Customizing Language Model Responses with Contrastive In-Context Learning
2401.17390
0
1

Abstract
Large language models (LLMs) are becoming increasingly important for machine learning applications. However, it can be challenging to align LLMs with our intent, particularly when we want to generate content that is preferable over others or when we want the LLM to respond in a certain style or tone that is hard to describe. To address this challenge, we propose an approach that uses contrastive examples to better describe our intent. This involves providing positive examples that illustrate the true intent, along with negative examples that show what characteristics we want LLMs to avoid. The negative examples can be retrieved from labeled data, written by a human, or generated by the LLM itself. Before generating an answer, we ask the model to analyze the examples to teach itself what to avoid. This reasoning step provides the model with the appropriate articulation of the user's need and guides it towards generting a better answer. We tested our approach on both synthesized and real-world datasets, including StackExchange and Reddit, and found that it significantly improves performance compared to standard few-shot prompting
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces a new training approach called "Contrastive In-Context Learning" (CICl) for customizing the responses of large language models.
- The key idea is to fine-tune the language model using contrasting examples that guide the model to generate desired responses in specific contexts.
- The authors demonstrate the effectiveness of CICL on several tasks, including topic-guided response generation, factual consistency, and structured information generation.
Plain English Explanation
Imagine you have a very capable language model that can write coherent text on almost any topic. However, sometimes its responses don't quite match what you're looking for - they may not have the right tone, focus on the wrong details, or fail to convey certain information. The Contrastive In-Context Learning approach aims to "customize" the language model's responses to better suit your needs.
The key insight is that by showing the model pairs of examples - one that matches your desired output and one that doesn't - you can guide the model to generate more relevant and targeted responses. For example, if you want the model to write product descriptions with a more enthusiastic tone, you could provide positive and neutral descriptions as contrast examples during training.
This fine-tuning process helps the model learn what kinds of responses are preferred in specific contexts, allowing it to adapt its outputs accordingly. The authors demonstrate this technique improving performance on tasks like generating topic-focused text, ensuring factual consistency, and producing structured information - areas where standard language models sometimes struggle.
The beauty of this approach is that it allows you to mold the language model's behavior without having to completely retrain it from scratch. By harnessing the power of contrast, you can nudge the model to behave in ways that better align with your needs and preferences.
Technical Explanation
The core of the Contrastive In-Context Learning (CICL) approach is the use of contrasting examples to fine-tune a pre-trained language model. During this fine-tuning process, the model is presented with pairs of input-output examples - one that represents the desired behavior, and one that does not.
For example, in the topic-guided response generation task, the model might see a prompt about "sustainability" paired with both a relevant, on-topic response and an irrelevant, off-topic response. By learning to distinguish these contrasting examples, the model gradually calibrates its behavior to generate more topically-focused outputs.
The authors apply this CICL approach to several other tasks, including factual consistency and structured information generation. In each case, the key is identifying the critical dimensions along which the model's behavior should be adjusted and then crafting appropriate contrasting examples to guide the fine-tuning process.
The experiments demonstrate that CICL is an effective way to customize language model responses, outperforming standard fine-tuning approaches on a range of metrics. By leveraging the model's ability to learn from contrastive signals, the researchers are able to steer the model's outputs in more desirable directions without having to radically change the underlying architecture.
Critical Analysis
The Contrastive In-Context Learning approach presented in this paper is a clever and promising technique for customizing language model behavior. By using contrasting examples, the authors are able to guide the model towards more targeted and relevant responses, addressing some of the limitations of standard language models.
That said, the paper does not fully explore the limits of this approach. For instance, it's unclear how well CICL would scale to more complex or open-ended tasks, where defining appropriate contrasting examples may be challenging. The authors also don't delve deeply into the model's internal reasoning or the extent to which the fine-tuned behavior is truly "understood" versus simply memorized.
Additionally, the paper does not address potential ethical concerns around the use of such customization techniques. If not implemented carefully, CICL could potentially be used to reinforce biases or generate misleading outputs tailored to specific agendas. Further research is needed to understand the societal implications of this approach.
Overall, the Contrastive In-Context Learning method represents an intriguing step forward in language model customization. By combining the power of large language models with targeted fine-tuning, the authors have demonstrated a way to better align model behavior with user needs and preferences. However, as with any powerful AI technique, it will be important to explore the approach's limitations and potential pitfalls as the research continues.
Conclusion
The Contrastive In-Context Learning (CICL) method introduced in this paper offers a novel approach to customizing the responses of large language models. By leveraging contrasting examples during fine-tuning, the authors show how language models can be guided to generate more targeted and relevant outputs across a range of tasks.
This work represents an important advancement in the field of language model customization, addressing some of the limitations of standard fine-tuning techniques. The ability to steer model behavior without requiring a complete model rebuild could have significant implications for real-world applications, from customer service chatbots to content generation tools.
As the research in this area continues to evolve, it will be crucial to carefully evaluate the potential societal impacts and ethical considerations of such customization approaches. However, the core insights of CICL – using contrastive signals to shape model behavior – demonstrate the power of creative fine-tuning techniques to unlock the full potential of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
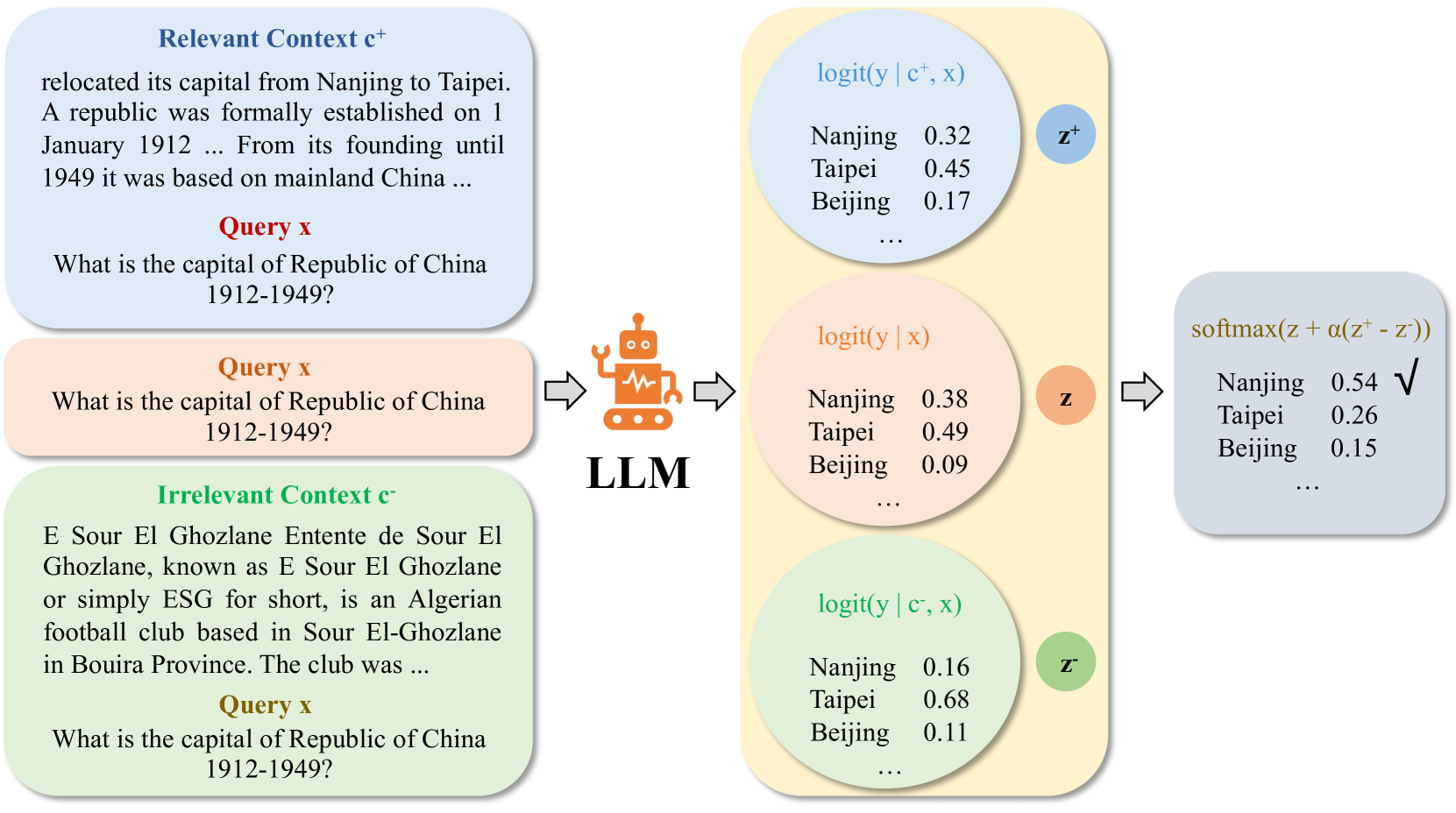
Enhancing Contextual Understanding in Large Language Models through Contrastive Decoding
Zheng Zhao, Emilio Monti, Jens Lehmann, Haytham Assem
0
0
Large language models (LLMs) tend to inadequately integrate input context during text generation, relying excessively on encoded prior knowledge in model parameters, potentially resulting in generated text with factual inconsistencies or contextually unfaithful content. LLMs utilize two primary knowledge sources: 1) prior (parametric) knowledge from pretraining, and 2) contextual (non-parametric) knowledge from input prompts. The study addresses the open question of how LLMs effectively balance these knowledge sources during the generation process, specifically in the context of open-domain question answering. To address this issue, we introduce a novel approach integrating contrastive decoding with adversarial irrelevant passages as negative samples to enhance robust context grounding during generation. Notably, our method operates at inference time without requiring further training. We conduct comprehensive experiments to demonstrate its applicability and effectiveness, providing empirical evidence showcasing its superiority over existing methodologies. Our code is publicly available at: https://github.com/amazon-science/ContextualUnderstanding-ContrastiveDecoding.
5/7/2024
💬
Evaluating Large Language Models Using Contrast Sets: An Experimental Approach
Manish Sanwal
0
0
In the domain of Natural Language Inference (NLI), especially in tasks involving the classification of multiple input texts, the Cross-Entropy Loss metric is widely employed as a standard for error measurement. However, this metric falls short in effectively evaluating a model's capacity to understand language entailments. In this study, we introduce an innovative technique for generating a contrast set for the Stanford Natural Language Inference (SNLI) dataset. Our strategy involves the automated substitution of verbs, adverbs, and adjectives with their synonyms to preserve the original meaning of sentences. This method aims to assess whether a model's performance is based on genuine language comprehension or simply on pattern recognition. We conducted our analysis using the ELECTRA-small model. The model achieved an accuracy of 89.9% on the conventional SNLI dataset but showed a reduced accuracy of 72.5% on our contrast set, indicating a substantial 17% decline. This outcome led us to conduct a detailed examination of the model's learning behaviors. Following this, we improved the model's resilience by fine-tuning it with a contrast-enhanced training dataset specifically designed for SNLI, which increased its accuracy to 85.5% on the contrast sets. Our findings highlight the importance of incorporating diverse linguistic expressions into datasets for NLI tasks. We hope that our research will encourage the creation of more inclusive datasets, thereby contributing to the development of NLI models that are both more sophisticated and effective.
4/3/2024

Supervised Knowledge Makes Large Language Models Better In-context Learners
Linyi Yang, Shuibai Zhang, Zhuohao Yu, Guangsheng Bao, Yidong Wang, Jindong Wang, Ruochen Xu, Wei Ye, Xing Xie, Weizhu Chen, Yue Zhang
0
0
Large Language Models (LLMs) exhibit emerging in-context learning abilities through prompt engineering. The recent progress in large-scale generative models has further expanded their use in real-world language applications. However, the critical challenge of improving the generalizability and factuality of LLMs in natural language understanding and question answering remains under-explored. While previous in-context learning research has focused on enhancing models to adhere to users' specific instructions and quality expectations, and to avoid undesired outputs, little to no work has explored the use of task-Specific fine-tuned Language Models (SLMs) to improve LLMs' in-context learning during the inference stage. Our primary contribution is the establishment of a simple yet effective framework that enhances the reliability of LLMs as it: 1) generalizes out-of-distribution data, 2) elucidates how LLMs benefit from discriminative models, and 3) minimizes hallucinations in generative tasks. Using our proposed plug-in method, enhanced versions of Llama 2 and ChatGPT surpass their original versions regarding generalizability and factuality. We offer a comprehensive suite of resources, including 16 curated datasets, prompts, model checkpoints, and LLM outputs across 9 distinct tasks. The code and data are released at: https://github.com/YangLinyi/Supervised-Knowledge-Makes-Large-Language-Models-Better-In-context-Learners. Our empirical analysis sheds light on the advantages of incorporating discriminative models into LLMs and highlights the potential of our methodology in fostering more reliable LLMs.
4/12/2024
🛸
Improving Diversity of Commonsense Generation by Large Language Models via In-Context Learning
Tianhui Zhang, Bei Peng, Danushka Bollegala
0
0
Generative Commonsense Reasoning (GCR) requires a model to reason about a situation using commonsense knowledge, while generating coherent sentences. Although the quality of the generated sentences is crucial, the diversity of the generation is equally important because it reflects the model's ability to use a range of commonsense knowledge facts. Large Language Models (LLMs) have shown proficiency in enhancing the generation quality across various tasks through in-context learning (ICL) using given examples without the need for any fine-tuning. However, the diversity aspect in LLM outputs has not been systematically studied before. To address this, we propose a simple method that diversifies the LLM generations, while preserving their quality. Experimental results on three benchmark GCR datasets show that our method achieves an ideal balance between the quality and diversity. Moreover, the sentences generated by our proposed method can be used as training data to improve diversity in existing commonsense generators.
4/26/2024