Continual Learning with Pre-Trained Models: A Survey
2401.16386
0
0
🧠
Abstract
Nowadays, real-world applications often face streaming data, which requires the learning system to absorb new knowledge as data evolves. Continual Learning (CL) aims to achieve this goal and meanwhile overcome the catastrophic forgetting of former knowledge when learning new ones. Typical CL methods build the model from scratch to grow with incoming data. However, the advent of the pre-trained model (PTM) era has sparked immense research interest, particularly in leveraging PTMs' robust representational capabilities. This paper presents a comprehensive survey of the latest advancements in PTM-based CL. We categorize existing methodologies into three distinct groups, providing a comparative analysis of their similarities, differences, and respective advantages and disadvantages. Additionally, we offer an empirical study contrasting various state-of-the-art methods to highlight concerns regarding fairness in comparisons. The source code to reproduce these evaluations is available at: https://github.com/sun-hailong/LAMDA-PILOT
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a comprehensive survey of the latest advancements in Continual Learning (CL) using pre-trained models (PTMs).
- CL aims to help learning systems absorb new knowledge as data evolves, without forgetting former knowledge.
- Typical CL methods build models from scratch, but this paper focuses on leveraging the robust representational capabilities of PTMs.
- The paper categorizes existing PTM-based CL methodologies into three groups and provides a comparative analysis.
- It also includes an empirical study contrasting various state-of-the-art methods to highlight concerns regarding fairness in comparisons.
Plain English Explanation
In the real world, data is constantly changing, and learning systems need to be able to keep up. Continual Learning (CL) is a way for these systems to absorb new knowledge as data evolves, without forgetting what they've learned before.
Traditional CL methods start building the model from scratch, but this paper looks at a different approach - using pre-trained models (PTMs). PTMs have already been trained on a lot of data, so they have strong capabilities when it comes to representing information. The researchers in this paper wanted to see how they could use these pre-trained models to help with CL.
They looked at different ways that researchers have been using PTMs for CL, and grouped them into three main categories. The paper compares these different approaches, highlighting their similarities, differences, and the pros and cons of each one.
The researchers also did their own experiments, looking at how well different state-of-the-art CL methods using PTMs perform. They wanted to see if the comparisons between these methods were being done fairly.
Technical Explanation
The paper first provides an overview of CL and the rise of PTMs, which have sparked immense research interest in leveraging their robust representational capabilities for CL.
The main contribution of the paper is a comprehensive survey of the latest advancements in PTM-based CL. The authors categorize existing methodologies into three distinct groups:
- PTM-based Continual Learning: These approaches fine-tune the PTM on new tasks while mitigating catastrophic forgetting.
- Continual Learning of PTMs: These methods allow the PTM itself to continuously learn and evolve as new data becomes available.
- Continual Learning with PTMs: These techniques use PTMs as feature extractors or prompts to aid the continual learning of task-specific models.
For each category, the paper provides a comparative analysis of the similarities, differences, and respective advantages and disadvantages of the methodologies.
Additionally, the authors conduct an empirical study contrasting various state-of-the-art PTM-based CL methods. This analysis highlights concerns regarding the fairness of comparisons in the field, which the authors argue is an important consideration for further research.
Critical Analysis
The paper provides a thorough and well-structured survey of the latest advancements in PTM-based CL. However, it does not delve into the specific limitations or caveats of the surveyed approaches. For example, the paper does not discuss the computational and memory overhead associated with some of the CL methods that involve fine-tuning or modifying the PTM itself.
Furthermore, the paper's empirical study is limited to a small set of benchmark tasks and datasets. While this helps to highlight the comparability issues in the field, it would be valuable to see a more comprehensive evaluation across a wider range of real-world scenarios and applications.
Additionally, the paper does not address the ethical implications of continually learning systems, such as potential biases or fairness concerns that may arise as these models are exposed to evolving data and tasks.
Despite these limitations, the paper provides a valuable contribution to the field by synthesizing the current state of PTM-based CL and identifying important research directions, such as the need for more rigorous and standardized evaluation procedures.
Conclusion
This paper presents a comprehensive survey of the latest advancements in Continual Learning (CL) using pre-trained models (PTMs). The authors categorize existing methodologies into three distinct groups and provide a comparative analysis of their similarities, differences, and respective advantages and disadvantages.
The paper also includes an empirical study that highlights concerns regarding the fairness of comparisons in the field of PTM-based CL. This is an important consideration for future research, as it can help ensure that the performance of different CL methods is evaluated in a consistent and meaningful way.
Overall, this paper offers a valuable resource for researchers and practitioners interested in leveraging the power of PTMs to address the challenges of learning in dynamic, real-world environments. By synthesizing the current state of the field and identifying key research directions, the paper paves the way for further advancements in this rapidly evolving area of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Continual Learning of Large Language Models: A Comprehensive Survey
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Hao Wang
0
0
The recent success of large language models (LLMs) trained on static, pre-collected, general datasets has sparked numerous research directions and applications. One such direction addresses the non-trivial challenge of integrating pre-trained LLMs into dynamic data distributions, task structures, and user preferences. Pre-trained LLMs, when tailored for specific needs, often experience significant performance degradation in previous knowledge domains -- a phenomenon known as catastrophic forgetting. While extensively studied in the continual learning (CL) community, it presents new manifestations in the realm of LLMs. In this survey, we provide a comprehensive overview of the current research progress on LLMs within the context of CL. This survey is structured into four main sections: we first describe an overview of continually learning LLMs, consisting of two directions of continuity: vertical continuity (or vertical continual learning), i.e., continual adaptation from general to specific capabilities, and horizontal continuity (or horizontal continual learning), i.e., continual adaptation across time and domains (Section 3). We then summarize three stages of learning LLMs in the context of modern CL: Continual Pre-Training (CPT), Domain-Adaptive Pre-training (DAP), and Continual Fine-Tuning (CFT) (Section 4). Then we provide an overview of evaluation protocols for continual learning with LLMs, along with the current available data sources (Section 5). Finally, we discuss intriguing questions pertaining to continual learning for LLMs (Section 6). The full list of papers examined in this survey is available at https://github.com/Wang-ML-Lab/llm-continual-learning-survey.
4/26/2024
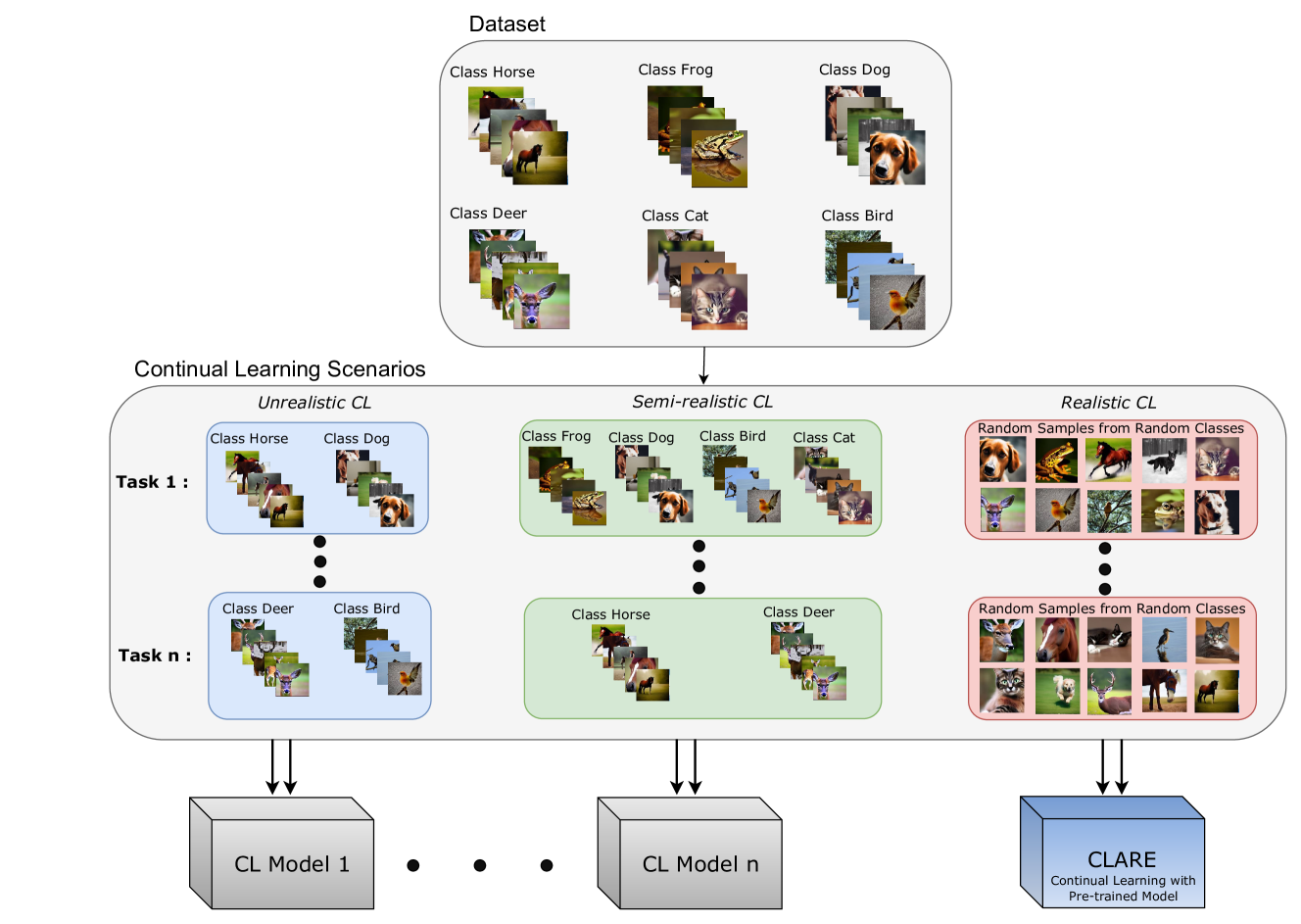
Realistic Continual Learning Approach using Pre-trained Models
Nadia Nasri, Carlos Guti'errez-'Alvarez, Sergio Lafuente-Arroyo, Saturnino Maldonado-Basc'on, Roberto J. L'opez-Sastre
0
0
Continual learning (CL) is crucial for evaluating adaptability in learning solutions to retain knowledge. Our research addresses the challenge of catastrophic forgetting, where models lose proficiency in previously learned tasks as they acquire new ones. While numerous solutions have been proposed, existing experimental setups often rely on idealized class-incremental learning scenarios. We introduce Realistic Continual Learning (RealCL), a novel CL paradigm where class distributions across tasks are random, departing from structured setups. We also present CLARE (Continual Learning Approach with pRE-trained models for RealCL scenarios), a pre-trained model-based solution designed to integrate new knowledge while preserving past learning. Our contributions include pioneering RealCL as a generalization of traditional CL setups, proposing CLARE as an adaptable approach for RealCL tasks, and conducting extensive experiments demonstrating its effectiveness across various RealCL scenarios. Notably, CLARE outperforms existing models on RealCL benchmarks, highlighting its versatility and robustness in unpredictable learning environments.
4/12/2024
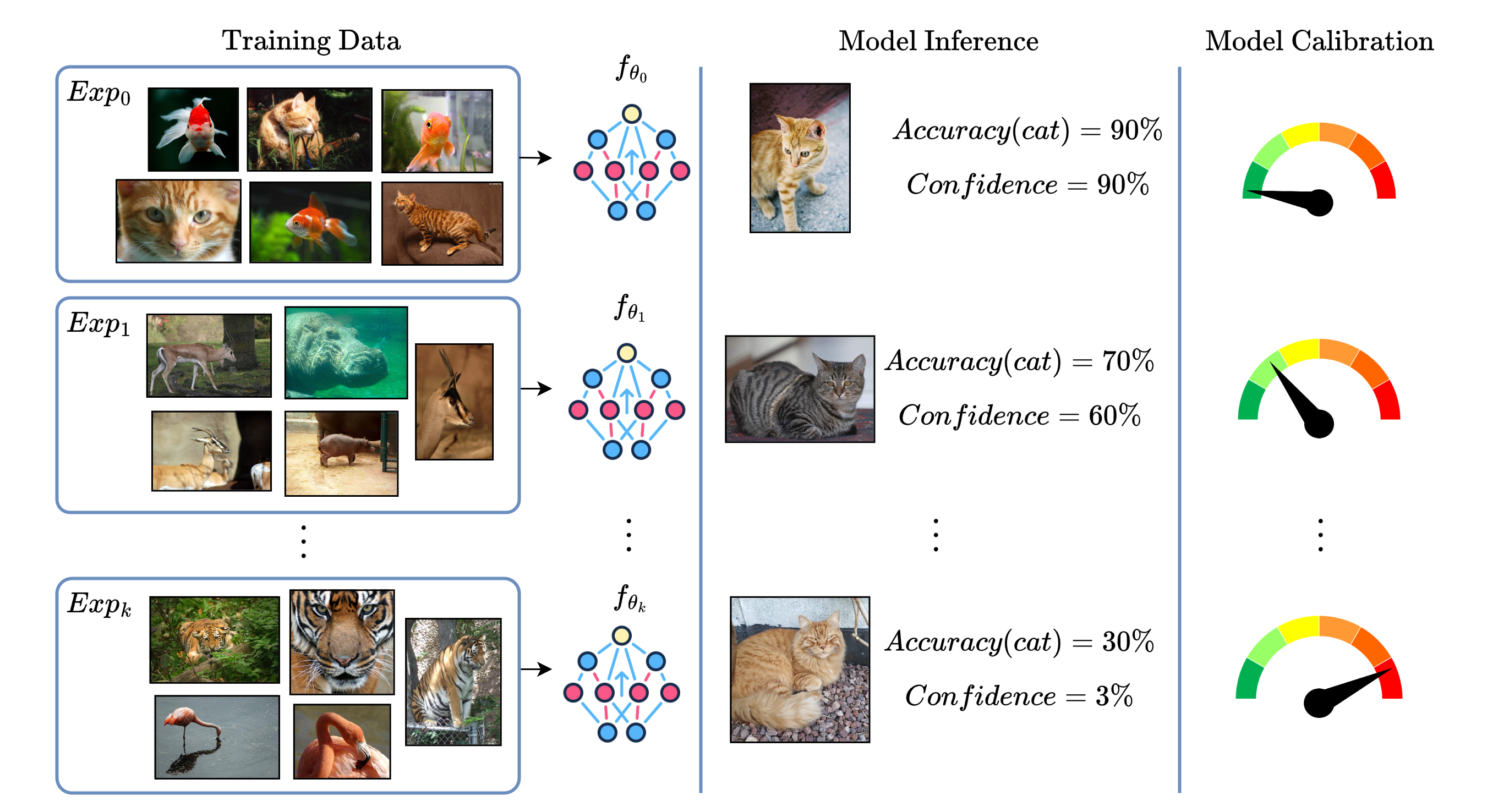
Calibration of Continual Learning Models
Lanpei Li, Elia Piccoli, Andrea Cossu, Davide Bacciu, Vincenzo Lomonaco
0
0
Continual Learning (CL) focuses on maximizing the predictive performance of a model across a non-stationary stream of data. Unfortunately, CL models tend to forget previous knowledge, thus often underperforming when compared with an offline model trained jointly on the entire data stream. Given that any CL model will eventually make mistakes, it is of crucial importance to build calibrated CL models: models that can reliably tell their confidence when making a prediction. Model calibration is an active research topic in machine learning, yet to be properly investigated in CL. We provide the first empirical study of the behavior of calibration approaches in CL, showing that CL strategies do not inherently learn calibrated models. To mitigate this issue, we design a continual calibration approach that improves the performance of post-processing calibration methods over a wide range of different benchmarks and CL strategies. CL does not necessarily need perfect predictive models, but rather it can benefit from reliable predictive models. We believe our study on continual calibration represents a first step towards this direction.
4/15/2024
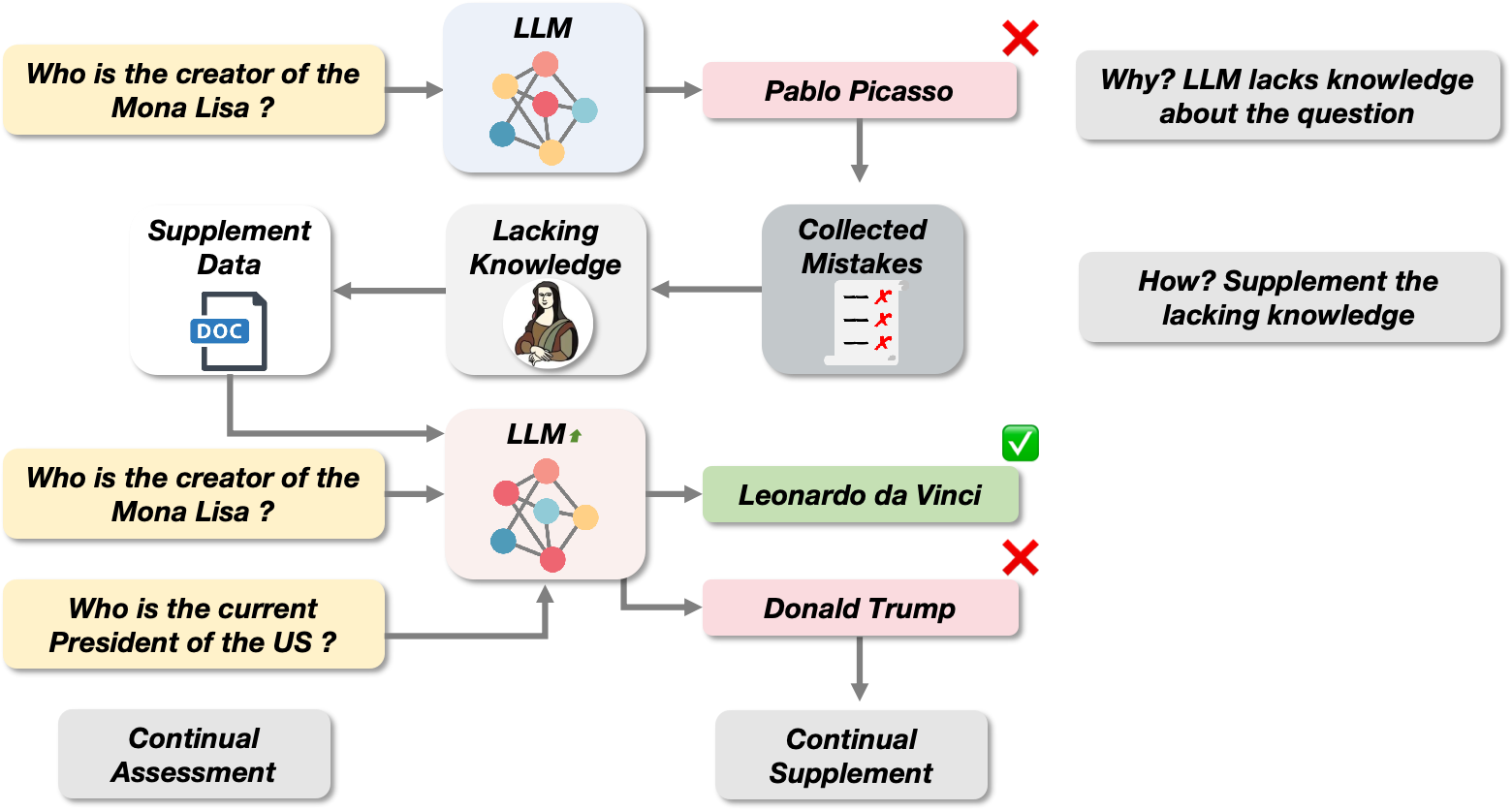
Large Language Model Can Continue Evolving From Mistakes
Haokun Zhao, Haixia Han, Jie Shi, Chengyu Du, Jiaqing Liang, Yanghua Xiao
0
0
Large Language Models (LLMs) demonstrate impressive performance in various downstream tasks. However, they may still generate incorrect responses in certain scenarios due to the knowledge deficiencies and the flawed pre-training data. Continual Learning (CL) is a commonly used method to address this issue. Traditional CL is task-oriented, using novel or factually accurate data to retrain LLMs from scratch. However, this method requires more task-related training data and incurs expensive training costs. To address this challenge, we propose the Continue Evolving from Mistakes (CEM) method, inspired by the 'summarize mistakes' learning skill, to achieve iterative refinement of LLMs. Specifically, the incorrect responses of LLMs indicate knowledge deficiencies related to the questions. Therefore, we collect corpora with these knowledge from multiple data sources and follow it up with iterative supplementary training for continuous, targeted knowledge updating and supplementation. Meanwhile, we developed two strategies to construct supplementary training sets to enhance the LLM's understanding of the corpus and prevent catastrophic forgetting. We conducted extensive experiments to validate the effectiveness of this CL method. In the best case, our method resulted in a 17.00% improvement in the accuracy of the LLM.
4/22/2024