Contextual Hourglass Network for Semantic Segmentation of High Resolution Aerial Imagery

0
🌐
Sign in to get full access
Overview
- Semantic segmentation for aerial imagery is a challenging and important problem in remote sensing analysis
- Deep learning-based convolutional neural network (CNN) models have been developed to address this problem
- However, challenges remain due to varying object sizes and imbalanced class labels
- The researchers propose a novel method called Contextual Hourglass Network to improve pixel-wise semantic segmentation
Plain English Explanation
The researchers are working on a computer vision problem called semantic segmentation for aerial imagery. This means they want to analyze aerial photos (like from satellites or drones) and identify all the different objects and regions in the image, like buildings, roads, trees, etc. This is an important task for applications like urban planning, agriculture, and disaster response.
Recent advances in deep learning have led to the development of various CNN-based models for this problem. However, there are still some challenges. The sizes of the objects in aerial images can vary a lot, and there are often more of some types of objects than others. This can make it hard for the models to accurately identify all the different elements in the image.
To address these challenges, the researchers developed a new method called the Contextual Hourglass Network. The key idea is to incorporate an "attention mechanism" into the model, which helps it focus on the most relevant contextual information when making predictions. They also use a "stacked encoder-decoder" architecture to extract rich multi-scale features and add more feedback loops for better learning of the contextual semantics.
By testing their Contextual Hourglass Network on standard aerial image datasets, the researchers showed that it outperforms other baseline methods in terms of overall performance on the semantic segmentation task.
Technical Explanation
The researchers developed a novel semantic segmentation method called the Contextual Hourglass Network to address the challenges of varying object sizes and imbalanced class labels in aerial imagery analysis.
At the core of their approach is a new "contextual hourglass module" that incorporates an attention mechanism to process low-resolution feature maps and exploit the contextual semantics. This module is then stacked in an end-to-end encoder-decoder structure, where multiple contextual hourglass modules are connected to effectively extract rich multi-scale features and add more feedback loops for better learning of the contextual information through intermediate supervision.
To demonstrate the effectiveness of their Contextual Hourglass Network, the researchers evaluated it on the Potsdam and Vaihingen datasets, which are standard benchmarks for semantic segmentation of aerial imagery. Their method outperformed other baseline techniques in terms of overall performance on the task.
Critical Analysis
The researchers acknowledge that their Contextual Hourglass Network, while showing promising results, still has some limitations. For example, they note that the attention mechanism used in the contextual hourglass module may not fully capture all the relevant contextual information, and there could be room for further improvements in this area.
Additionally, the paper does not provide a thorough analysis of the failure cases or edge cases where the model might struggle. It would be helpful to understand the types of aerial imagery or object configurations that are still challenging for the Contextual Hourglass Network.
Furthermore, the researchers could have explored the tradeoffs between the increased model complexity of their approach and its computational efficiency, which is an important consideration for real-world deployment of such systems.
Overall, the Contextual Hourglass Network represents an interesting and potentially impactful contribution to the field of semantic segmentation for aerial imagery. However, as with any research, there are opportunities for further refinement and exploration of the method's strengths, weaknesses, and practical implications.
Conclusion
The researchers have developed a novel semantic segmentation method called the Contextual Hourglass Network to address the challenges of varying object sizes and imbalanced class labels in aerial imagery analysis. By incorporating an attention mechanism and a stacked encoder-decoder architecture, their approach is able to effectively extract rich multi-scale features and learn contextual semantics, leading to improved overall performance on standard benchmark datasets.
While the Contextual Hourglass Network shows promise, the researchers acknowledge that there is room for further improvements, particularly in the attention mechanism and the analysis of failure cases. Nonetheless, this work represents an important step forward in advancing the state-of-the-art for semantic segmentation of aerial imagery, with potential applications in urban planning, agriculture, disaster response, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
0
Contextual Hourglass Network for Semantic Segmentation of High Resolution Aerial Imagery
Panfeng Li, Youzuo Lin, Emily Schultz-Fellenz
Semantic segmentation for aerial imagery is a challenging and important problem in remotely sensed imagery analysis. In recent years, with the success of deep learning, various convolutional neural network (CNN) based models have been developed. However, due to the varying sizes of the objects and imbalanced class labels, it can be challenging to obtain accurate pixel-wise semantic segmentation results. To address those challenges, we develop a novel semantic segmentation method and call it Contextual Hourglass Network. In our method, in order to improve the robustness of the prediction, we design a new contextual hourglass module which incorporates attention mechanism on processed low-resolution featuremaps to exploit the contextual semantics. We further exploit the stacked encoder-decoder structure by connecting multiple contextual hourglass modules from end to end. This architecture can effectively extract rich multi-scale features and add more feedback loops for better learning contextual semantics through intermediate supervision. To demonstrate the efficacy of our semantic segmentation method, we test it on Potsdam and Vaihingen datasets. Through the comparisons to other baseline methods, our method yields the best results on overall performance.
Read more9/17/2024

0
Context-Guided Spatial Feature Reconstruction for Efficient Semantic Segmentation
Zhenliang Ni, Xinghao Chen, Yingjie Zhai, Yehui Tang, Yunhe Wang
Semantic segmentation is an important task for numerous applications but it is still quite challenging to achieve advanced performance with limited computational costs. In this paper, we present CGRSeg, an efficient yet competitive segmentation framework based on context-guided spatial feature reconstruction. A Rectangular Self-Calibration Module is carefully designed for spatial feature reconstruction and pyramid context extraction. It captures the axial global context in both horizontal and vertical directions to explicitly model rectangular key areas. A shape self-calibration function is designed to make the key areas closer to foreground objects. Besides, a lightweight Dynamic Prototype Guided head is proposed to improve the classification of foreground objects by explicit class embedding. Our CGRSeg is extensively evaluated on ADE20K, COCO-Stuff, and Pascal Context benchmarks, and achieves state-of-the-art semantic performance. Specifically, it achieves $43.6%$ mIoU on ADE20K with only $4.0$ GFLOPs, which is $0.9%$ and $2.5%$ mIoU better than SeaFormer and SegNeXt but with about $38.0%$ fewer GFLOPs. Code is available at https://github.com/nizhenliang/CGRSeg.
Read more7/19/2024
0
Exploiting Object-based and Segmentation-based Semantic Features for Deep Learning-based Indoor Scene Classification
Ricardo Pereira, Lu'is Garrote, Tiago Barros, Ana Lopes, Urbano J. Nunes
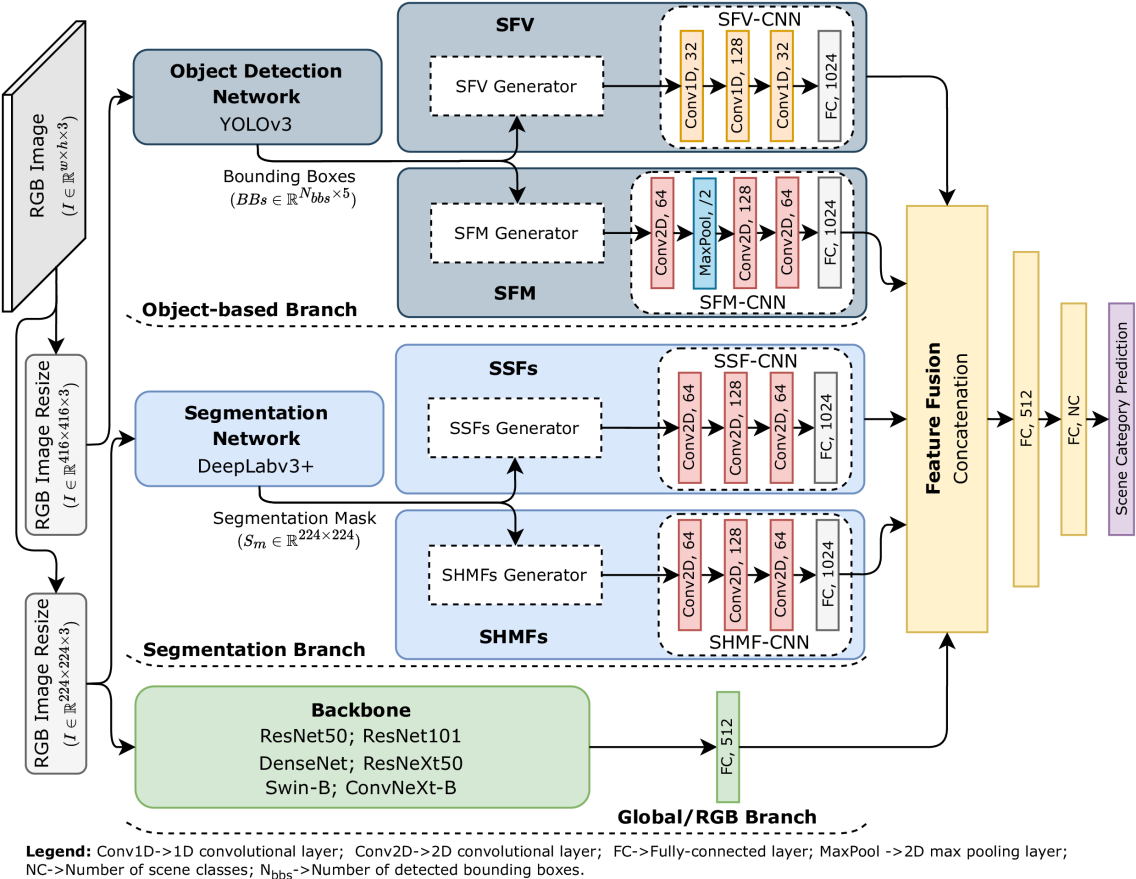
Indoor scenes are usually characterized by scattered objects and their relationships, which turns the indoor scene classification task into a challenging computer vision task. Despite the significant performance boost in classification tasks achieved in recent years, provided by the use of deep-learning-based methods, limitations such as inter-category ambiguity and intra-category variation have been holding back their performance. To overcome such issues, gathering semantic information has been shown to be a promising source of information towards a more complete and discriminative feature representation of indoor scenes. Therefore, the work described in this paper uses both semantic information, obtained from object detection, and semantic segmentation techniques. While object detection techniques provide the 2D location of objects allowing to obtain spatial distributions between objects, semantic segmentation techniques provide pixel-level information that allows to obtain, at a pixel-level, a spatial distribution and shape-related features of the segmentation categories. Hence, a novel approach that uses a semantic segmentation mask to provide Hu-moments-based segmentation categories' shape characterization, designated by Segmentation-based Hu-Moments Features (SHMFs), is proposed. Moreover, a three-main-branch network, designated by GOS$^2$F$^2$App, that exploits deep-learning-based global features, object-based features, and semantic segmentation-based features is also proposed. GOS$^2$F$^2$App was evaluated in two indoor scene benchmark datasets: SUN RGB-D and NYU Depth V2, where, to the best of our knowledge, state-of-the-art results were achieved on both datasets, which present evidences of the effectiveness of the proposed approach.
Read more4/12/2024
🌐
0
Contextual Encoder-Decoder Network for Visual Saliency Prediction
Alexander Kroner, Mario Senden, Kurt Driessens, Rainer Goebel
Predicting salient regions in natural images requires the detection of objects that are present in a scene. To develop robust representations for this challenging task, high-level visual features at multiple spatial scales must be extracted and augmented with contextual information. However, existing models aimed at explaining human fixation maps do not incorporate such a mechanism explicitly. Here we propose an approach based on a convolutional neural network pre-trained on a large-scale image classification task. The architecture forms an encoder-decoder structure and includes a module with multiple convolutional layers at different dilation rates to capture multi-scale features in parallel. Moreover, we combine the resulting representations with global scene information for accurately predicting visual saliency. Our model achieves competitive and consistent results across multiple evaluation metrics on two public saliency benchmarks and we demonstrate the effectiveness of the suggested approach on five datasets and selected examples. Compared to state of the art approaches, the network is based on a lightweight image classification backbone and hence presents a suitable choice for applications with limited computational resources, such as (virtual) robotic systems, to estimate human fixations across complex natural scenes.
Read more4/8/2024