Zero-shot domain adaptation based on dual-level mix and contrast

0
Sign in to get full access
Overview
- This paper proposes a "zero-shot domain adaptation" method that uses a combination of "mix-up" and "domain adversarial training" to enable machine learning models to perform well on new, unseen data domains without requiring labeled data from those domains.
- The key ideas are to 1) mix training data from different domains to create diverse synthetic samples, and 2) train the model to be invariant to domain shifts through adversarial learning.
- The authors demonstrate the effectiveness of their approach on several image classification benchmarks, showing it can outperform other state-of-the-art zero-shot domain adaptation methods.
Plain English Explanation
Machine learning models are often trained on data from one particular domain, like images of dogs and cats. But when you try to use that same model on a new domain, like images of birds, the model's performance can suffer. This is because the new domain has different characteristics than the original training data, and the model hasn't learned to handle that shift.
Zero-shot domain adaptation aims to solve this problem. The key idea is to train the model in a way that makes it more robust to domain shifts, so it can perform well on new, unseen data domains without requiring any labeled examples from those domains.
The approach proposed in this paper has two main components:
-
Mix-up: The researchers take training samples from different domains and "mix" them together to create new, synthetic training examples. This exposes the model to a wider variety of data during training, helping it learn features that generalize better across domains.
-
Domain adversarial training: The model is trained not just to perform well on the task (like classifying images), but also to be invariant to the domain the data comes from. This is done through an "adversarial" training process that encourages the model to learn features that are not specific to any one domain.
By combining these two techniques, the researchers were able to create a model that can adapt to new, unseen data domains without requiring any labeled examples from those domains. This "zero-shot" adaptation capability can be very useful in real-world applications where data from new domains is constantly emerging.
Technical Explanation
The key technical components of this approach are:
-
Mix-up: The researchers create new training samples by linearly interpolating between pairs of training examples from different domains. This exposes the model to a wider variety of data distributions during training, helping it learn more generalizable features.
-
Domain adversarial training: The model is trained to perform well on the target task (e.g., image classification) while also being trained to be invariant to the domain of the input data. This is achieved through an adversarial training process where a "domain classifier" network tries to predict the domain of the input, while the main model tries to learn features that confuse the domain classifier.
-
Dual-level mix and contrast: The researchers apply the mix-up and domain adversarial training at two levels: 1) at the input level, by mixing up the raw input samples, and 2) at the feature level, by mixing up the intermediate representations learned by the model.
-
Experiments: The researchers evaluate their approach on several image classification benchmarks, including Office-Home, VisDA-2017, and DomainNet. They show that their method outperforms other state-of-the-art zero-shot domain adaptation techniques.
Source-free domain adaptation, self-degraded contrastive domain adaptation, and style adaptation for domain-adaptive semantic segmentation are some related approaches that also aim to address the problem of domain shift in machine learning.
Critical Analysis
One potential limitation of this approach is that it assumes the source and target domains share some underlying similarities, which may not always be the case in real-world scenarios. The effectiveness of the mix-up and adversarial training components may depend on the degree of domain shift between the source and target data.
Additionally, the researchers only evaluate their method on image classification tasks, and it's unclear how well it would generalize to other types of data, such as text or audio. Overcoming negative transfer by online selection of distant is an example of a paper that explores domain adaptation in a wider range of settings.
Further research is needed to better understand the factors that influence the success of this approach, such as the optimal mix-up ratios, the role of the adversarial training component, and the generalizability to different types of machine learning problems.
Conclusion
This paper presents a novel zero-shot domain adaptation method that combines mix-up and domain adversarial training to enable machine learning models to perform well on new, unseen data domains without requiring any labeled examples from those domains. The experiments demonstrate the effectiveness of this approach on several image classification benchmarks, suggesting it could be a valuable tool for real-world applications where data from new domains is constantly emerging.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Zero-shot domain adaptation based on dual-level mix and contrast
Yu Zhe, Jun Sakuma
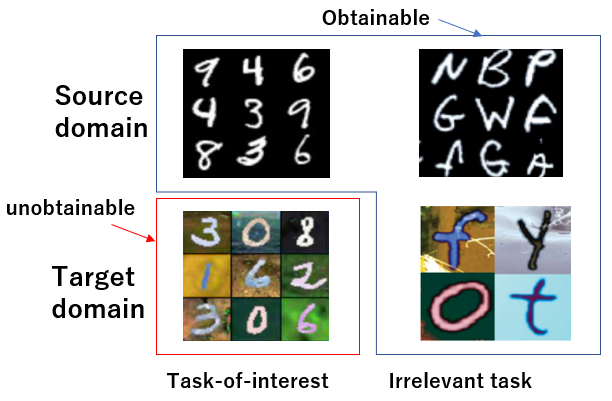
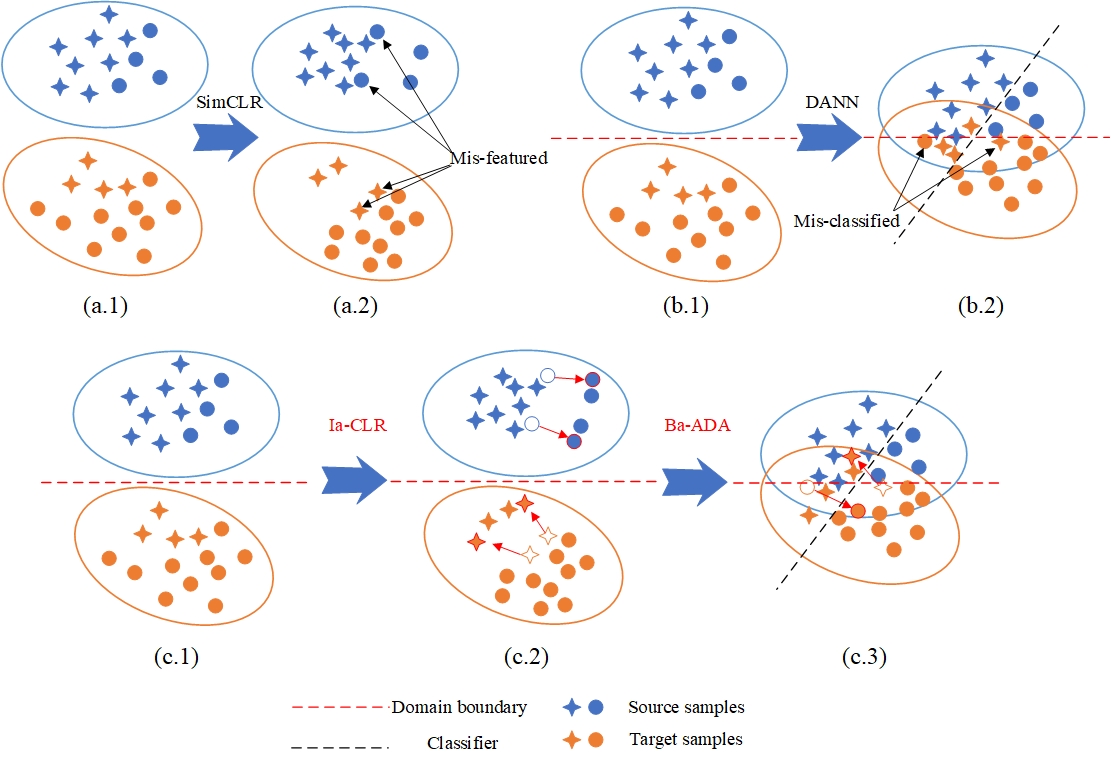
Zero-shot domain adaptation (ZSDA) is a domain adaptation problem in the situation that labeled samples for a target task (task of interest) are only available from the source domain at training time, but for a task different from the task of interest (irrelevant task), labeled samples are available from both source and target domains. In this situation, classical domain adaptation techniques can only learn domain-invariant features in the irrelevant task. However, due to the difference in sample distribution between the two tasks, domain-invariant features learned in the irrelevant task are biased and not necessarily domain-invariant in the task of interest. To solve this problem, this paper proposes a new ZSDA method to learn domain-invariant features with low task bias. To this end, we propose (1) data augmentation with dual-level mixups in both task and domain to fill the absence of target task-of-interest data, (2) an extension of domain adversarial learning to learn domain-invariant features with less task bias, and (3) a new dual-level contrastive learning method that enhances domain-invariance and less task biasedness of features. Experimental results show that our proposal achieves good performance on several benchmarks.
Read more6/28/2024
👀
0
Source-Free Domain Adaptation Guided by Vision and Vision-Language Pre-Training
Wenyu Zhang, Li Shen, Chuan-Sheng Foo
Source-free domain adaptation (SFDA) aims to adapt a source model trained on a fully-labeled source domain to a related but unlabeled target domain. While the source model is a key avenue for acquiring target pseudolabels, the generated pseudolabels may exhibit source bias. In the conventional SFDA pipeline, a large data (e.g. ImageNet) pre-trained feature extractor is used to initialize the source model at the start of source training, and subsequently discarded. Despite having diverse features important for generalization, the pre-trained feature extractor can overfit to the source data distribution during source training and forget relevant target domain knowledge. Rather than discarding this valuable knowledge, we introduce an integrated framework to incorporate pre-trained networks into the target adaptation process. The proposed framework is flexible and allows us to plug modern pre-trained networks into the adaptation process to leverage their stronger representation learning capabilities. For adaptation, we propose the Co-learn algorithm to improve target pseudolabel quality collaboratively through the source model and a pre-trained feature extractor. Building on the recent success of the vision-language model CLIP in zero-shot image recognition, we present an extension Co-learn++ to further incorporate CLIP's zero-shot classification decisions. We evaluate on 4 benchmark datasets and include more challenging scenarios such as open-set, partial-set and open-partial SFDA. Experimental results demonstrate that our proposed strategy improves adaptation performance and can be successfully integrated with existing SFDA methods.
Read more8/22/2024

0
ZoDi: Zero-Shot Domain Adaptation with Diffusion-Based Image Transfer
Hiroki Azuma, Yusuke Matsui, Atsuto Maki
Deep learning models achieve high accuracy in segmentation tasks among others, yet domain shift often degrades the models' performance, which can be critical in real-world scenarios where no target images are available. This paper proposes a zero-shot domain adaptation method based on diffusion models, called ZoDi, which is two-fold by the design: zero-shot image transfer and model adaptation. First, we utilize an off-the-shelf diffusion model to synthesize target-like images by transferring the domain of source images to the target domain. In this we specifically try to maintain the layout and content by utilising layout-to-image diffusion models with stochastic inversion. Secondly, we train the model using both source images and synthesized images with the original segmentation maps while maximizing the feature similarity of images from the two domains to learn domain-robust representations. Through experiments we show benefits of ZoDi in the task of image segmentation over state-of-the-art methods. It is also more applicable than existing CLIP-based methods because it assumes no specific backbone or models, and it enables to estimate the model's performance without target images by inspecting generated images. Our implementation will be publicly available.
Read more9/26/2024
0
Self-degraded contrastive domain adaptation for industrial fault diagnosis with bi-imbalanced data
Gecheng Chen, Zeyu Yang, Chengwen Luo, Jianqiang Li
Modern industrial fault diagnosis tasks often face the combined challenge of distribution discrepancy and bi-imbalance. Existing domain adaptation approaches pay little attention to the prevailing bi-imbalance, leading to poor domain adaptation performance or even negative transfer. In this work, we propose a self-degraded contrastive domain adaptation (Sd-CDA) diagnosis framework to handle the domain discrepancy under the bi-imbalanced data. It first pre-trains the feature extractor via imbalance-aware contrastive learning based on model pruning to learn the feature representation efficiently in a self-supervised manner. Then it forces the samples away from the domain boundary based on supervised contrastive domain adversarial learning (SupCon-DA) and ensures the features generated by the feature extractor are discriminative enough. Furthermore, we propose the pruned contrastive domain adversarial learning (PSupCon-DA) to pay automatically re-weighted attention to the minorities to enhance the performance towards bi-imbalanced data. We show the superiority of the proposed method via two experiments.
Read more6/3/2024