Continual Test-time Adaptation for End-to-end Speech Recognition on Noisy Speech

0
Sign in to get full access
Overview
- The paper explores a method for continually adapting an end-to-end speech recognition model to noisy speech during test time.
- The approach aims to improve the model's performance on noisy speech without retraining or fine-tuning the model.
- The proposed method utilizes a task-aware adaptation module that learns to adapt the model's parameters based on the current input speech and noise conditions.
Plain English Explanation
Speech recognition models are trained on clean speech, but often struggle when faced with noisy real-world audio. This paper proposes a way to continuously adapt the speech recognition model during testing to improve its performance on noisy speech, without having to retrain or fine-tune the model.
The key idea is to use an additional "adaptation module" that learns how to modify the model's internal parameters based on the current speech input and noise conditions. This allows the model to continually adjust itself to handle different types and levels of noise, without requiring any labeled noisy speech data for retraining.
The adaptation module is trained in an unsupervised way to learn how to transform the model's parameters to better match the characteristics of the input speech and noise. This means the model can be deployed in the real world and continuously improve its performance on the fly, without the need for manual retraining or fine-tuning by the user.
The proposed approach aims to make speech recognition more robust and practical for real-world applications, where noise is a common challenge. By providing a way to dynamically adapt the model during use, it could help speech recognition systems work more reliably in noisy environments.
Technical Explanation
The paper introduces a method for Continual Test-time Adaptation (CTA) of end-to-end speech recognition models. The key component is a task-aware adaptation module that learns to transform the model's internal parameters based on the characteristics of the current speech input and noise conditions.
The adaptation module is trained in an unsupervised manner using the clean speech data used to train the original speech recognition model. It learns to predict how the model's parameters should be modified to improve performance on noisy speech, without requiring any labeled noisy speech data.
During test time, the adaptation module takes the current speech input and dynamically adjusts the speech recognition model's parameters to better handle the noise present in the input. This continual adaptation allows the model to maintain high performance even as the noise conditions change.
The authors evaluate their approach on multiple noisy speech benchmarks and show that it can significantly improve the speech recognition accuracy compared to the baseline model trained only on clean speech. The adaptation module is able to learn effective parameter transformations that make the model more robust to diverse noise types and levels.
Critical Analysis
The paper presents a promising approach for improving the robustness of end-to-end speech recognition models to noisy speech. The continual test-time adaptation method is an interesting alternative to traditional fine-tuning or data augmentation techniques, which can be costly and labor-intensive.
One potential limitation of the proposed method is that it relies on the availability of clean speech data to train the adaptation module. In some real-world scenarios, clean speech data may be scarce or difficult to obtain. It would be valuable to explore ways to train the adaptation module in a more data-efficient manner, perhaps using synthetic noise or unsupervised learning techniques.
Additionally, the paper does not provide a detailed analysis of the computational overhead or inference latency introduced by the adaptation module. In deployment scenarios where real-time performance is critical, the additional computational cost may be a concern that needs to be carefully evaluated.
Overall, the Continual Test-time Adaptation approach is a compelling idea that could make speech recognition systems more robust and practical for real-world use. Further research to address the potential limitations and optimize the efficiency of the method would be valuable contributions to the field.
Conclusion
This paper presents a novel approach for improving the robustness of end-to-end speech recognition models to noisy speech. The key innovation is a continual test-time adaptation method that dynamically adjusts the model's internal parameters to better handle the noise characteristics of the current input.
By leveraging an unsupervised adaptation module, the proposed approach can continuously improve the model's performance on noisy speech without requiring any labeled noisy data or manual retraining. This makes the speech recognition system more practical and deployable in real-world environments, where noise is a common challenge.
The experimental results demonstrate the effectiveness of the Continual Test-time Adaptation method, showing significant improvements in speech recognition accuracy on noisy speech benchmarks. Further research to optimize the efficiency and expand the applicability of this approach could lead to more robust and reliable speech recognition systems for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Continual Test-time Adaptation for End-to-end Speech Recognition on Noisy Speech
Guan-Ting Lin, Wei-Ping Huang, Hung-yi Lee
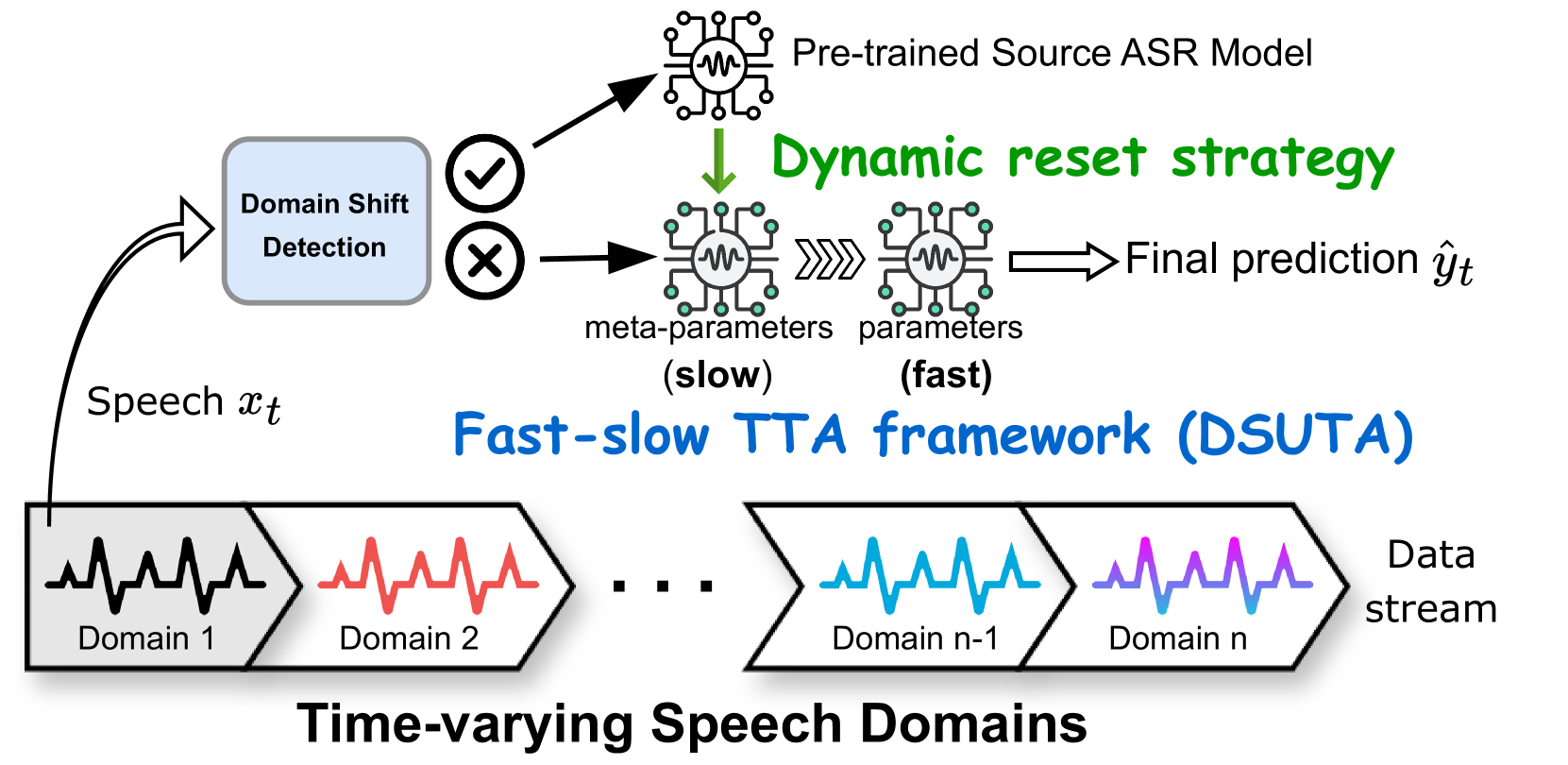
Deep learning-based end-to-end automatic speech recognition (ASR) has made significant strides but still struggles with performance on out-of-domain (OOD) samples due to domain shifts in real-world scenarios. Test-Time Adaptation (TTA) methods address this issue by adapting models using test samples at inference time. However, current ASR TTA methods have largely focused on non-continual TTA, which limits cross-sample knowledge learning compared to continual TTA. In this work, we propose a Fast-slow TTA framework for ASR, which leverages the advantage of continual and non-continual TTA. Within this framework, we introduce Dynamic SUTA (DSUTA), an entropy-minimization-based continual TTA method for ASR. To enhance DSUTA's robustness on time-varying data, we propose a dynamic reset strategy that automatically detects domain shifts and resets the model, making it more effective at handling multi-domain data. Our method demonstrates superior performance on various noisy ASR datasets, outperforming both non-continual and continual TTA baselines while maintaining robustness to domain changes without requiring domain boundary information.
Read more6/18/2024

0
LI-TTA: Language Informed Test-Time Adaptation for Automatic Speech Recognition
Eunseop Yoon, Hee Suk Yoon, John Harvill, Mark Hasegawa-Johnson, Chang D. Yoo
Test-Time Adaptation (TTA) has emerged as a crucial solution to the domain shift challenge, wherein the target environment diverges from the original training environment. A prime exemplification is TTA for Automatic Speech Recognition (ASR), which enhances model performance by leveraging output prediction entropy minimization as a self-supervision signal. However, a key limitation of this self-supervision lies in its primary focus on acoustic features, with minimal attention to the linguistic properties of the input. To address this gap, we propose Language Informed Test-Time Adaptation (LI-TTA), which incorporates linguistic insights during TTA for ASR. LI-TTA integrates corrections from an external language model to merge linguistic with acoustic information by minimizing the CTC loss from the correction alongside the standard TTA loss. With extensive experiments, we show that LI-TTA effectively improves the performance of TTA for ASR in various distribution shift situations.
Read more8/13/2024

0
Hybrid-TTA: Continual Test-time Adaptation via Dynamic Domain Shift Detection
Hyewon Park, Hyejin Park, Jueun Ko, Dongbo Min
Continual Test Time Adaptation (CTTA) has emerged as a critical approach for bridging the domain gap between the controlled training environments and the real-world scenarios, enhancing model adaptability and robustness. Existing CTTA methods, typically categorized into Full-Tuning (FT) and Efficient-Tuning (ET), struggle with effectively addressing domain shifts. To overcome these challenges, we propose Hybrid-TTA, a holistic approach that dynamically selects instance-wise tuning method for optimal adaptation. Our approach introduces the Dynamic Domain Shift Detection (DDSD) strategy, which identifies domain shifts by leveraging temporal correlations in input sequences and dynamically switches between FT and ET to adapt to varying domain shifts effectively. Additionally, the Masked Image Modeling based Adaptation (MIMA) framework is integrated to ensure domain-agnostic robustness with minimal computational overhead. Our Hybrid-TTA achieves a notable 1.6%p improvement in mIoU on the Cityscapes-to-ACDC benchmark dataset, surpassing previous state-of-the-art methods and offering a robust solution for real-world continual adaptation challenges.
Read more9/16/2024

0
Personalized Speech Recognition for Children with Test-Time Adaptation
Zhonghao Shi, Harshvardhan Srivastava, Xuan Shi, Shrikanth Narayanan, Maja J. Matari'c
Accurate automatic speech recognition (ASR) for children is crucial for effective real-time child-AI interaction, especially in educational applications. However, off-the-shelf ASR models primarily pre-trained on adult data tend to generalize poorly to children's speech due to the data domain shift from adults to children. Recent studies have found that supervised fine-tuning on children's speech data can help bridge this domain shift, but human annotations may be impractical to obtain for real-world applications and adaptation at training time can overlook additional domain shifts occurring at test time. We devised a novel ASR pipeline to apply unsupervised test-time adaptation (TTA) methods for child speech recognition, so that ASR models pre-trained on adult speech can be continuously adapted to each child speaker at test time without further human annotations. Our results show that ASR models adapted with TTA methods significantly outperform the unadapted off-the-shelf ASR baselines both on average and statistically across individual child speakers. Our analysis also discovered significant data domain shifts both between child speakers and within each child speaker, which further motivates the need for test-time adaptation.
Read more9/24/2024