Continual Learning: Forget-free Winning Subnetworks for Video Representations

0

Sign in to get full access
Overview
- This paper explores a novel approach to continual learning, which is the challenge of training AI models to learn new tasks without forgetting previously learned information.
- The key idea is to identify "winning subnetworks" - small, specialized parts of a neural network that are responsible for specific tasks or video representations.
- By preserving these winning subnetworks during continual learning, the model can retain its previous capabilities while efficiently learning new ones.
- The authors demonstrate the effectiveness of this approach on several video understanding benchmarks, showing significant performance improvements over existing continual learning methods.
Plain English Explanation
The paper is about a technique for training AI models that can continuously learn new tasks without forgetting what they've learned before. This is a common challenge in machine learning, called "continual learning."
The main insight is that in a large neural network, there are often smaller, specialized parts - or "subnetworks" - that are responsible for specific skills or video representations. The researchers call these the "winning subnetworks."
The key idea is to try to preserve these winning subnetworks when the model learns new tasks, rather than letting the whole network get overwritten. This allows the model to retain its previous capabilities while efficiently picking up new ones.
The paper shows that this approach works well on several video understanding benchmarks, outperforming other continual learning methods. It's an interesting solution to a important problem in AI - the ability to learn and adapt over time without completely forgetting the past.
Technical Explanation
The paper proposes a novel continual learning approach called "Forget-free Winning Subnetworks" (FWS). The core idea is to identify and preserve specialized "winning subnetworks" within a larger neural network that are responsible for specific tasks or video representations.
To do this, the authors leverage the Fourier space representation of the network weights. They show that the most important weights for a given task tend to have the largest Fourier coefficients. By selectively preserving these high-magnitude Fourier coefficients during finetuning on new tasks, the model can acquire new capabilities while largely retaining its previous knowledge.
The authors demonstrate FWS on several video understanding benchmarks, including action recognition and video retrieval tasks. Compared to standard finetuning and other continual learning baselines, FWS achieves significantly higher performance, showing its ability to "forget-free" learning of new skills.
The paper also provides theoretical analysis to show that the winning subnetworks identified in this way are indeed the most important for the corresponding tasks. Overall, this work presents a principled approach to continual learning that has strong empirical results and interesting connections to the underlying network structure.
Critical Analysis
The FWS approach presented in this paper is a promising step towards more effective continual learning in deep neural networks. By focusing on preserving the most critical subnetwork components, it avoids the common issue of "catastrophic forgetting" that plagues many continual learning methods.
However, the paper does acknowledge some limitations. For example, the identification of winning subnetworks relies on the Fourier decomposition of the weight matrices, which may not generalize to all network architectures. Additionally, the experiments are primarily focused on video understanding tasks, so more evaluation on other domains would help validate the broader applicability of the method.
Another potential area for further exploration is the scalability of the approach. As models and tasks grow in complexity, the overhead of identifying and selectively preserving winning subnetworks may become prohibitive. Developing more efficient or automated mechanisms for this process could unlock FWS for larger-scale continual learning scenarios.
Overall, this work makes an important contribution to the field of continual learning by introducing a novel perspective rooted in the network's internal structure. While not a panacea, the FWS approach represents a valuable addition to the toolbox of continual learning techniques, and the insights it provides could inspire further advancements in this active area of research.
Conclusion
The "Forget-free Winning Subnetworks" approach presented in this paper offers a promising solution to the challenge of continual learning in deep neural networks. By identifying and preserving the most critical subnetwork components, it allows models to efficiently acquire new capabilities while largely retaining their previous knowledge and skills.
The strong empirical results on video understanding benchmarks demonstrate the effectiveness of this approach, which could have important implications for a wide range of real-world AI applications that require ongoing learning and adaptation. While the method has some limitations that warrant further exploration, this work represents a valuable step forward in the field of continual learning.
As AI systems become increasingly capable and ubiquitous, the ability to learn continuously without forgetting will be essential. Techniques like FWS that leverage the internal structure of neural networks could play a crucial role in realizing the full potential of adaptive, lifelong learning in artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Continual Learning: Forget-free Winning Subnetworks for Video Representations
Haeyong Kang, Jaehong Yoon, Sung Ju Hwang, Chang D. Yoo
Inspired by the Lottery Ticket Hypothesis (LTH), which highlights the existence of efficient subnetworks within larger, dense networks, a high-performing Winning Subnetwork (WSN) in terms of task performance under appropriate sparsity conditions is considered for various continual learning tasks. It leverages pre-existing weights from dense networks to achieve efficient learning in Task Incremental Learning (TIL) and Task-agnostic Incremental Learning (TaIL) scenarios. In Few-Shot Class Incremental Learning (FSCIL), a variation of WSN referred to as the Soft subnetwork (SoftNet) is designed to prevent overfitting when the data samples are scarce. Furthermore, the sparse reuse of WSN weights is considered for Video Incremental Learning (VIL). The use of Fourier Subneural Operator (FSO) within WSN is considered. It enables compact encoding of videos and identifies reusable subnetworks across varying bandwidths. We have integrated FSO into different architectural frameworks for continual learning, including VIL, TIL, and FSCIL. Our comprehensive experiments demonstrate FSO's effectiveness, significantly improving task performance at various convolutional representational levels. Specifically, FSO enhances higher-layer performance in TIL and FSCIL and lower-layer performance in VIL.
Read more6/4/2024

0
Continual Deep Learning on the Edge via Stochastic Local Competition among Subnetworks
Theodoros Christophides, Kyriakos Tolias, Sotirios Chatzis
Continual learning on edge devices poses unique challenges due to stringent resource constraints. This paper introduces a novel method that leverages stochastic competition principles to promote sparsity, significantly reducing deep network memory footprint and computational demand. Specifically, we propose deep networks that comprise blocks of units that compete locally to win the representation of each arising new task; competition takes place in a stochastic manner. This type of network organization results in sparse task-specific representations from each network layer; the sparsity pattern is obtained during training and is different among tasks. Crucially, our method sparsifies both the weights and the weight gradients, thus facilitating training on edge devices. This is performed on the grounds of winning probability for each unit in a block. During inference, the network retains only the winning unit and zeroes-out all weights pertaining to non-winning units for the task at hand. Thus, our approach is specifically tailored for deployment on edge devices, providing an efficient and scalable solution for continual learning in resource-limited environments.
Read more7/16/2024

0
The EarlyBird Gets the WORM: Heuristically Accelerating EarlyBird Convergence
Adithya Vasudev
The Lottery Ticket hypothesis proposes that ideal sparse subnetworks called lottery tickets exist in the untrained dense network. The Early Bird hypothesis proposes an efficient algorithm to find these winning lottery tickets in convolutional neural networks using the novel concept of distance between subnetworks to detect convergence in the subnetworks of a model. However, this approach overlooks unchanging groups of unimportant neurons near the end of the search. We propose WORM, a method that exploits these static groups by truncating their gradients, forcing the model to rely on other neurons. Experiments show WORM achieves faster ticket identification training and uses fewer FLOPs, despite the additional computational overhead. Additionally WORM pruned models lose less accuracy during pruning and recover accuracy faster, improving the robustness of the model. Furthermore, WORM is also able to generalize the Early Bird hypothesis reasonably well to larger models such as transformers, displaying its flexibility to adapt to various architectures.
Read more6/19/2024
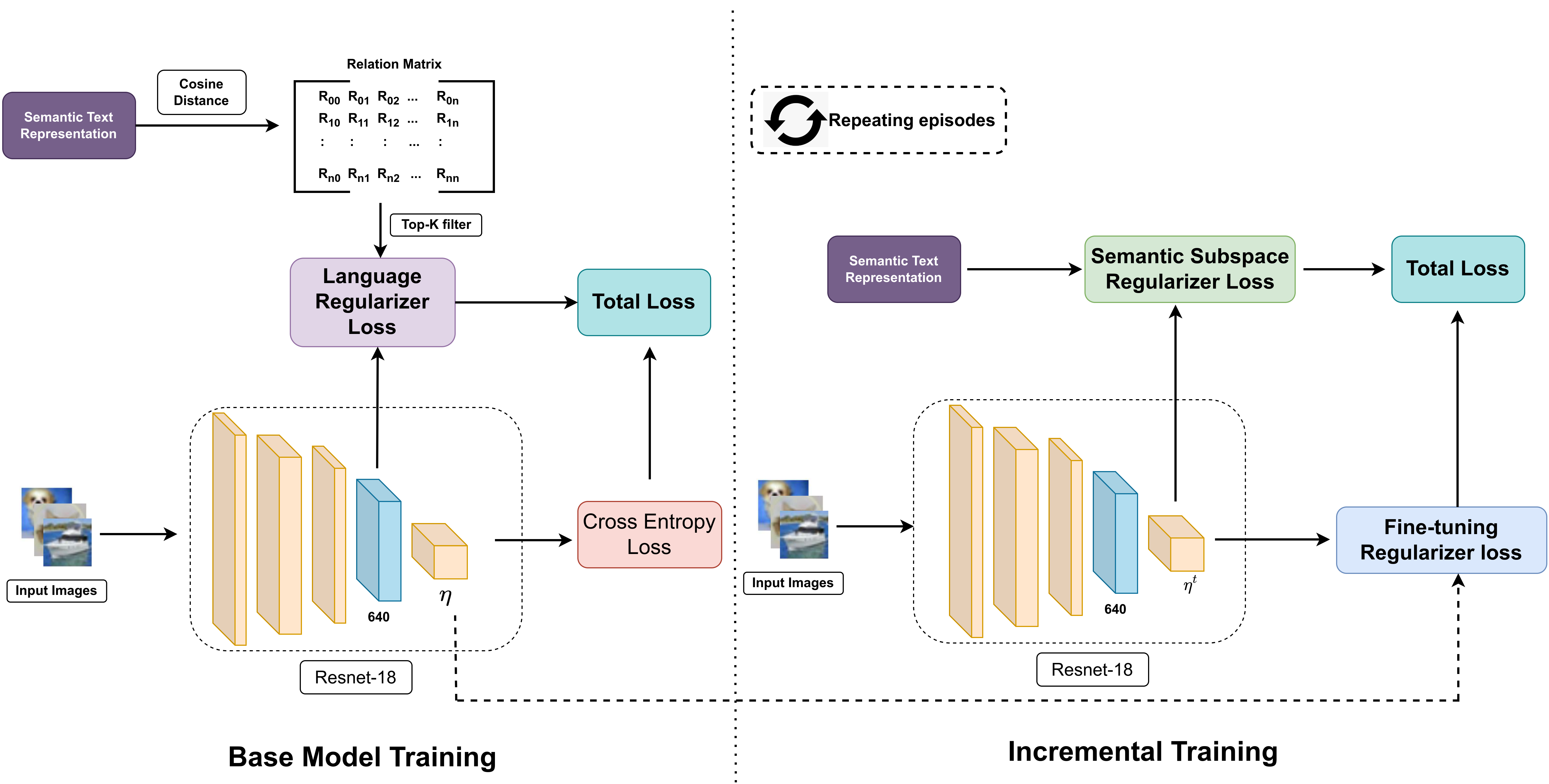
0
Few Shot Class Incremental Learning using Vision-Language models
Anurag Kumar, Chinmay Bharti, Saikat Dutta, Srikrishna Karanam, Biplab Banerjee
Recent advancements in deep learning have demonstrated remarkable performance comparable to human capabilities across various supervised computer vision tasks. However, the prevalent assumption of having an extensive pool of training data encompassing all classes prior to model training often diverges from real-world scenarios, where limited data availability for novel classes is the norm. The challenge emerges in seamlessly integrating new classes with few samples into the training data, demanding the model to adeptly accommodate these additions without compromising its performance on base classes. To address this exigency, the research community has introduced several solutions under the realm of few-shot class incremental learning (FSCIL). In this study, we introduce an innovative FSCIL framework that utilizes language regularizer and subspace regularizer. During base training, the language regularizer helps incorporate semantic information extracted from a Vision-Language model. The subspace regularizer helps in facilitating the model's acquisition of nuanced connections between image and text semantics inherent to base classes during incremental training. Our proposed framework not only empowers the model to embrace novel classes with limited data, but also ensures the preservation of performance on base classes. To substantiate the efficacy of our approach, we conduct comprehensive experiments on three distinct FSCIL benchmarks, where our framework attains state-of-the-art performance.
Read more8/16/2024