Contrastive Adversarial Training for Unsupervised Domain Adaptation

0

Sign in to get full access
Overview
- This paper presents a new method called "Contrastive Adversarial Training for Unsupervised Domain Adaptation" (CATUDA) that aims to improve the performance of machine learning models when applied to new, unlabeled datasets that are different from the original training data.
- The key idea is to use a contrastive learning approach, which encourages the model to learn representations that are similar for examples from the same domain but different for examples from different domains.
- This is combined with adversarial training, where the model is trained to confuse a domain discriminator that tries to predict which domain an example comes from.
- The authors demonstrate the effectiveness of CATUDA on several benchmark datasets, showing improved performance compared to previous unsupervised domain adaptation techniques.
Plain English Explanation
Machine learning models are often trained on one dataset, but then need to be applied to new, unlabeled datasets that may have different characteristics. This is known as the "domain adaptation" problem. Adapting to distribution shift by visual domain and Zero-Shot Domain Adaptation Based on Dual-Level Representation Transfer are examples of previous techniques that have been proposed to address this challenge.
The key insight of this new method, CATUDA, is to use a "contrastive" approach, where the model is trained to make representations of examples from the same domain more similar, and representations of examples from different domains more different. This is combined with "adversarial" training, where the model is also trained to confuse a separate module that tries to predict which domain an example comes from.
The intuition is that by learning representations that are domain-invariant in this way, the model will be better able to generalize to new datasets, even if they have different characteristics from the original training data. The authors show that this CATUDA approach outperforms previous unsupervised domain adaptation techniques on several benchmark datasets, indicating it is a promising new method for this important problem.
Technical Explanation
The paper introduces a new unsupervised domain adaptation method called "Contrastive Adversarial Training for Unsupervised Domain Adaptation" (CATUDA). The key components are:
-
Contrastive Learning: The model is trained to learn representations that are similar for examples from the same domain, but different for examples from different domains. This is achieved by adding a contrastive loss term that encourages this property.
-
Adversarial Training: The model is also trained to confuse a domain discriminator network that tries to predict which domain an example comes from. This adversarial loss term encourages the learned representations to be domain-invariant.
-
Joint Optimization: The contrastive and adversarial loss terms are combined and jointly optimized with the standard classification loss, encouraging the model to learn representations that are both discriminative and domain-invariant.
The authors evaluate CATUDA on several benchmark datasets for unsupervised domain adaptation, including self-degraded contrastive domain adaptation for industrial fault, DACAD: Domain Adaptation via Contrastive Learning for Anomaly Detection, and OFFICE-31. The results show that CATUDA outperforms previous state-of-the-art unsupervised domain adaptation techniques, demonstrating the effectiveness of the combined contrastive and adversarial training approach.
Critical Analysis
The paper provides a thorough evaluation of the CATUDA method and discusses several limitations and avenues for future work:
-
Computational Complexity: The authors note that the contrastive and adversarial training components added to the standard classification training can increase the computational complexity and training time of the overall system.
-
Hyperparameter Tuning: The performance of CATUDA seems to be sensitive to the choice of hyperparameters, such as the relative weighting of the different loss terms. Robust hyperparameter tuning may be required for optimal performance.
-
Theoretical Understanding: While the empirical results are promising, the authors acknowledge that a deeper theoretical understanding of why the combined contrastive and adversarial training approach is effective for unsupervised domain adaptation would be valuable.
-
Real-world Applicability: The experiments in the paper are conducted on standard benchmark datasets. Further research is needed to evaluate the performance of CATUDA on more diverse, real-world domain adaptation tasks, such as TOCOAD: Two-Stage Contrastive Learning for Industrial Anomaly Detection.
Overall, the CATUDA method represents an interesting and promising new approach to unsupervised domain adaptation, but additional research is needed to fully understand its strengths, limitations, and practical implications.
Conclusion
This paper introduces a new unsupervised domain adaptation method called "Contrastive Adversarial Training for Unsupervised Domain Adaptation" (CATUDA). The key idea is to combine contrastive learning, which encourages the model to learn representations that are similar for examples from the same domain but different for examples from different domains, with adversarial training, which trains the model to confuse a domain discriminator.
The authors demonstrate the effectiveness of CATUDA on several benchmark datasets, showing improved performance compared to previous unsupervised domain adaptation techniques. While the paper highlights some limitations and areas for future research, the CATUDA approach represents an intriguing new direction for addressing the important problem of domain adaptation in machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Contrastive Adversarial Training for Unsupervised Domain Adaptation
Jiahong Chen, Zhilin Zhang, Lucy Li, Behzad Shahrasbi, Arjun Mishra
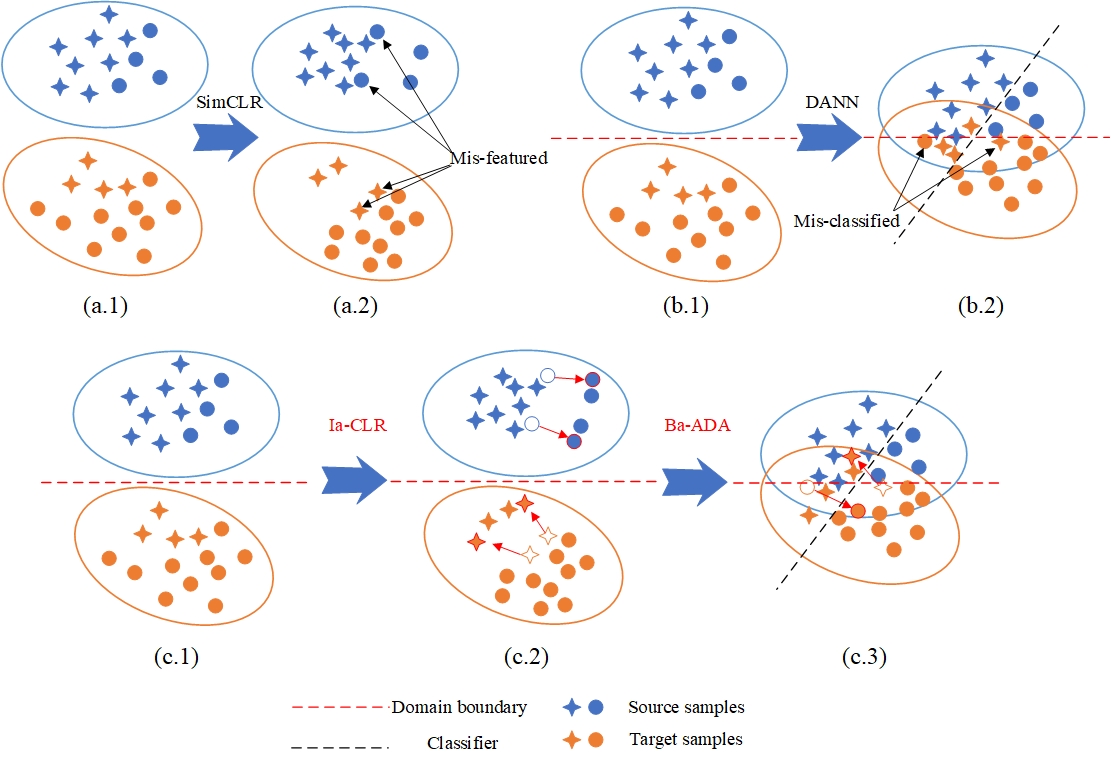
Domain adversarial training has shown its effective capability for finding domain invariant feature representations and been successfully adopted for various domain adaptation tasks. However, recent advances of large models (e.g., vision transformers) and emerging of complex adaptation scenarios (e.g., DomainNet) make adversarial training being easily biased towards source domain and hardly adapted to target domain. The reason is twofold: relying on large amount of labelled data from source domain for large model training and lacking of labelled data from target domain for fine-tuning. Existing approaches widely focused on either enhancing discriminator or improving the training stability for the backbone networks. Due to unbalanced competition between the feature extractor and the discriminator during the adversarial training, existing solutions fail to function well on complex datasets. To address this issue, we proposed a novel contrastive adversarial training (CAT) approach that leverages the labeled source domain samples to reinforce and regulate the feature generation for target domain. Typically, the regulation forces the target feature distribution being similar to the source feature distribution. CAT addressed three major challenges in adversarial learning: 1) ensure the feature distributions from two domains as indistinguishable as possible for the discriminator, resulting in a more robust domain-invariant feature generation; 2) encourage target samples moving closer to the source in the feature space, reducing the requirement for generalizing classifier trained on the labeled source domain to unlabeled target domain; 3) avoid directly aligning unpaired source and target samples within mini-batch. CAT can be easily plugged into existing models and exhibits significant performance improvements.
Read more7/18/2024
0
Self-degraded contrastive domain adaptation for industrial fault diagnosis with bi-imbalanced data
Gecheng Chen, Zeyu Yang, Chengwen Luo, Jianqiang Li
Modern industrial fault diagnosis tasks often face the combined challenge of distribution discrepancy and bi-imbalance. Existing domain adaptation approaches pay little attention to the prevailing bi-imbalance, leading to poor domain adaptation performance or even negative transfer. In this work, we propose a self-degraded contrastive domain adaptation (Sd-CDA) diagnosis framework to handle the domain discrepancy under the bi-imbalanced data. It first pre-trains the feature extractor via imbalance-aware contrastive learning based on model pruning to learn the feature representation efficiently in a self-supervised manner. Then it forces the samples away from the domain boundary based on supervised contrastive domain adversarial learning (SupCon-DA) and ensures the features generated by the feature extractor are discriminative enough. Furthermore, we propose the pruned contrastive domain adversarial learning (PSupCon-DA) to pay automatically re-weighted attention to the minorities to enhance the performance towards bi-imbalanced data. We show the superiority of the proposed method via two experiments.
Read more6/3/2024
0
DACAD: Domain Adaptation Contrastive Learning for Anomaly Detection in Multivariate Time Series
Zahra Zamanzadeh Darban, Yiyuan Yang, Geoffrey I. Webb, Charu C. Aggarwal, Qingsong Wen, Mahsa Salehi
In time series anomaly detection (TSAD), the scarcity of labeled data poses a challenge to the development of accurate models. Unsupervised domain adaptation (UDA) offers a solution by leveraging labeled data from a related domain to detect anomalies in an unlabeled target domain. However, existing UDA methods assume consistent anomalous classes across domains. To address this limitation, we propose a novel Domain Adaptation Contrastive learning model for Anomaly Detection in multivariate time series (DACAD), combining UDA with contrastive learning. DACAD utilizes an anomaly injection mechanism that enhances generalization across unseen anomalous classes, improving adaptability and robustness. Additionally, our model employs supervised contrastive loss for the source domain and self-supervised contrastive triplet loss for the target domain, ensuring comprehensive feature representation learning and domain-invariant feature extraction. Finally, an effective Centre-based Entropy Classifier (CEC) accurately learns normal boundaries in the source domain. Extensive evaluations on multiple real-world datasets and a synthetic dataset highlight DACAD's superior performance in transferring knowledge across domains and mitigating the challenge of limited labeled data in TSAD.
Read more7/12/2024
0
Adapting to Distribution Shift by Visual Domain Prompt Generation
Zhixiang Chi, Li Gu, Tao Zhong, Huan Liu, Yuanhao Yu, Konstantinos N Plataniotis, Yang Wang
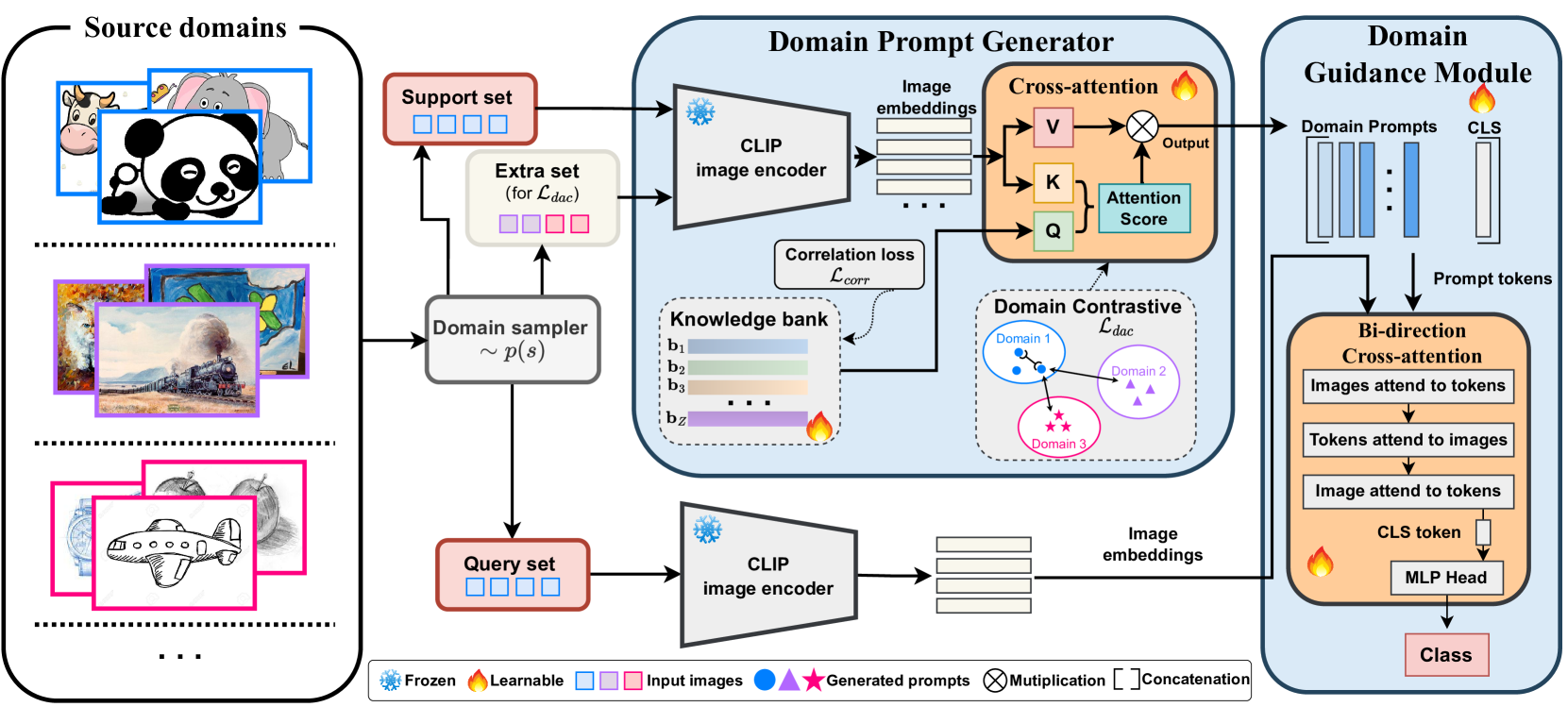
In this paper, we aim to adapt a model at test-time using a few unlabeled data to address distribution shifts. To tackle the challenges of extracting domain knowledge from a limited amount of data, it is crucial to utilize correlated information from pre-trained backbones and source domains. Previous studies fail to utilize recent foundation models with strong out-of-distribution generalization. Additionally, domain-centric designs are not flavored in their works. Furthermore, they employ the process of modelling source domains and the process of learning to adapt independently into disjoint training stages. In this work, we propose an approach on top of the pre-computed features of the foundation model. Specifically, we build a knowledge bank to learn the transferable knowledge from source domains. Conditioned on few-shot target data, we introduce a domain prompt generator to condense the knowledge bank into a domain-specific prompt. The domain prompt then directs the visual features towards a particular domain via a guidance module. Moreover, we propose a domain-aware contrastive loss and employ meta-learning to facilitate domain knowledge extraction. Extensive experiments are conducted to validate the domain knowledge extraction. The proposed method outperforms previous work on 5 large-scale benchmarks including WILDS and DomainNet.
Read more5/7/2024