Continual Forgetting for Pre-trained Vision Models

0

Sign in to get full access
Overview
- This paper explores the problem of continual forgetting in pre-trained vision models, where a model's performance on previous tasks degrades as it is trained on new tasks.
- The authors propose several techniques to mitigate this issue, including LORA (Low-Rank Adaptation), InflORA (Interference-Free Low-Rank Adaptation), and a contrastive strategy for lifelong learning with selective forgetting.
- They also provide an empirical analysis of forgetting in pre-trained models and demonstrate the effectiveness of their proposed methods.
Plain English Explanation
The paper tackles the problem of continual forgetting, which is a common issue in machine learning models. As a model learns new tasks, it tends to forget how to perform previous tasks. This can be a significant problem, especially in real-world applications where models need to adapt and learn over time without losing their original capabilities.
The researchers explore different techniques to help models remember what they've learned in the past while also learning new things. One method they investigate is called LORA, which stands for Low-Rank Adaptation. This approach allows the model to adapt to new tasks without completely overwriting the knowledge it had previously acquired. Another technique they propose is InflORA, which is an interference-free version of LORA that further reduces the risk of forgetting.
Additionally, the researchers develop a contrastive strategy for lifelong learning, where the model actively tries to remember important information from the past while also learning new things. This helps the model strike a balance between adapting to new tasks and retaining its original capabilities.
The paper also includes an in-depth analysis of how pre-trained models (models that have been trained on a large amount of data before being used for a specific task) tend to forget their previous knowledge as they are trained on new tasks. This provides valuable insights into the challenges of continual learning and the importance of developing techniques to address them.
Overall, this research aims to make machine learning models more robust and adaptive, allowing them to continuously learn and evolve without losing their hard-earned knowledge.
Technical Explanation
The paper presents several techniques to address the problem of continual forgetting in pre-trained vision models. Continual forgetting refers to the degradation of a model's performance on previous tasks as it is trained on new tasks.
One of the proposed methods is LORA (Low-Rank Adaptation), which allows the model to adapt to new tasks without completely overwriting the knowledge it had previously acquired. LORA achieves this by adding low-rank matrices to the model's existing parameters, which can be efficiently updated during training without significantly modifying the original model.
The authors also introduce InflORA (Interference-Free Low-Rank Adaptation), an extension of LORA that further reduces the risk of forgetting by minimizing interference between different task-specific adapters.
Additionally, the researchers develop a contrastive strategy for lifelong learning with selective forgetting. This approach encourages the model to remember important information from the past while also learning new tasks, by using a contrastive loss function that balances between retaining old knowledge and acquiring new knowledge.
The paper also provides an empirical analysis of forgetting in pre-trained models, which sheds light on the challenges of continual learning and the importance of developing techniques to address them. The analysis reveals that pre-trained models tend to experience significant forgetting as they are fine-tuned on new tasks, highlighting the need for more effective continual learning methods.
Critical Analysis
The paper presents a comprehensive set of techniques to address the problem of continual forgetting in pre-trained vision models, which is a crucial challenge in the field of machine learning. The authors' proposals, such as LORA, InflORA, and the contrastive strategy for lifelong learning, offer promising solutions to this problem.
However, the paper does not explore the potential limitations or caveats of these approaches. For example, it would be valuable to understand the computational and memory overhead associated with the proposed techniques, as well as their scalability to larger and more complex models. Additionally, the authors could have discussed the potential for negative transfer, where learning a new task might interfere with the model's performance on previous tasks, and how their methods address this issue.
Another area for further exploration is the generalization of these techniques to other domains beyond vision models, such as natural language processing or speech recognition. Investigating the transferability of these continual learning methods to different task types could broaden their impact and relevance.
Despite these potential areas for further research, the paper makes a valuable contribution to the field of continual learning by introducing novel techniques and providing a thorough empirical analysis of forgetting in pre-trained models. These insights and the proposed solutions can serve as a foundation for developing more robust and adaptable machine learning models.
Conclusion
This paper presents a comprehensive study of continual forgetting in pre-trained vision models and proposes several techniques to mitigate this issue. The authors introduce LORA, InflORA, and a contrastive strategy for lifelong learning, all of which aim to help models remember their past knowledge while also learning new tasks.
The empirical analysis of forgetting in pre-trained models provides valuable insights into the challenges of continual learning, underscoring the importance of developing effective solutions. The proposed methods offer promising approaches to address this problem, with the potential to improve the adaptability and long-term performance of machine learning models in real-world applications.
As the field of machine learning continues to advance, the ability of models to learn and adapt over time without catastrophic forgetting will become increasingly crucial. The techniques and insights presented in this paper contribute to the ongoing efforts to create more robust and versatile AI systems that can continually expand their knowledge and capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Continual Forgetting for Pre-trained Vision Models
Hongbo Zhao, Bolin Ni, Haochen Wang, Junsong Fan, Fei Zhu, Yuxi Wang, Yuntao Chen, Gaofeng Meng, Zhaoxiang Zhang
For privacy and security concerns, the need to erase unwanted information from pre-trained vision models is becoming evident nowadays. In real-world scenarios, erasure requests originate at any time from both users and model owners. These requests usually form a sequence. Therefore, under such a setting, selective information is expected to be continuously removed from a pre-trained model while maintaining the rest. We define this problem as continual forgetting and identify two key challenges. (i) For unwanted knowledge, efficient and effective deleting is crucial. (ii) For remaining knowledge, the impact brought by the forgetting procedure should be minimal. To address them, we propose Group Sparse LoRA (GS-LoRA). Specifically, towards (i), we use LoRA modules to fine-tune the FFN layers in Transformer blocks for each forgetting task independently, and towards (ii), a simple group sparse regularization is adopted, enabling automatic selection of specific LoRA groups and zeroing out the others. GS-LoRA is effective, parameter-efficient, data-efficient, and easy to implement. We conduct extensive experiments on face recognition, object detection and image classification and demonstrate that GS-LoRA manages to forget specific classes with minimal impact on other classes. Codes will be released on url{https://github.com/bjzhb666/GS-LoRA}.
Read more7/19/2024
0
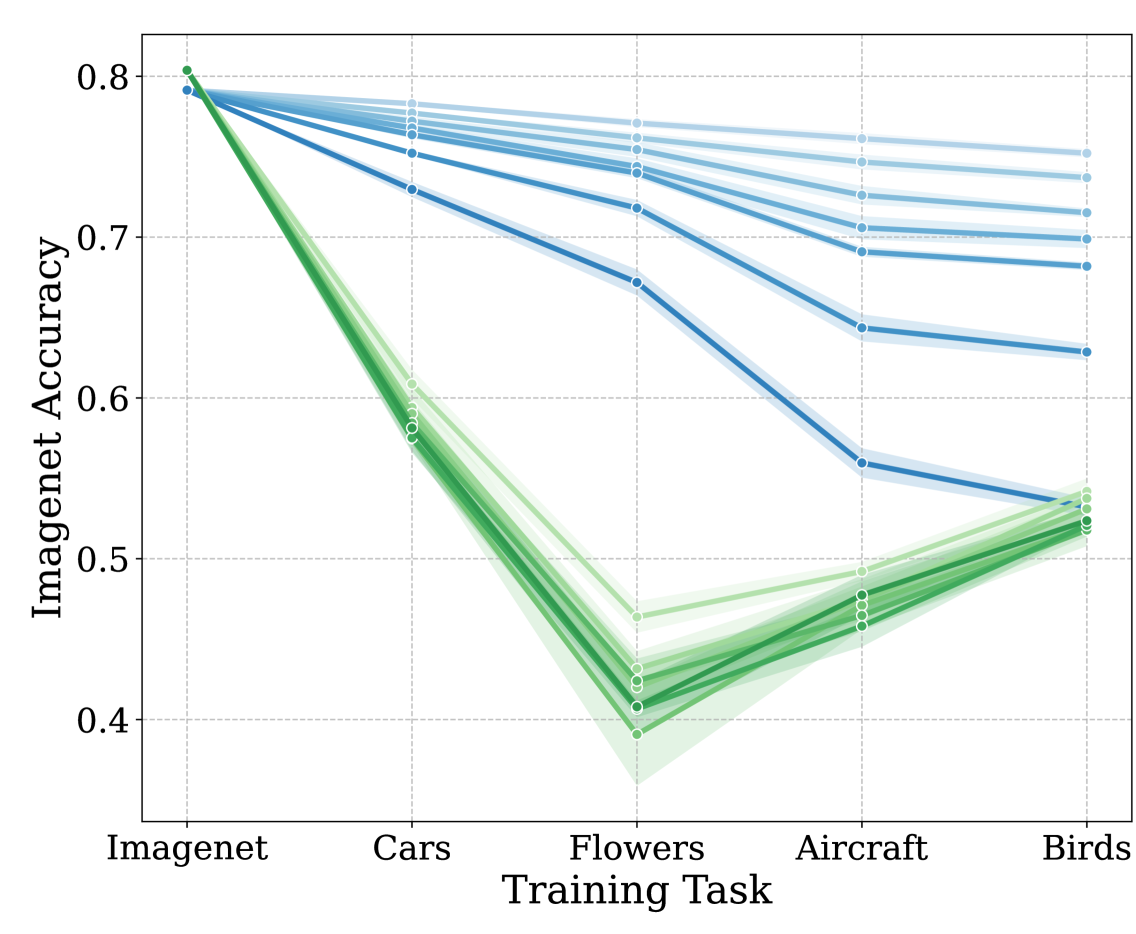
An Empirical Analysis of Forgetting in Pre-trained Models with Incremental Low-Rank Updates
Albin Soutif--Cormerais, Simone Magistri, Joost van de Weijer, Andew D. Bagdanov
Broad, open source availability of large pretrained foundation models on the internet through platforms such as HuggingFace has taken the world of practical deep learning by storm. A classical pipeline for neural network training now typically consists of finetuning these pretrained network on a small target dataset instead of training from scratch. In the case of large models this can be done even on modest hardware using a low rank training technique known as Low-Rank Adaptation (LoRA). While Low Rank training has already been studied in the continual learning setting, existing works often consider storing the learned adapter along with the existing model but rarely attempt to modify the weights of the pretrained model by merging the LoRA with the existing weights after finishing the training of each task. In this article we investigate this setting and study the impact of LoRA rank on the forgetting of the pretraining foundation task and on the plasticity and forgetting of subsequent ones. We observe that this rank has an important impact on forgetting of both the pretraining and downstream tasks. We also observe that vision transformers finetuned in that way exhibit a sort of ``contextual'' forgetting, a behaviour that we do not observe for residual networks and that we believe has not been observed yet in previous continual learning works.
Read more5/29/2024

0
Accurate Forgetting for All-in-One Image Restoration Model
Xin Su, Zhuoran Zheng
Privacy protection has always been an ongoing topic, especially for AI. Currently, a low-cost scheme called Machine Unlearning forgets the private data remembered in the model. Specifically, given a private dataset and a trained neural network, we need to use e.g. pruning, fine-tuning, and gradient ascent to remove the influence of the private dataset on the neural network. Inspired by this, we try to use this concept to bridge the gap between the fields of image restoration and security, creating a new research idea. We propose the scene for the All-In-One model (a neural network that restores a wide range of degraded information), where a given dataset such as haze, or rain, is private and needs to be eliminated from the influence of it on the trained model. Notably, we find great challenges in this task to remove the influence of sensitive data while ensuring that the overall model performance remains robust, which is akin to directing a symphony orchestra without specific instruments while keeping the playing soothing. Here we explore a simple but effective approach: Instance-wise Unlearning through the use of adversarial examples and gradient ascent techniques. Our approach is a low-cost solution compared to the strategy of retraining the model from scratch, where the gradient ascent trick forgets the specified data and the performance of the adversarial sample maintenance model is robust. Through extensive experimentation on two popular unified image restoration models, we show that our approach effectively preserves knowledge of remaining data while unlearning a given degradation type.
Read more9/4/2024
123
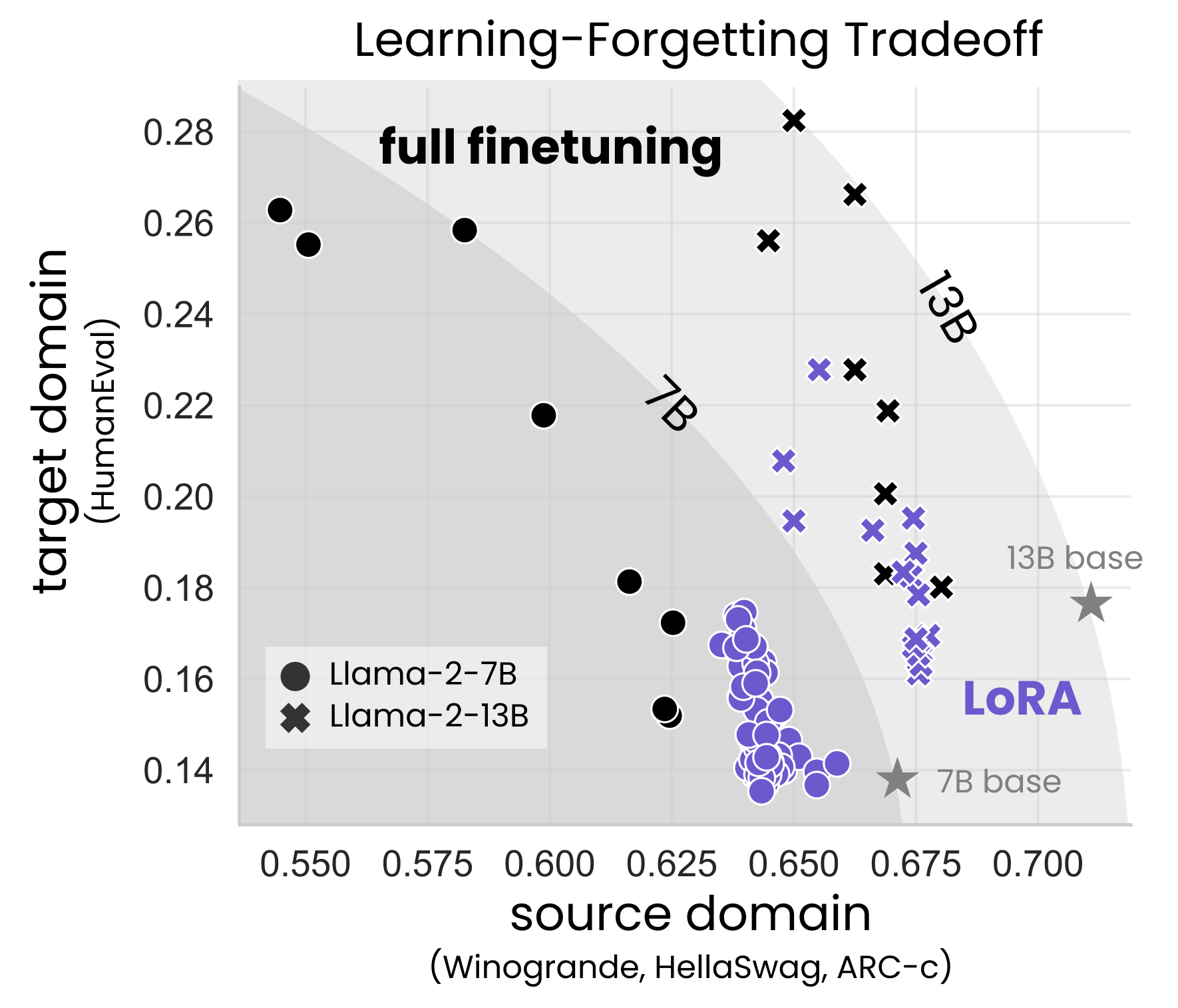
LoRA Learns Less and Forgets Less
Dan Biderman, Jacob Portes, Jose Javier Gonzalez Ortiz, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, Cody Blakeney, John P. Cunningham
Low-Rank Adaptation (LoRA) is a widely-used parameter-efficient finetuning method for large language models. LoRA saves memory by training only low rank perturbations to selected weight matrices. In this work, we compare the performance of LoRA and full finetuning on two target domains, programming and mathematics. We consider both the instruction finetuning (approximately 100K prompt-response pairs) and continued pretraining (20B unstructured tokens) data regimes. Our results show that, in the standard low-rank settings, LoRA substantially underperforms full finetuning. Nevertheless, LoRA better maintains the base model's performance on tasks outside the target domain. We show that LoRA mitigates forgetting more than common regularization techniques such as weight decay and dropout; it also helps maintain more diverse generations. Finally, we show that full finetuning learns perturbations with a rank that is 10-100X greater than typical LoRA configurations, possibly explaining some of the reported gaps. We conclude by proposing best practices for finetuning with LoRA.
Read more9/24/2024