Continual Deep Learning on the Edge via Stochastic Local Competition among Subnetworks

0

Sign in to get full access
Overview
- This paper introduces a novel approach called "Continual Deep Learning on the Edge via Stochastic Local Competition among Subnetworks" that enables efficient continual learning on edge devices with limited memory.
- The key ideas include using stochastic local competition among subnetworks to selectively update only the necessary parts of the model during training, and leveraging decentralized asynchronous training to efficiently utilize resources across heterogeneous edge devices.
- The proposed method is designed to address the challenges of continual learning on resource-constrained edge devices, such as avoiding catastrophic forgetting and enabling efficient use of limited memory.
Plain English Explanation
The paper describes a way to enable continual learning - the ability for an AI model to continuously learn and adapt over time - on edge devices like smartphones or sensors. These devices often have limited memory and computing power, which makes continual learning a challenge.
The key idea is to have the model break itself up into smaller "subnetworks" that can compete with each other to be updated during training. This stochastic local competition allows the model to selectively update only the parts that are necessary, rather than having to update the entire model. This helps conserve the limited memory on the edge device.
The paper also describes a way to decentralize the training across multiple edge devices, allowing them to collaborate and share the workload asynchronously. This helps make efficient use of the available computing resources on the edge.
Overall, the proposed approach aims to enable continual learning on resource-constrained edge devices, which could have applications in areas like video analysis or IoT sensor networks.
Technical Explanation
The paper introduces a novel continual learning approach called "Continual Deep Learning on the Edge via Stochastic Local Competition among Subnetworks". The key components of the proposed method are:
-
Subnetwork Competition: The deep learning model is divided into smaller "subnetworks" that compete with each other in a stochastic manner during training. This allows the model to selectively update only the necessary parts, rather than having to update the entire model, which helps conserve memory on the edge device.
-
Decentralized Asynchronous Training: The training process is decentralized across multiple edge devices, allowing them to collaborate and share the workload asynchronously. This helps make efficient use of the available computing resources on the edge, even when the devices are heterogeneous.
The authors evaluate their approach on several continual learning benchmarks and show that it outperforms existing methods in terms of memory efficiency and performance, while also enabling low-latency inference on edge devices.
Critical Analysis
The paper presents a promising approach to addressing the challenges of continual learning on resource-constrained edge devices. The use of stochastic local competition among subnetworks and decentralized asynchronous training are novel and well-designed strategies to overcome the limitations of edge computing.
However, the paper does not discuss some potential limitations or areas for further research. For example, the impact of the subnetwork competition mechanism on model performance and stability over long-term continual learning scenarios is not fully explored. Additionally, the paper does not address the challenges of communication overhead and synchronization in the decentralized training setup, which could be important considerations for real-world deployments.
Furthermore, the authors could have provided a more thorough discussion of the potential use cases and societal implications of their approach, beyond the technical details. Exploring how this technology could be applied in domains like video analysis, IoT sensor networks, or other edge computing scenarios would help readers better understand the broader significance of the research.
Conclusion
The proposed "Continual Deep Learning on the Edge via Stochastic Local Competition among Subnetworks" approach represents an important step forward in enabling efficient continual learning on resource-constrained edge devices. By leveraging stochastic subnetwork competition and decentralized asynchronous training, the method can overcome the memory and computing limitations of edge devices while maintaining high performance.
The key innovations of this work, including the selective model updates and collaborative training across heterogeneous devices, could have significant implications for a wide range of edge computing applications, from smart home sensors to autonomous vehicles. As edge devices continue to play an increasingly important role in our digital lives, the ability to perform continual learning on these platforms will be crucial for developing adaptive, personalized, and efficient AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Continual Deep Learning on the Edge via Stochastic Local Competition among Subnetworks
Theodoros Christophides, Kyriakos Tolias, Sotirios Chatzis
Continual learning on edge devices poses unique challenges due to stringent resource constraints. This paper introduces a novel method that leverages stochastic competition principles to promote sparsity, significantly reducing deep network memory footprint and computational demand. Specifically, we propose deep networks that comprise blocks of units that compete locally to win the representation of each arising new task; competition takes place in a stochastic manner. This type of network organization results in sparse task-specific representations from each network layer; the sparsity pattern is obtained during training and is different among tasks. Crucially, our method sparsifies both the weights and the weight gradients, thus facilitating training on edge devices. This is performed on the grounds of winning probability for each unit in a block. During inference, the network retains only the winning unit and zeroes-out all weights pertaining to non-winning units for the task at hand. Thus, our approach is specifically tailored for deployment on edge devices, providing an efficient and scalable solution for continual learning in resource-limited environments.
Read more7/16/2024

0
Redundancy-Aware Efficient Continual Learning on Edge Devices
Sheng Li, Geng Yuan, Yawen Wu, Yue Dai, Tianyu Wang, Chao Wu, Alex K. Jones, Jingtong Hu, Yanzhi Wang, Xulong Tang
Many emerging applications, such as robot-assisted eldercare and object recognition, generally employ deep learning neural networks (DNNs) and require the deployment of DNN models on edge devices. These applications naturally require i) handling streaming-in inference requests and ii) fine-tuning the deployed models to adapt to possible deployment scenario changes. Continual learning (CL) is widely adopted to satisfy these needs. CL is a popular deep learning paradigm that handles both continuous model fine-tuning and overtime inference requests. However, an inappropriate model fine-tuning scheme could involve significant redundancy and consume considerable time and energy, making it challenging to apply CL on edge devices. In this paper, we propose ETuner, an efficient edge continual learning framework that optimizes inference accuracy, fine-tuning execution time, and energy efficiency through both inter-tuning and intra-tuning optimizations. Experimental results show that, on average, ETuner reduces overall fine-tuning execution time by 64%, energy consumption by 56%, and improves average inference accuracy by 1.75% over the immediate model fine-tuning approach.
Read more8/26/2024

0
Efficient Continual Learning with Low Memory Footprint For Edge Device
Zeqing Wang, Fei Cheng, Kangye Ji, Bohu Huang
Continual learning(CL) is a useful technique to acquire dynamic knowledge continually. Although powerful cloud platforms can fully exert the ability of CL,e.g., customized recommendation systems, similar personalized requirements for edge devices are almost disregarded. This phenomenon stems from the huge resource overhead involved in training neural networks and overcoming the forgetting problem of CL. This paper focuses on these scenarios and proposes a compact algorithm called LightCL. Different from other CL methods bringing huge resource consumption to acquire generalizability among all tasks for delaying forgetting, LightCL compress the resource consumption of already generalized components in neural networks and uses a few extra resources to improve memory in other parts. We first propose two new metrics of learning plasticity and memory stability to seek generalizability during CL. Based on the discovery that lower and middle layers have more generalizability and deeper layers are opposite, we $textit{Maintain Generalizability}$ by freezing the lower and middle layers. Then, we $textit{Memorize Feature Patterns}$ to stabilize the feature extracting patterns of previous tasks to improve generalizability in deeper layers. In the experimental comparison, LightCL outperforms other SOTA methods in delaying forgetting and reduces at most $textbf{6.16$times$}$ memory footprint, proving the excellent performance of LightCL in efficiency. We also evaluate the efficiency of our method on an edge device, the Jetson Nano, which further proves our method's practical effectiveness.
Read more7/18/2024
0
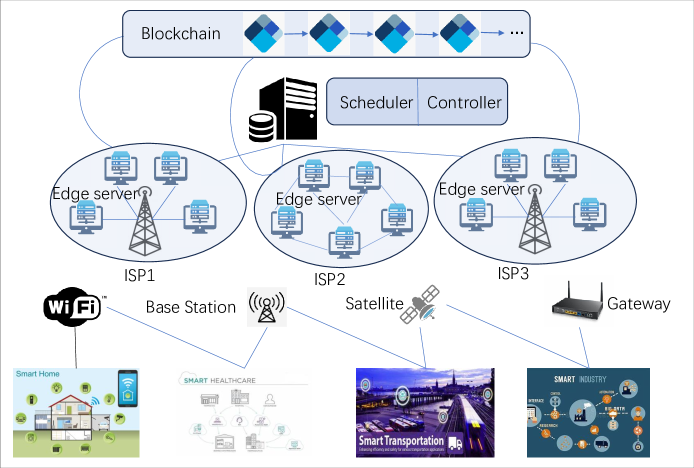
A proof of contribution in blockchain using game theoretical deep learning model
Jin Wang
Building elastic and scalable edge resources is an inevitable prerequisite for providing platform-based smart city services. Smart city services are delivered through edge computing to provide low-latency applications. However, edge computing has always faced the challenge of limited resources. A single edge device cannot undertake the various intelligent computations in a smart city, and the large-scale deployment of edge devices from different service providers to build an edge resource platform has become a necessity. Selecting computing power from different service providers is a game-theoretic problem. To incentivize service providers to actively contribute their valuable resources and provide low-latency collaborative computing power, we introduce a game-theoretic deep learning model to reach a consensus among service providers on task scheduling and resource provisioning. Traditional centralized resource management approaches are inefficient and lack credibility, while the introduction of blockchain technology can enable decentralized resource trading and scheduling. We propose a contribution-based proof mechanism to provide the low-latency service of edge computing. The deep learning model consists of dual encoders and a single decoder, where the GNN (Graph Neural Network) encoder processes structured decision action data, and the RNN (Recurrent Neural Network) encoder handles time-series task scheduling data. Extensive experiments have demonstrated that our model reduces latency by 584% compared to the state-of-the-art.
Read more9/14/2024