significant performance gap between WSSS and full semantic segmentation. Most current WSSS methods always focus on a limited single image (pixel-wise) information while ignoring the valuable inter-image (semantic-wise) information. From this perspective, a novel end-to-end WSSS framework called DSCNet is developed along with two innovations: i) pixel-wise group contrast and semantic-wise graph contrast are proposed and introduced into the WSSS framework; ii) a novel dual-stream contrastive learning (DSCL) mechanism is designed to jointly handle pixel-wise and semantic-wise context information for better WSSS performance. Specifically, the pixel-wise group contrast learning (PGCL) and semantic-wise graph contrast learning (SGCL) tasks form a more comprehensive solution. Extensive experiments on PASCAL VOC and MS COCO benchmarks verify the superiority of DSCNet over SOTA approaches and baseline models.
Read more5/9/2024
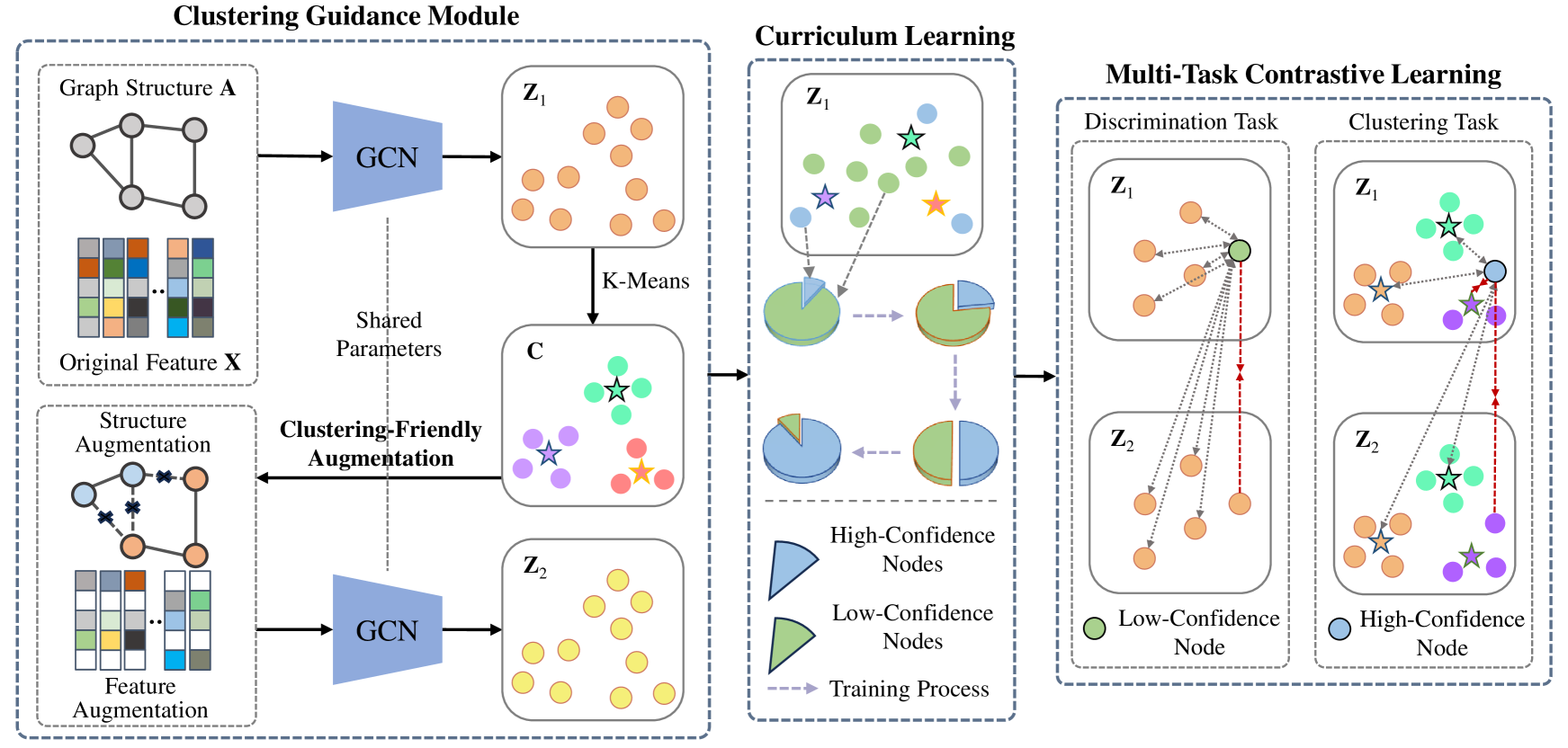
0
Multi-Task Curriculum Graph Contrastive Learning with Clustering Entropy Guidance
Chusheng Zeng, Bocheng Wang, Jinghui Yuan, Rong Wang, Mulin Chen
Recent advances in unsupervised deep graph clustering have been significantly promoted by contrastive learning. Despite the strides, most graph contrastive learning models face challenges: 1) graph augmentation is used to improve learning diversity, but commonly used random augmentation methods may destroy inherent semantics and cause noise; 2) the fixed positive and negative sample selection strategy is limited to deal with complex real data, thereby impeding the model's capability to capture fine-grained patterns and relationships. To reduce these problems, we propose the Clustering-guided Curriculum Graph contrastive Learning (CCGL) framework. CCGL uses clustering entropy as the guidance of the following graph augmentation and contrastive learning. Specifically, according to the clustering entropy, the intra-class edges and important features are emphasized in augmentation. Then, a multi-task curriculum learning scheme is proposed, which employs the clustering guidance to shift the focus from the discrimination task to the clustering task. In this way, the sample selection strategy of contrastive learning can be adjusted adaptively from early to late stage, which enhances the model's flexibility for complex data structure. Experimental results demonstrate that CCGL has achieved excellent performance compared to state-of-the-art competitors.
Read more8/23/2024