Continual Learning of Conjugated Visual Representations through Higher-order Motion Flows

0

Sign in to get full access
Overview
- This paper presents a novel approach to continual learning for visual representations.
- Key ideas include [link to 1 Example Section] using higher-order visual representations and [link to 1.1 Example Subsection] learning a semantic field for dynamic scenes.
- The proposed methods aim to address the challenge of learning new visual concepts without forgetting previously learned knowledge.
Plain English Explanation
[Link to 1 Example Section] The researchers developed a system that can continuously learn new visual concepts without forgetting what it has already learned. This is an important problem in machine learning, as models often struggle to adapt to new information without catastrophically forgetting past knowledge.
[Link to 1.1 Example Subsection] The core idea is to learn a "semantic field" that captures the relationships between different visual concepts. This allows the model to understand how new information relates to what it already knows, making it easier to incorporate novel concepts without losing old ones.
The researchers tested their approach on various visual recognition tasks, and found that it outperformed standard continual learning methods. This suggests their techniques could be valuable for building AI systems that can flexibly adapt to changing environments and demands over time.
Technical Explanation
[Link to 1 Example Section] The paper proposes a continual learning framework that leverages higher-order visual representations to preserve knowledge about previously learned concepts. By encoding relationships between visual features, the model can more effectively integrate new information without catastrophic forgetting.
[Link to 1.1 Example Subsection] A key component is the learning of a "semantic field" - a latent space that captures the semantics and structure of the visual world. This allows the model to understand how new visual inputs relate to its existing knowledge, facilitating the assimilation of novel concepts.
The researchers evaluate their approach on several continual learning benchmarks, including object recognition and semantic segmentation tasks. Their method demonstrates superior performance compared to standard continual learning baselines, suggesting it is an effective strategy for building adaptable visual recognition systems.
Critical Analysis
The paper presents a promising direction for continual learning, but there are some caveats to consider. While the semantic field approach seems effective, it relies on strong assumptions about the underlying structure of the visual world. Its performance may be sensitive to the quality and coverage of the training data.
Additionally, the paper does not fully address potential issues around computational complexity and scalability. As the model needs to maintain and update a rich semantic representation, the training and inference costs could become prohibitive for large-scale, real-world applications.
Further research is needed to understand the broader applicability of this approach, as well as to explore potential ways to make it more efficient and robust. Validating the method on a wider range of continual learning benchmarks and real-world scenarios would also help to more comprehensively evaluate its strengths and limitations.
Conclusion
This paper introduces an innovative approach to continual learning for visual representations, leveraging higher-order representations and a learned semantic field to enable the flexible incorporation of new knowledge. The proposed techniques demonstrate promising results on several benchmarks, suggesting they could be valuable for building adaptable AI systems capable of learning and evolving over time.
While the method has some promising aspects, further research is needed to fully understand its capabilities, limitations, and practical viability. Continued advancements in this area could have significant implications for the development of more robust and versatile machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Continual Learning of Conjugated Visual Representations through Higher-order Motion Flows
Simone Marullo, Matteo Tiezzi, Marco Gori, Stefano Melacci
Learning with neural networks from a continuous stream of visual information presents several challenges due to the non-i.i.d. nature of the data. However, it also offers novel opportunities to develop representations that are consistent with the information flow. In this paper we investigate the case of unsupervised continual learning of pixel-wise features subject to multiple motion-induced constraints, therefore named motion-conjugated feature representations. Differently from existing approaches, motion is not a given signal (either ground-truth or estimated by external modules), but is the outcome of a progressive and autonomous learning process, occurring at various levels of the feature hierarchy. Multiple motion flows are estimated with neural networks and characterized by different levels of abstractions, spanning from traditional optical flow to other latent signals originating from higher-level features, hence called higher-order motions. Continuously learning to develop consistent multi-order flows and representations is prone to trivial solutions, which we counteract by introducing a self-supervised contrastive loss, spatially-aware and based on flow-induced similarity. We assess our model on photorealistic synthetic streams and real-world videos, comparing to pre-trained state-of-the art feature extractors (also based on Transformers) and to recent unsupervised learning models, significantly outperforming these alternatives.
Read more9/19/2024
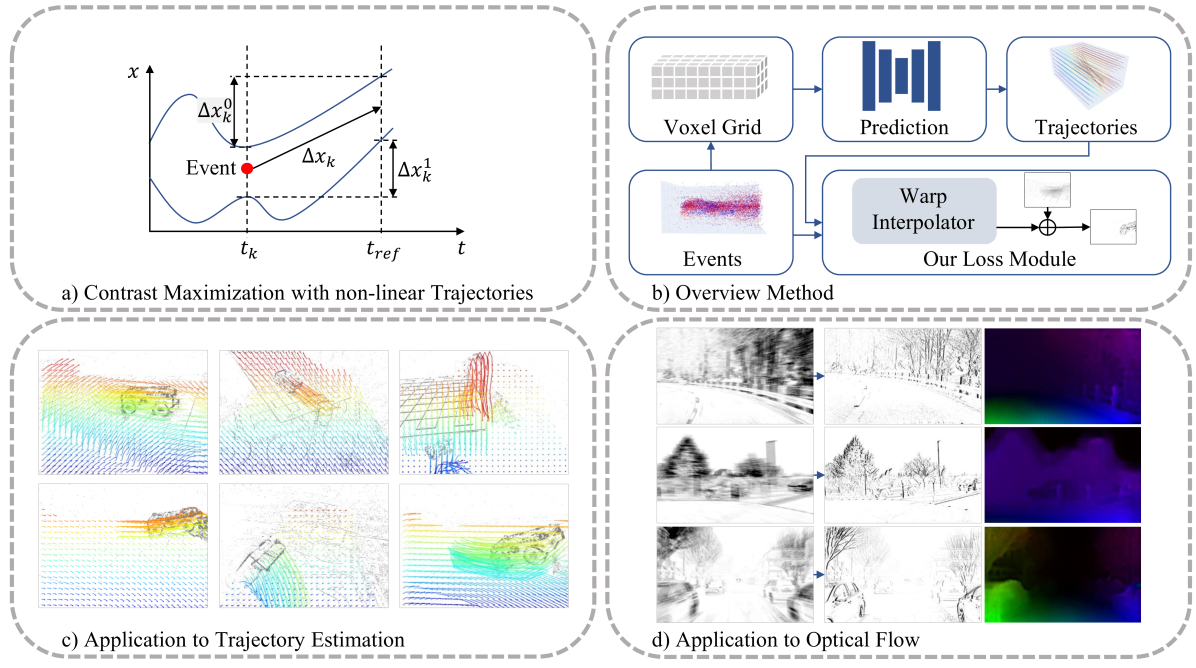
0
Motion-prior Contrast Maximization for Dense Continuous-Time Motion Estimation
Friedhelm Hamann, Ziyun Wang, Ioannis Asmanis, Kenneth Chaney, Guillermo Gallego, Kostas Daniilidis
Current optical flow and point-tracking methods rely heavily on synthetic datasets. Event cameras are novel vision sensors with advantages in challenging visual conditions, but state-of-the-art frame-based methods cannot be easily adapted to event data due to the limitations of current event simulators. We introduce a novel self-supervised loss combining the Contrast Maximization framework with a non-linear motion prior in the form of pixel-level trajectories and propose an efficient solution to solve the high-dimensional assignment problem between non-linear trajectories and events. Their effectiveness is demonstrated in two scenarios: In dense continuous-time motion estimation, our method improves the zero-shot performance of a synthetically trained model on the real-world dataset EVIMO2 by 29%. In optical flow estimation, our method elevates a simple UNet to achieve state-of-the-art performance among self-supervised methods on the DSEC optical flow benchmark. Our code is available at https://github.com/tub-rip/MotionPriorCMax.
Read more7/16/2024

0
Continually Learn to Map Visual Concepts to Large Language Models in Resource-constrained Environments
Clea Rebillard, Julio Hurtado, Andrii Krutsylo, Lucia Passaro, Vincenzo Lomonaco
Learning continually from a stream of non-i.i.d. data is an open challenge in deep learning, even more so when working in resource-constrained environments such as embedded devices. Visual models that are continually updated through supervised learning are often prone to overfitting, catastrophic forgetting, and biased representations. On the other hand, large language models contain knowledge about multiple concepts and their relations, which can foster a more robust, informed and coherent learning process. This work proposes Continual Visual Mapping (CVM), an approach that continually ground vision representations to a knowledge space extracted from a fixed Language model. Specifically, CVM continually trains a small and efficient visual model to map its representations into a conceptual space established by a fixed Large Language Model. Due to their smaller nature, CVM can be used when directly adapting large visual pre-trained models is unfeasible due to computational or data constraints. CVM overcome state-of-the-art continual learning methods on five benchmarks and offers a promising avenue for addressing generalization capabilities in continual learning, even in computationally constrained devices.
Read more7/12/2024

0
Online Continual Learning of Video Diffusion Models From a Single Video Stream
Jason Yoo, Dylan Green, Geoff Pleiss, Frank Wood
Diffusion models have shown exceptional capabilities in generating realistic videos. Yet, their training has been predominantly confined to offline environments where models can repeatedly train on i.i.d. data to convergence. This work explores the feasibility of training diffusion models from a semantically continuous video stream, where correlated video frames sequentially arrive one at a time. To investigate this, we introduce two novel continual video generative modeling benchmarks, Lifelong Bouncing Balls and Windows 95 Maze Screensaver, each containing over a million video frames generated from navigating stationary environments. Surprisingly, our experiments show that diffusion models can be effectively trained online using experience replay, achieving performance comparable to models trained with i.i.d. samples given the same number of gradient steps.
Read more6/10/2024