Continual Learning in the Presence of Repetition
2405.04101
0
0

Abstract
Continual learning (CL) provides a framework for training models in ever-evolving environments. Although re-occurrence of previously seen objects or tasks is common in real-world problems, the concept of repetition in the data stream is not often considered in standard benchmarks for CL. Unlike with the rehearsal mechanism in buffer-based strategies, where sample repetition is controlled by the strategy, repetition in the data stream naturally stems from the environment. This report provides a summary of the CLVision challenge at CVPR 2023, which focused on the topic of repetition in class-incremental learning. The report initially outlines the challenge objective and then describes three solutions proposed by finalist teams that aim to effectively exploit the repetition in the stream to learn continually. The experimental results from the challenge highlight the effectiveness of ensemble-based solutions that employ multiple versions of similar modules, each trained on different but overlapping subsets of classes. This report underscores the transformative potential of taking a different perspective in CL by employing repetition in the data stream to foster innovative strategy design.
Create account to get full access
Overview
- This paper explores the challenge of continual learning in the presence of repetition, where an AI system must learn new tasks while retaining knowledge from previous tasks.
- The authors propose a novel approach called Adaptive Memory Replay that aims to address this challenge.
- The research also examines the impact of pre-trained models on continual learning performance.
Plain English Explanation
The paper looks at a problem faced by AI systems that need to keep learning new things while also remembering what they've learned before. Imagine a robot that starts out knowing how to do basic tasks, then needs to learn new skills over time, like cleaning, cooking, and providing medical assistance. As the robot keeps learning, it needs to retain the knowledge it gained from earlier tasks.
The authors propose a technique called Adaptive Memory Replay to help the AI system remember what it's learned. This involves selectively replaying and updating the robot's memories to reinforce the important information. The research also examines how using pre-trained models, which are AI systems that have already learned a lot of general knowledge, can help the robot learn new skills more efficiently.
The key ideas are to have the AI system focus on retaining the most important information it's learned, and to leverage pre-existing knowledge to make learning new tasks easier. This can help AI systems become more robust and capable of continuous learning, just like how humans are able to build on their existing knowledge to acquire new skills over time.
Technical Explanation
The paper introduces the challenge of continual learning in the presence of repetition, where an AI model must learn new tasks while preserving knowledge from previous tasks. To address this, the authors propose an approach called Adaptive Memory Replay (AMR).
AMR works by selectively replaying and updating a model's memory of past experiences. This allows the model to continuously refine its knowledge without catastrophically forgetting previous information. The authors also investigate the impact of using pre-trained models on continual learning performance, finding that pre-training can significantly boost the model's ability to learn new tasks.
The paper includes experimental results on benchmark continual learning datasets, demonstrating AMR's effectiveness in mitigating catastrophic forgetting compared to other continual learning methods. The authors also analyze the tradeoffs between memory utilization and performance, and discuss the implications of their findings for the development of robust, lifelong learning AI systems.
Critical Analysis
The paper presents a compelling approach to the challenging problem of continual learning in the presence of repetition. The authors' Adaptive Memory Replay technique offers a promising solution by selectively replaying and updating the model's memory, which helps preserve past knowledge while acquiring new skills.
One potential limitation is that the paper does not thoroughly explore the computational and memory overhead required by AMR, which could be an important practical consideration for real-world deployment. Additionally, the authors acknowledge that their experiments were conducted on relatively simple benchmark datasets, and further research would be needed to validate the approach on more complex, real-world tasks.
Another area for further investigation is the interplay between the pre-training strategy and the continual learning algorithms. The paper demonstrates the benefits of leveraging pre-trained models, but does not delve into the optimal way to integrate pre-training with continual learning techniques like AMR.
Overall, the research represents an important step forward in addressing the challenge of continual learning, and the authors' insights and proposed methods merit further exploration and refinement to create truly robust, lifelong learning AI systems.
Conclusion
This paper tackles the important challenge of continual learning in the presence of repetition, where AI systems must continuously acquire new skills while preserving their existing knowledge. The authors' Adaptive Memory Replay approach offers a promising solution, selectively replaying and updating the model's memories to mitigate catastrophic forgetting.
The research also highlights the value of leveraging pre-trained models to bootstrap the continual learning process, leading to improved performance. While further work is needed to fully understand the practical implications and limitations of the proposed techniques, this paper represents an important contribution to the field of lifelong, robust learning for AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Adaptive Memory Replay for Continual Learning
James Seale Smith, Lazar Valkov, Shaunak Halbe, Vyshnavi Gutta, Rogerio Feris, Zsolt Kira, Leonid Karlinsky
0
0
Foundation Models (FMs) have become the hallmark of modern AI, however, these models are trained on massive data, leading to financially expensive training. Updating FMs as new data becomes available is important, however, can lead to `catastrophic forgetting', where models underperform on tasks related to data sub-populations observed too long ago. This continual learning (CL) phenomenon has been extensively studied, but primarily in a setting where only a small amount of past data can be stored. We advocate for the paradigm where memory is abundant, allowing us to keep all previous data, but computational resources are limited. In this setting, traditional replay-based CL approaches are outperformed by a simple baseline which replays past data selected uniformly at random, indicating that this setting necessitates a new approach. We address this by introducing a framework of adaptive memory replay for continual learning, where sampling of past data is phrased as a multi-armed bandit problem. We utilize Bolzmann sampling to derive a method which dynamically selects past data for training conditioned on the current task, assuming full data access and emphasizing training efficiency. Through extensive evaluations on both vision and language pre-training tasks, we demonstrate the effectiveness of our approach, which maintains high performance while reducing forgetting by up to 10% at no training efficiency cost.
4/22/2024
✨
Brain-Inspired Continual Learning-Robust Feature Distillation and Re-Consolidation for Class Incremental Learning
Hikmat Khan, Nidhal Carla Bouaynaya, Ghulam Rasool
0
0
Artificial intelligence (AI) and neuroscience share a rich history, with advancements in neuroscience shaping the development of AI systems capable of human-like knowledge retention. Leveraging insights from neuroscience and existing research in adversarial and continual learning, we introduce a novel framework comprising two core concepts: feature distillation and re-consolidation. Our framework, named Robust Rehearsal, addresses the challenge of catastrophic forgetting inherent in continual learning (CL) systems by distilling and rehearsing robust features. Inspired by the mammalian brain's memory consolidation process, Robust Rehearsal aims to emulate the rehearsal of distilled experiences during learning tasks. Additionally, it mimics memory re-consolidation, where new experiences influence the integration of past experiences to mitigate forgetting. Extensive experiments conducted on CIFAR10, CIFAR100, and real-world helicopter attitude datasets showcase the superior performance of CL models trained with Robust Rehearsal compared to baseline methods. Furthermore, examining different optimization training objectives-joint, continual, and adversarial learning-we highlight the crucial role of feature learning in model performance. This underscores the significance of rehearsing CL-robust samples in mitigating catastrophic forgetting. In conclusion, aligning CL approaches with neuroscience insights offers promising solutions to the challenge of catastrophic forgetting, paving the way for more robust and human-like AI systems.
4/24/2024
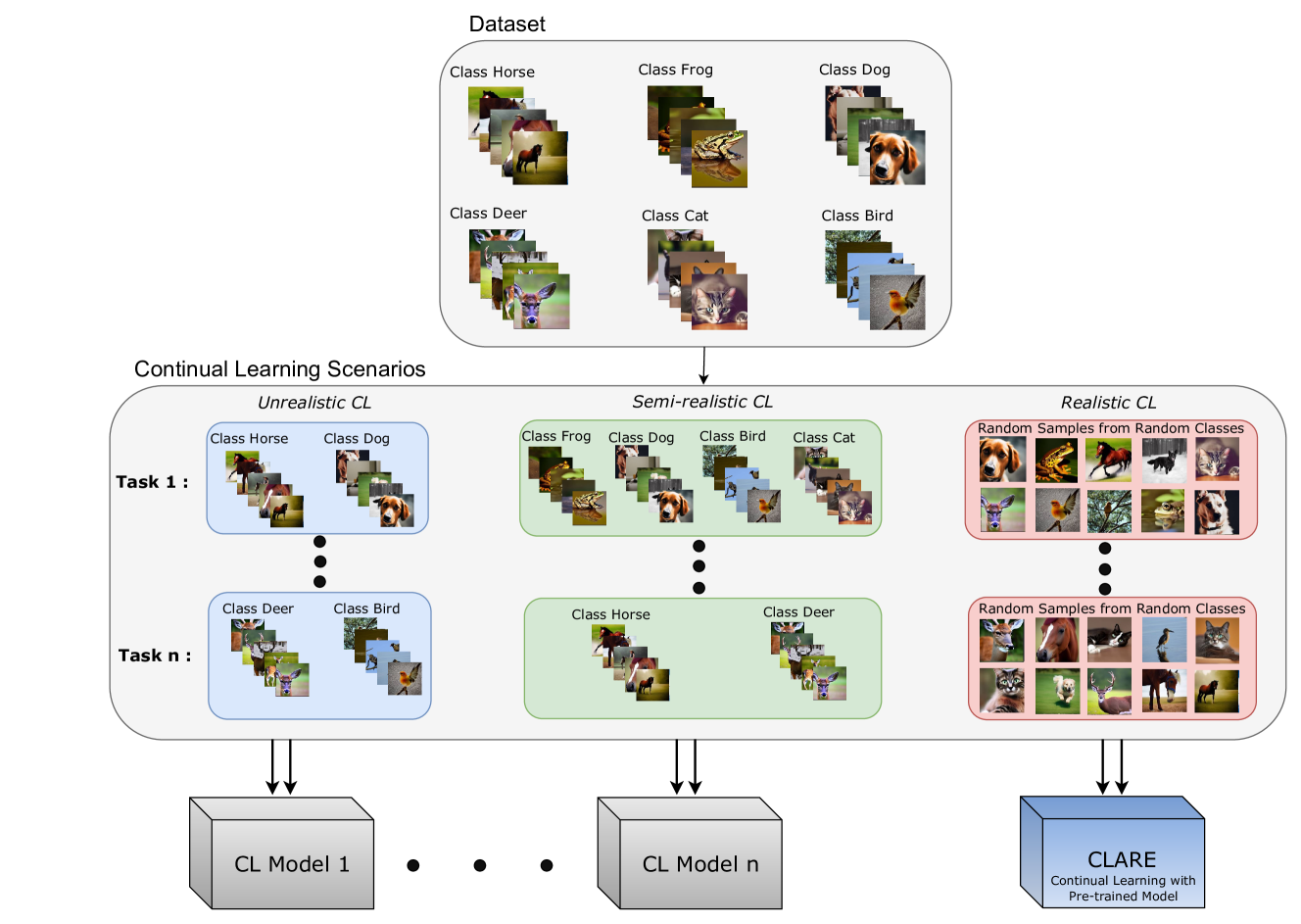
Realistic Continual Learning Approach using Pre-trained Models
Nadia Nasri, Carlos Guti'errez-'Alvarez, Sergio Lafuente-Arroyo, Saturnino Maldonado-Basc'on, Roberto J. L'opez-Sastre
0
0
Continual learning (CL) is crucial for evaluating adaptability in learning solutions to retain knowledge. Our research addresses the challenge of catastrophic forgetting, where models lose proficiency in previously learned tasks as they acquire new ones. While numerous solutions have been proposed, existing experimental setups often rely on idealized class-incremental learning scenarios. We introduce Realistic Continual Learning (RealCL), a novel CL paradigm where class distributions across tasks are random, departing from structured setups. We also present CLARE (Continual Learning Approach with pRE-trained models for RealCL scenarios), a pre-trained model-based solution designed to integrate new knowledge while preserving past learning. Our contributions include pioneering RealCL as a generalization of traditional CL setups, proposing CLARE as an adaptable approach for RealCL tasks, and conducting extensive experiments demonstrating its effectiveness across various RealCL scenarios. Notably, CLARE outperforms existing models on RealCL benchmarks, highlighting its versatility and robustness in unpredictable learning environments.
4/12/2024
🧠
Continual Learning with Pre-Trained Models: A Survey
Da-Wei Zhou, Hai-Long Sun, Jingyi Ning, Han-Jia Ye, De-Chuan Zhan
0
0
Nowadays, real-world applications often face streaming data, which requires the learning system to absorb new knowledge as data evolves. Continual Learning (CL) aims to achieve this goal and meanwhile overcome the catastrophic forgetting of former knowledge when learning new ones. Typical CL methods build the model from scratch to grow with incoming data. However, the advent of the pre-trained model (PTM) era has sparked immense research interest, particularly in leveraging PTMs' robust representational capabilities. This paper presents a comprehensive survey of the latest advancements in PTM-based CL. We categorize existing methodologies into three distinct groups, providing a comparative analysis of their similarities, differences, and respective advantages and disadvantages. Additionally, we offer an empirical study contrasting various state-of-the-art methods to highlight concerns regarding fairness in comparisons. The source code to reproduce these evaluations is available at: https://github.com/sun-hailong/LAMDA-PILOT
4/24/2024