Contrastive Augmentation: An Unsupervised Learning Approach for Keyword Spotting in Speech Technology

0

Sign in to get full access
Overview
- The paper proposes a novel unsupervised learning approach called Contrastive Augmentation for keyword spotting in speech technology.
- The method uses contrastive learning to automatically extract meaningful representations from unlabeled speech data.
- This can improve the performance of keyword spotting models without the need for expensive labeled training data.
Plain English Explanation
The paper introduces a new technique called Contrastive Augmentation for improving keyword spotting in speech recognition systems. Keyword spotting is the ability to detect specific words or phrases within a spoken audio stream.
The key idea is to use an unsupervised learning approach based on contrastive learning. This allows the model to automatically discover meaningful patterns and representations in unlabeled speech data, without needing expensive manually labeled training examples.
The contrastive approach works by training the model to distinguish between positive examples (e.g. the target keyword) and negative examples (other speech segments). By learning these discriminative features in an unsupervised way, the model can then be fine-tuned for the specific keyword spotting task using only a small amount of labeled data.
The authors show that this contrastive augmentation technique outperforms previous supervised and semi-supervised methods for keyword spotting, achieving higher accuracy while using less labeled training data.
Technical Explanation
The paper presents a novel Contrastive Augmentation framework for unsupervised learning of speech representations that can be effectively fine-tuned for keyword spotting tasks.
The key elements of the approach are:
-
Contrastive Learning: The model is trained to learn discriminative representations by contrasting positive (keyword) and negative (non-keyword) speech segments. This is done in an unsupervised manner using only unlabeled speech data.
-
Data Augmentation: The training data is augmented using various speech transformations to improve the robustness and generalization of the learned representations.
-
Fine-tuning: The pre-trained contrastive model is then fine-tuned on a small amount of labeled keyword spotting data to adapt it to the specific task.
The authors evaluate their method on several benchmark keyword spotting datasets and show consistent improvements over previous supervised and semi-supervised approaches. They also provide ablation studies to analyze the contribution of the key components of their framework.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the Contrastive Augmentation technique. The authors acknowledge some potential limitations, such as the reliance on a fixed set of data augmentation transformations, and suggest areas for future research to address these.
One potential concern is the computational cost and training time required for the contrastive pre-training stage, which may limit the practical applicability of the method, especially for resource-constrained deployment scenarios. The authors do not provide detailed benchmarks on training efficiency.
Additionally, the performance improvements, while significant, may still not be sufficient for certain real-world keyword spotting applications with stringent accuracy requirements. Further research is needed to push the boundaries of unsupervised representation learning for this task.
Conclusion
The Contrastive Augmentation approach proposed in this paper represents an important advance in the field of keyword spotting for speech recognition systems. By leveraging unsupervised contrastive learning, the method can effectively extract meaningful speech representations from unlabeled data and then fine-tune them for the target keyword spotting task using only a small amount of labeled examples.
The authors demonstrate the effectiveness of their technique across multiple benchmark datasets, outperforming previous supervised and semi-supervised methods. While some limitations and areas for improvement remain, this work opens up new possibilities for building accurate and efficient keyword spotting models with reduced reliance on expensive annotated training data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Contrastive Augmentation: An Unsupervised Learning Approach for Keyword Spotting in Speech Technology
Weinan Dai, Yifeng Jiang, Yuanjing Liu, Jinkun Chen, Xin Sun, Jinglei Tao
This paper addresses the persistent challenge in Keyword Spotting (KWS), a fundamental component in speech technology, regarding the acquisition of substantial labeled data for training. Given the difficulty in obtaining large quantities of positive samples and the laborious process of collecting new target samples when the keyword changes, we introduce a novel approach combining unsupervised contrastive learning and a unique augmentation-based technique. Our method allows the neural network to train on unlabeled data sets, potentially improving performance in downstream tasks with limited labeled data sets. We also propose that similar high-level feature representations should be employed for speech utterances with the same keyword despite variations in speed or volume. To achieve this, we present a speech augmentation-based unsupervised learning method that utilizes the similarity between the bottleneck layer feature and the audio reconstructing information for auxiliary training. Furthermore, we propose a compressed convolutional architecture to address potential redundancy and non-informative information in KWS tasks, enabling the model to simultaneously learn local features and focus on long-term information. This method achieves strong performance on the Google Speech Commands V2 Dataset. Inspired by recent advancements in sign spotting and spoken term detection, our method underlines the potential of our contrastive learning approach in KWS and the advantages of Query-by-Example Spoken Term Detection strategies. The presented CAB-KWS provide new perspectives in the field of KWS, demonstrating effective ways to reduce data collection efforts and increase the system's robustness.
Read more9/4/2024
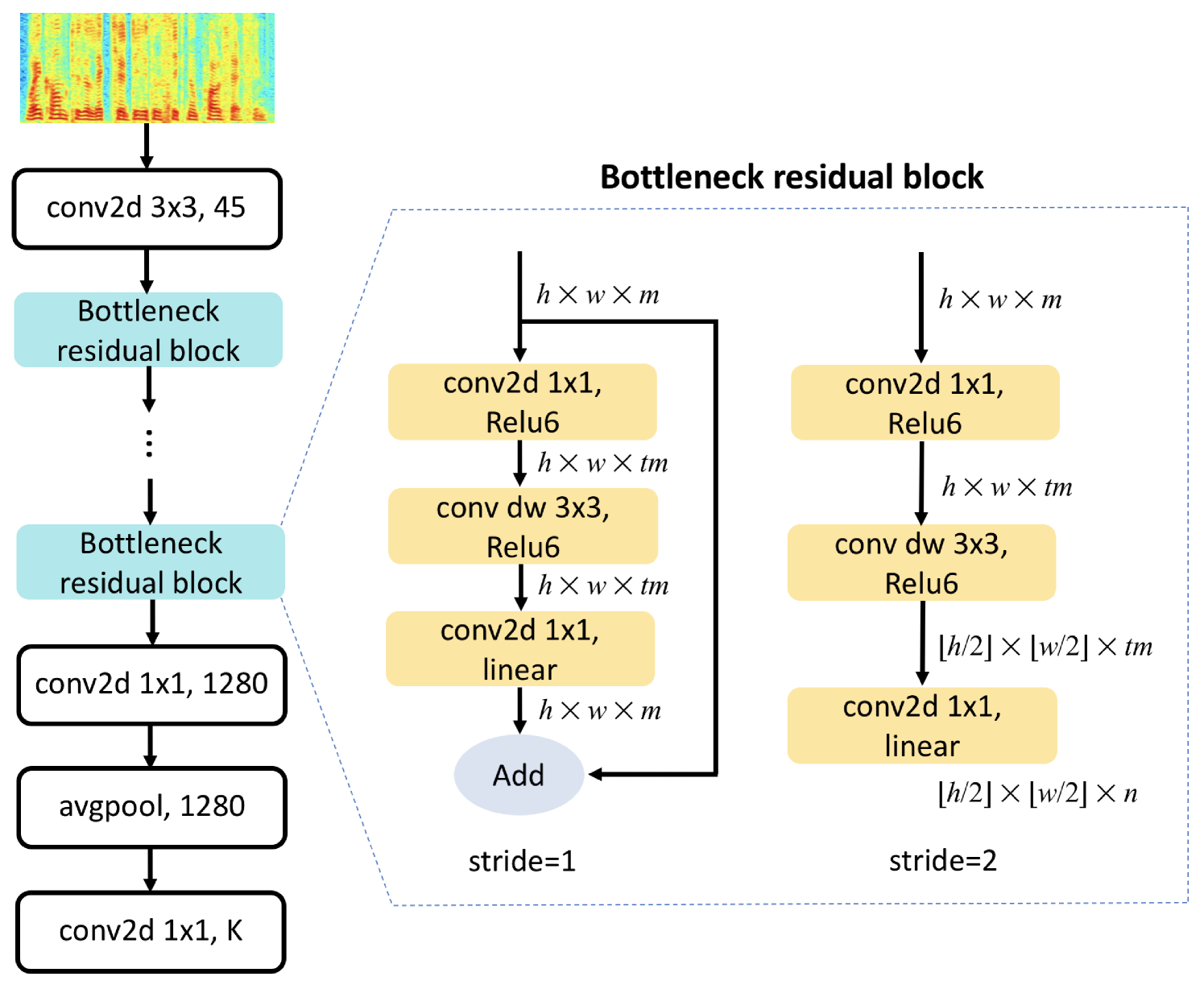
0
Disentangled Training with Adversarial Examples For Robust Small-footprint Keyword Spotting
Zhenyu Wang, Li Wan, Biqiao Zhang, Yiteng Huang, Shang-Wen Li, Ming Sun, Xin Lei, Zhaojun Yang
A keyword spotting (KWS) engine that is continuously running on device is exposed to various speech signals that are usually unseen before. It is a challenging problem to build a small-footprint and high-performing KWS model with robustness under different acoustic environments. In this paper, we explore how to effectively apply adversarial examples to improve KWS robustness. We propose datasource-aware disentangled learning with adversarial examples to reduce the mismatch between the original and adversarial data as well as the mismatch across original training datasources. The KWS model architecture is based on depth-wise separable convolution and a simple attention module. Experimental results demonstrate that the proposed learning strategy improves false reject rate by $40.31%$ at $1%$ false accept rate on the internal dataset, compared to the strongest baseline without using adversarial examples. Our best-performing system achieves $98.06%$ accuracy on the Google Speech Commands V1 dataset.
Read more8/27/2024

0
Adversarial training of Keyword Spotting to Minimize TTS Data Overfitting
Hyun Jin Park, Dhruuv Agarwal, Neng Chen, Rentao Sun, Kurt Partridge, Justin Chen, Harry Zhang, Pai Zhu, Jacob Bartel, Kyle Kastner, Gary Wang, Andrew Rosenberg, Quan Wang
The keyword spotting (KWS) problem requires large amounts of real speech training data to achieve high accuracy across diverse populations. Utilizing large amounts of text-to-speech (TTS) synthesized data can reduce the cost and time associated with KWS development. However, TTS data may contain artifacts not present in real speech, which the KWS model can exploit (overfit), leading to degraded accuracy on real speech. To address this issue, we propose applying an adversarial training method to prevent the KWS model from learning TTS-specific features when trained on large amounts of TTS data. Experimental results demonstrate that KWS model accuracy on real speech data can be improved by up to 12% when adversarial loss is used in addition to the original KWS loss. Surprisingly, we also observed that the adversarial setup improves accuracy by up to 8%, even when trained solely on TTS and real negative speech data, without any real positive examples.
Read more8/21/2024
🗣️
0
Few-Shot Keyword Spotting from Mixed Speech
Junming Yuan, Ying Shi, LanTian Li, Dong Wang, Askar Hamdulla
Few-shot keyword spotting (KWS) aims to detect unknown keywords with limited training samples. A commonly used approach is the pre-training and fine-tuning framework. While effective in clean conditions, this approach struggles with mixed keyword spotting -- simultaneously detecting multiple keywords blended in an utterance, which is crucial in real-world applications. Previous research has proposed a Mix-Training (MT) approach to solve the problem, however, it has never been tested in the few-shot scenario. In this paper, we investigate the possibility of using MT and other relevant methods to solve the two practical challenges together: few-shot and mixed speech. Experiments conducted on the LibriSpeech and Google Speech Command corpora demonstrate that MT is highly effective on this task when employed in either the pre-training phase or the fine-tuning phase. Moreover, combining SSL-based large-scale pre-training (HuBert) and MT fine-tuning yields very strong results in all the test conditions.
Read more7/9/2024