Exploiting Object-based and Segmentation-based Semantic Features for Deep Learning-based Indoor Scene Classification

0
Sign in to get full access
Overview
- Explores the use of object-based and segmentation-based semantic features for indoor scene classification
- Proposes a deep learning-based approach that leverages both global and local visual cues
- Demonstrates superior performance compared to existing methods on standard benchmarks
Plain English Explanation
This research paper investigates a new way to classify indoor scenes, such as living rooms, kitchens, and offices, using deep learning techniques. The key idea is to exploit two types of visual information: object-based features and segmentation-based features.
Object-based features capture the semantic meaning of individual objects in the scene, like a couch or a refrigerator. Segmentation-based features, on the other hand, look at how the overall scene is divided into different regions or segments, like the floor, walls, and furniture. By combining these global and local visual cues, the researchers develop a more comprehensive scene representation that can better distinguish between different indoor environments.
The proposed deep learning model is trained to learn from this rich set of semantic features, allowing it to accurately classify indoor scenes with higher accuracy compared to previous methods. This could have practical applications in areas like robot navigation, augmented reality, and smart home automation, where understanding the surrounding environment is crucial.
Technical Explanation
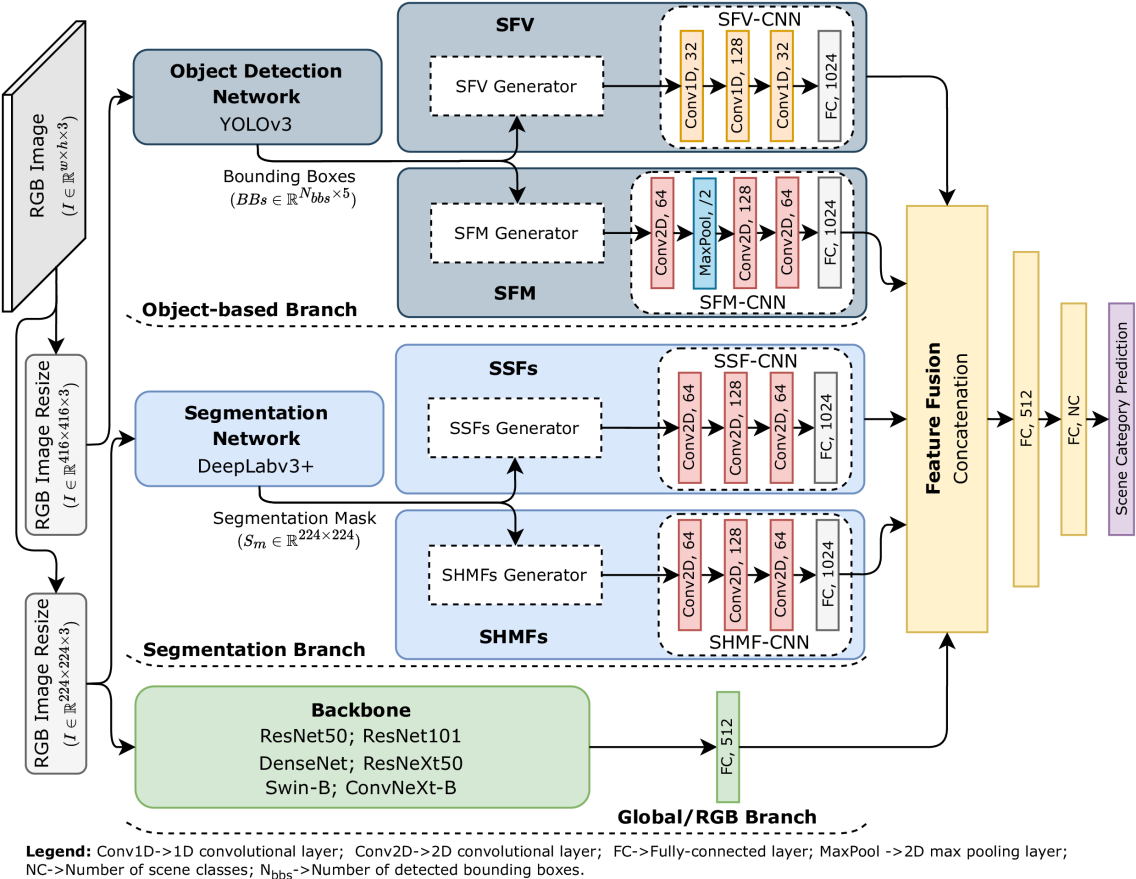
The paper presents a deep learning-based approach for indoor scene classification that exploits both object-based and segmentation-based semantic features. The key components of the model are:
- Object Detection: The researchers use a pre-trained object detection model to identify the objects present in the input image and extract their visual features.
- Semantic Segmentation: They also employ a segmentation network to partition the image into meaningful regions and extract region-level features.
- Feature Fusion: The object-based and segmentation-based features are then concatenated to form a comprehensive scene representation.
- Classification: The fused features are fed into a classification network to predict the indoor scene category.
The model is trained end-to-end on standard indoor scene datasets, such as SUN RGB-D and MIT Indoor. Experiments demonstrate that the proposed approach outperforms existing methods that rely on either global or local visual cues alone, highlighting the importance of combining object-based and segmentation-based semantic information for effective indoor scene classification.
Critical Analysis
The paper presents a well-designed and thorough investigation of the benefits of integrating object-based and segmentation-based features for indoor scene classification. The experimental results are convincing, and the proposed approach seems to offer a promising direction for further research in this area.
However, the paper does not discuss certain limitations or potential issues that could be addressed in future work. For example, the performance of the model may be sensitive to the accuracy of the underlying object detection and segmentation algorithms, which could be an area for improvement. Additionally, the model's generalization to more diverse or challenging indoor scenes, such as those with occlusions or unusual configurations, could be further explored.
The authors also do not provide much insight into the specific types of object-based and segmentation-based features that contribute the most to the model's performance. A more detailed analysis of the learned representations could yield additional design insights for future work in this domain.
Conclusion
This research paper presents a novel deep learning-based approach for indoor scene classification that effectively combines object-based and segmentation-based semantic features. The experimental results demonstrate that this comprehensive scene representation outperforms existing methods that rely on either global or local visual cues alone.
The proposed technique has the potential to advance the state of the art in visual recognition tasks, with applications in areas such as robot navigation, augmented reality, and smart home automation, where understanding the surrounding environment is crucial. The paper lays the groundwork for further research in this direction, exploring ways to improve the model's robustness and interpretability, and investigating its applicability to other scene understanding problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploiting Object-based and Segmentation-based Semantic Features for Deep Learning-based Indoor Scene Classification
Ricardo Pereira, Lu'is Garrote, Tiago Barros, Ana Lopes, Urbano J. Nunes
Indoor scenes are usually characterized by scattered objects and their relationships, which turns the indoor scene classification task into a challenging computer vision task. Despite the significant performance boost in classification tasks achieved in recent years, provided by the use of deep-learning-based methods, limitations such as inter-category ambiguity and intra-category variation have been holding back their performance. To overcome such issues, gathering semantic information has been shown to be a promising source of information towards a more complete and discriminative feature representation of indoor scenes. Therefore, the work described in this paper uses both semantic information, obtained from object detection, and semantic segmentation techniques. While object detection techniques provide the 2D location of objects allowing to obtain spatial distributions between objects, semantic segmentation techniques provide pixel-level information that allows to obtain, at a pixel-level, a spatial distribution and shape-related features of the segmentation categories. Hence, a novel approach that uses a semantic segmentation mask to provide Hu-moments-based segmentation categories' shape characterization, designated by Segmentation-based Hu-Moments Features (SHMFs), is proposed. Moreover, a three-main-branch network, designated by GOS$^2$F$^2$App, that exploits deep-learning-based global features, object-based features, and semantic segmentation-based features is also proposed. GOS$^2$F$^2$App was evaluated in two indoor scene benchmark datasets: SUN RGB-D and NYU Depth V2, where, to the best of our knowledge, state-of-the-art results were achieved on both datasets, which present evidences of the effectiveness of the proposed approach.
Read more4/12/2024

0
Learning Spatial-Semantic Features for Robust Video Object Segmentation
Xin Li, Deshui Miao, Zhenyu He, Yaowei Wang, Huchuan Lu, Ming-Hsuan Yang
Tracking and segmenting multiple similar objects with complex or separate parts in long-term videos is inherently challenging due to the ambiguity of target parts and identity confusion caused by occlusion, background clutter, and long-term variations. In this paper, we propose a robust video object segmentation framework equipped with spatial-semantic features and discriminative object queries to address the above issues. Specifically, we construct a spatial-semantic network comprising a semantic embedding block and spatial dependencies modeling block to associate the pretrained ViT features with global semantic features and local spatial features, providing a comprehensive target representation. In addition, we develop a masked cross-attention module to generate object queries that focus on the most discriminative parts of target objects during query propagation, alleviating noise accumulation and ensuring effective long-term query propagation. The experimental results show that the proposed method set a new state-of-the-art performance on multiple datasets, including the DAVIS2017 test (89.1%), YoutubeVOS 2019 (88.5%), MOSE (75.1%), LVOS test (73.0%), and LVOS val (75.1%), which demonstrate the effectiveness and generalization capacity of the proposed method. We will make all source code and trained models publicly available.
Read more7/11/2024
👁️
0
Semantic-guided modeling of spatial relation and object co-occurrence for indoor scene recognition
Chuanxin Song, Hanbo Wu, Xin Ma
Exploring the semantic context in scene images is essential for indoor scene recognition. However, due to the diverse intra-class spatial layouts and the coexisting inter-class objects, modeling contextual relationships to adapt various image characteristics is a great challenge. Existing contextual modeling methods for scene recognition exhibit two limitations: 1) They typically model only one type of spatial relationship (order or metric) among objects within scenes, with limited exploration of diverse spatial layouts. 2) They often overlook the differences in coexisting objects across different scenes, suppressing scene recognition performance. To overcome these limitations, we propose SpaCoNet, which simultaneously models Spatial relation and Co-occurrence of objects guided by semantic segmentation. Firstly, the Semantic Spatial Relation Module (SSRM) is constructed to model scene spatial features. With the help of semantic segmentation, this module decouples spatial information from the scene image and thoroughly explores all spatial relationships among objects in an end-to-end manner, thereby obtaining semantic-based spatial features. Secondly, both spatial features from the SSRM and deep features from the Image Feature Extraction Module are allocated to each object, so as to distinguish the coexisting object across different scenes. Finally, utilizing the discriminative features above, we design a Global-Local Dependency Module to explore the long-range co-occurrence among objects, and further generate a semantic-guided feature representation for indoor scene recognition. Experimental results on three widely used scene datasets demonstrate the effectiveness and generality of the proposed method.
Read more8/9/2024

0
Indoor scene recognition from images under visual corruptions
Willams de Lima Costa, Raul Ismayilov, Nicola Strisciuglio, Estefania Talavera Martinez
The classification of indoor scenes is a critical component in various applications, such as intelligent robotics for assistive living. While deep learning has significantly advanced this field, models often suffer from reduced performance due to image corruption. This paper presents an innovative approach to indoor scene recognition that leverages multimodal data fusion, integrating caption-based semantic features with visual data to enhance both accuracy and robustness against corruption. We examine two multimodal networks that synergize visual features from CNN models with semantic captions via a Graph Convolutional Network (GCN). Our study shows that this fusion markedly improves model performance, with notable gains in Top-1 accuracy when evaluated against a corrupted subset of the Places365 dataset. Moreover, while standalone visual models displayed high accuracy on uncorrupted images, their performance deteriorated significantly with increased corruption severity. Conversely, the multimodal models demonstrated improved accuracy in clean conditions and substantial robustness to a range of image corruptions. These results highlight the efficacy of incorporating high-level contextual information through captions, suggesting a promising direction for enhancing the resilience of classification systems.
Read more8/26/2024