Lifelong Learning and Selective Forgetting via Contrastive Strategy

0
➖
Sign in to get full access
Overview
- This paper provides an example of how to typeset multiple authors in IJCAI-22 conference papers.
- It covers guidelines for formatting author names, affiliations, and other key elements of the author information.
- The goal is to ensure a consistent and professional appearance for author details in IJCAI-22 submissions.
Plain English Explanation
This paper is a guide on how to properly format the author information in papers submitted to the IJCAI-22 conference. It explains the right way to list the names of all the authors and their affiliations (the institutions they work for) so that the paper looks neat and organized.
The authors wanted to make sure there was a standard way to present this information, so that all the IJCAI-22 papers would have a similar, polished appearance. Having clear guidelines helps authors focus on the content of their research without worrying about the formatting of their names and affiliations.
Technical Explanation
The paper outlines the recommended formatting for author names and affiliations in IJCAI-22 submissions. For author names, it provides guidance on capitalization, name ordering, and handling middle initials or suffixes.
For affiliations, the paper explains how to properly list institution names, departments, and addresses. It also covers how to handle situations with multiple affiliations per author or shared affiliations between authors.
The goal is to ensure a consistent, readable, and professional presentation of the author information across all IJCAI-22 papers. Following these guidelines helps the conference organizers and readers quickly and easily identify the authors and where they are from.
Critical Analysis
The paper serves an important purpose in establishing clear formatting standards for IJCAI-22 author information. Having a consistent approach makes the papers easier to read and understand at a glance.
One potential limitation is that these guidelines may not seamlessly translate to other conference or journal formats, which could create extra work for authors submitting to multiple venues. However, the focus on IJCAI-22 specifically is reasonable given the need for standardization within a single conference.
Overall, this paper provides valuable guidance to help IJCAI-22 authors present their author details in the clearest and most professional manner possible. Adhering to these recommendations can improve the quality and accessibility of the submitted research.
Conclusion
This IJCAI-22 example paper outlines the recommended best practices for formatting author names, affiliations, and related information in conference submissions. By establishing these guidelines, the organizers aim to ensure a consistent and polished appearance across all accepted papers.
Following these standards helps authors focus on the content of their research without having to worry about the formatting details. It also makes it easier for readers to quickly identify the authors and their backgrounds. Overall, this guidance contributes to a high-quality and professional IJCAI-22 proceedings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
0
Lifelong Learning and Selective Forgetting via Contrastive Strategy
Lianlei Shan, Wenzhang Zhou, Wei Li, Xingyu Ding
Lifelong learning aims to train a model with good performance for new tasks while retaining the capacity of previous tasks. However, some practical scenarios require the system to forget undesirable knowledge due to privacy issues, which is called selective forgetting. The joint task of the two is dubbed Learning with Selective Forgetting (LSF). In this paper, we propose a new framework based on contrastive strategy for LSF. Specifically, for the preserved classes (tasks), we make features extracted from different samples within a same class compacted. And for the deleted classes, we make the features from different samples of a same class dispersed and irregular, i.e., the network does not have any regular response to samples from a specific deleted class as if the network has no training at all. Through maintaining or disturbing the feature distribution, the forgetting and memory of different classes can be or independent of each other. Experiments are conducted on four benchmark datasets, and our method acieves new state-of-the-art.
Read more5/30/2024

0
Forgetting in Machine Learning and Beyond: A Survey
Alyssa Shuang Sha, Bernardo Pereira Nunes, Armin Haller
This survey investigates the multifaceted nature of forgetting in machine learning, drawing insights from neuroscientific research that posits forgetting as an adaptive function rather than a defect, enhancing the learning process and preventing overfitting. This survey focuses on the benefits of forgetting and its applications across various machine learning sub-fields that can help improve model performance and enhance data privacy. Moreover, the paper discusses current challenges, future directions, and ethical considerations regarding the integration of forgetting mechanisms into machine learning models.
Read more6/3/2024
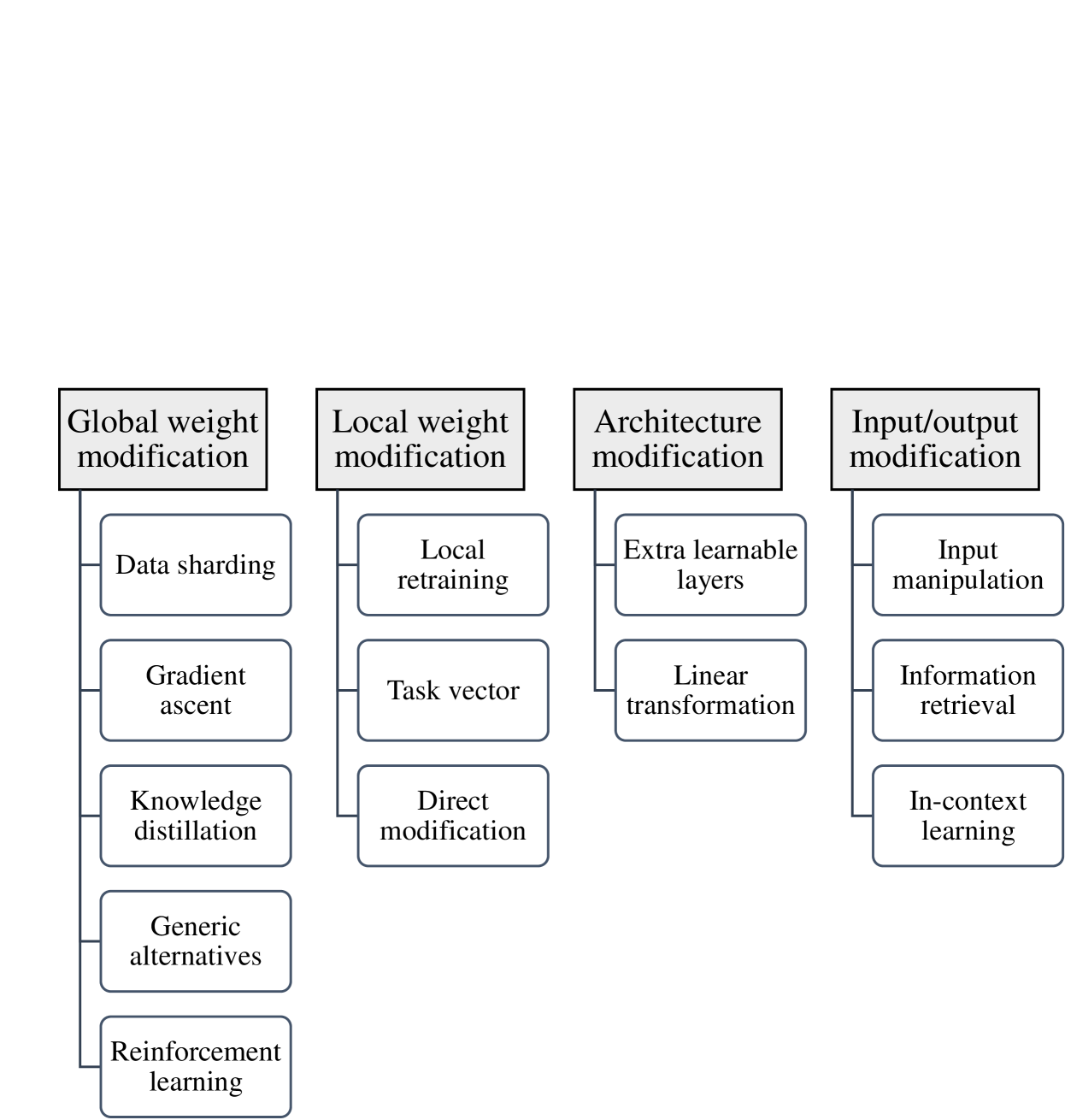
0
Digital Forgetting in Large Language Models: A Survey of Unlearning Methods
Alberto Blanco-Justicia, Najeeb Jebreel, Benet Manzanares, David S'anchez, Josep Domingo-Ferrer, Guillem Collell, Kuan Eeik Tan
The objective of digital forgetting is, given a model with undesirable knowledge or behavior, obtain a new model where the detected issues are no longer present. The motivations for forgetting include privacy protection, copyright protection, elimination of biases and discrimination, and prevention of harmful content generation. Effective digital forgetting has to be effective (meaning how well the new model has forgotten the undesired knowledge/behavior), retain the performance of the original model on the desirable tasks, and be scalable (in particular forgetting has to be more efficient than retraining from scratch on just the tasks/data to be retained). This survey focuses on forgetting in large language models (LLMs). We first provide background on LLMs, including their components, the types of LLMs, and their usual training pipeline. Second, we describe the motivations, types, and desired properties of digital forgetting. Third, we introduce the approaches to digital forgetting in LLMs, among which unlearning methodologies stand out as the state of the art. Fourth, we provide a detailed taxonomy of machine unlearning methods for LLMs, and we survey and compare current approaches. Fifth, we detail datasets, models and metrics used for the evaluation of forgetting, retaining and runtime. Sixth, we discuss challenges in the area. Finally, we provide some concluding remarks.
Read more4/3/2024

0
Controlling Forgetting with Test-Time Data in Continual Learning
Vaibhav Singh, Rahaf Aljundi, Eugene Belilovsky
Foundational vision-language models have shown impressive performance on various downstream tasks. Yet, there is still a pressing need to update these models later as new tasks or domains become available. Ongoing Continual Learning (CL) research provides techniques to overcome catastrophic forgetting of previous information when new knowledge is acquired. To date, CL techniques focus only on the supervised training sessions. This results in significant forgetting yielding inferior performance to even the prior model zero shot performance. In this work, we argue that test-time data hold great information that can be leveraged in a self supervised manner to refresh the model's memory of previous learned tasks and hence greatly reduce forgetting at no extra labelling cost. We study how unsupervised data can be employed online to improve models' performance on prior tasks upon encountering representative samples. We propose a simple yet effective student-teacher model with gradient based sparse parameters updates and show significant performance improvements and reduction in forgetting, which could alleviate the role of an offline episodic memory/experience replay buffer.
Read more6/21/2024