Contrastive Policy Gradient: Aligning LLMs on sequence-level scores in a supervised-friendly fashion
2406.19185
0
0

Abstract
Reinforcement Learning (RL) has been used to finetune Large Language Models (LLMs) using a reward model trained from preference data, to better align with human judgment. The recently introduced direct alignment methods, which are often simpler, more stable, and computationally lighter, can more directly achieve this. However, these approaches cannot optimize arbitrary rewards, and the preference-based ones are not the only rewards of interest for LLMs (eg., unit tests for code generation or textual entailment for summarization, among others). RL-finetuning is usually done with a variation of policy gradient, which calls for on-policy or near-on-policy samples, requiring costly generations. We introduce Contrastive Policy Gradient, or CoPG, a simple and mathematically principled new RL algorithm that can estimate the optimal policy even from off-policy data. It can be seen as an off-policy policy gradient approach that does not rely on important sampling techniques and highlights the importance of using (the right) state baseline. We show this approach to generalize the direct alignment method IPO (identity preference optimization) and classic policy gradient. We experiment with the proposed CoPG on a toy bandit problem to illustrate its properties, as well as for finetuning LLMs on a summarization task, using a learned reward function considered as ground truth for the purpose of the experiments.
Create account to get full access
Overview
- This paper introduces a new method called Contrastive Policy Gradient (CPG) for aligning large language models (LLMs) on sequence-level scores in a supervised-friendly fashion.
- CPG aims to align LLMs with a target scoring function, such as human preferences or task performance, while maintaining the ability to fine-tune the models in a supervised manner.
- The authors demonstrate that CPG outperforms existing approaches like Preference Fine-tuning and Reinforcement Learning on a range of language modeling tasks.
Plain English Explanation
The paper presents a new way to align large language models (LLMs) with a target scoring function, such as human preferences or task performance. The key idea is to use a technique called Contrastive Policy Gradient (CPG), which allows the LLM to be fine-tuned in a supervised manner while still being aligned with the target scoring function.
Imagine you have a language model that can generate text, but you want it to generate text that aligns with a specific goal or preference, like writing concise and informative summaries. The traditional approach would be to use reinforcement learning, where you reward the model when it generates text that matches your preferred style. However, this can be challenging and can make it harder to further fine-tune the model for other tasks.
CPG, on the other hand, aims to find a middle ground. It allows the model to be fine-tuned in a more straightforward, supervised way, while still ensuring that the generated text aligns with the target scoring function. The authors show that this approach outperforms existing methods on a range of language modeling tasks, making it a promising technique for aligning LLMs with specific goals or preferences.
Technical Explanation
The paper introduces a new method called Contrastive Policy Gradient (CPG) for aligning large language models (LLMs) on sequence-level scores in a supervised-friendly fashion. The key idea behind CPG is to use a contrastive loss function that encourages the LLM to generate text that aligns with a target scoring function, such as human preferences or task performance, while still maintaining the ability to fine-tune the model in a supervised manner.
Specifically, the authors propose a training procedure where the LLM is given a pair of text sequences, one of which is the target sequence and the other is a negative sample. The model is then trained to assign a higher score to the target sequence compared to the negative sample, using a contrastive loss function. This aligns the model's internal representations with the target scoring function, while still allowing for supervised fine-tuning on downstream tasks.
The authors demonstrate the effectiveness of CPG on a range of language modeling tasks, including text summarization, language generation, and open-ended question answering. They show that CPG outperforms existing approaches like Preference Fine-tuning and Reinforcement Learning, as well as simpler methods like Averaging Log-Likelihoods and Direct Alignment.
Critical Analysis
The paper presents a promising approach for aligning large language models with specific scoring functions, while maintaining the ability to fine-tune the models in a supervised manner. However, there are a few potential limitations and areas for further research:
-
Scalability: The authors demonstrate the effectiveness of CPG on a range of language modeling tasks, but it's unclear how well the method would scale to larger and more complex models, or to tasks with more diverse and subjective scoring functions.
-
Interpretability: The paper does not provide much insight into the internal workings of the CPG method or the learned representations of the LLM. It would be valuable to understand how the model is able to align its outputs with the target scoring function.
-
Real-world Applicability: The paper focuses on relatively narrow language modeling tasks, and it's unclear how well the CPG method would translate to more open-ended and complex real-world applications, such as interactive dialogue or creative writing.
-
Ethical Considerations: Aligning language models with specific scoring functions raises potential ethical concerns, as it could lead to the generation of biased or manipulative content. The paper does not address these issues, and further research is needed to ensure the responsible development and deployment of such techniques.
Overall, the Contrastive Policy Gradient method presented in this paper is a promising step towards aligning large language models with specific goals and preferences, while maintaining the flexibility of supervised fine-tuning. However, further research is needed to address the potential limitations and ethical considerations of this approach.
Conclusion
The Contrastive Policy Gradient (CPG) method introduced in this paper offers a new way to align large language models with target scoring functions, such as human preferences or task performance, while still allowing for supervised fine-tuning. By using a contrastive loss function, CPG is able to outperform existing approaches on a range of language modeling tasks.
This work represents an important advance in the field of language model alignment, as it provides a more flexible and supervised-friendly alternative to methods like reinforcement learning. The ability to align LLMs with specific goals or preferences while retaining the benefits of supervised fine-tuning could have significant implications for the development of more capable and aligned natural language systems.
However, further research is needed to address the potential limitations and ethical considerations of the CPG method, such as scalability, interpretability, and real-world applicability. As the field of language model alignment continues to evolve, it will be crucial to ensure that these techniques are developed and deployed responsibly, with a focus on maximizing the benefits and minimizing the risks to society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Aligning Large Language Models via Fine-grained Supervision
Dehong Xu, Liang Qiu, Minseok Kim, Faisal Ladhak, Jaeyoung Do
0
0
Pre-trained large-scale language models (LLMs) excel at producing coherent articles, yet their outputs may be untruthful, toxic, or fail to align with user expectations. Current approaches focus on using reinforcement learning with human feedback (RLHF) to improve model alignment, which works by transforming coarse human preferences of LLM outputs into a feedback signal that guides the model learning process. However, because this approach operates on sequence-level feedback, it lacks the precision to identify the exact parts of the output affecting user preferences. To address this gap, we propose a method to enhance LLM alignment through fine-grained token-level supervision. Specifically, we ask annotators to minimally edit less preferred responses within the standard reward modeling dataset to make them more favorable, ensuring changes are made only where necessary while retaining most of the original content. The refined dataset is used to train a token-level reward model, which is then used for training our fine-grained Proximal Policy Optimization (PPO) model. Our experiment results demonstrate that this approach can achieve up to an absolute improvement of $5.1%$ in LLM performance, in terms of win rate against the reference model, compared with the traditional PPO model.
6/6/2024
💬
Privately Aligning Language Models with Reinforcement Learning
Fan Wu, Huseyin A. Inan, Arturs Backurs, Varun Chandrasekaran, Janardhan Kulkarni, Robert Sim
0
0
Positioned between pre-training and user deployment, aligning large language models (LLMs) through reinforcement learning (RL) has emerged as a prevailing strategy for training instruction following-models such as ChatGPT. In this work, we initiate the study of privacy-preserving alignment of LLMs through Differential Privacy (DP) in conjunction with RL. Following the influential work of Ziegler et al. (2020), we study two dominant paradigms: (i) alignment via RL without human in the loop (e.g., positive review generation) and (ii) alignment via RL from human feedback (RLHF) (e.g., summarization in a human-preferred way). We give a new DP framework to achieve alignment via RL, and prove its correctness. Our experimental results validate the effectiveness of our approach, offering competitive utility while ensuring strong privacy protections.
5/6/2024
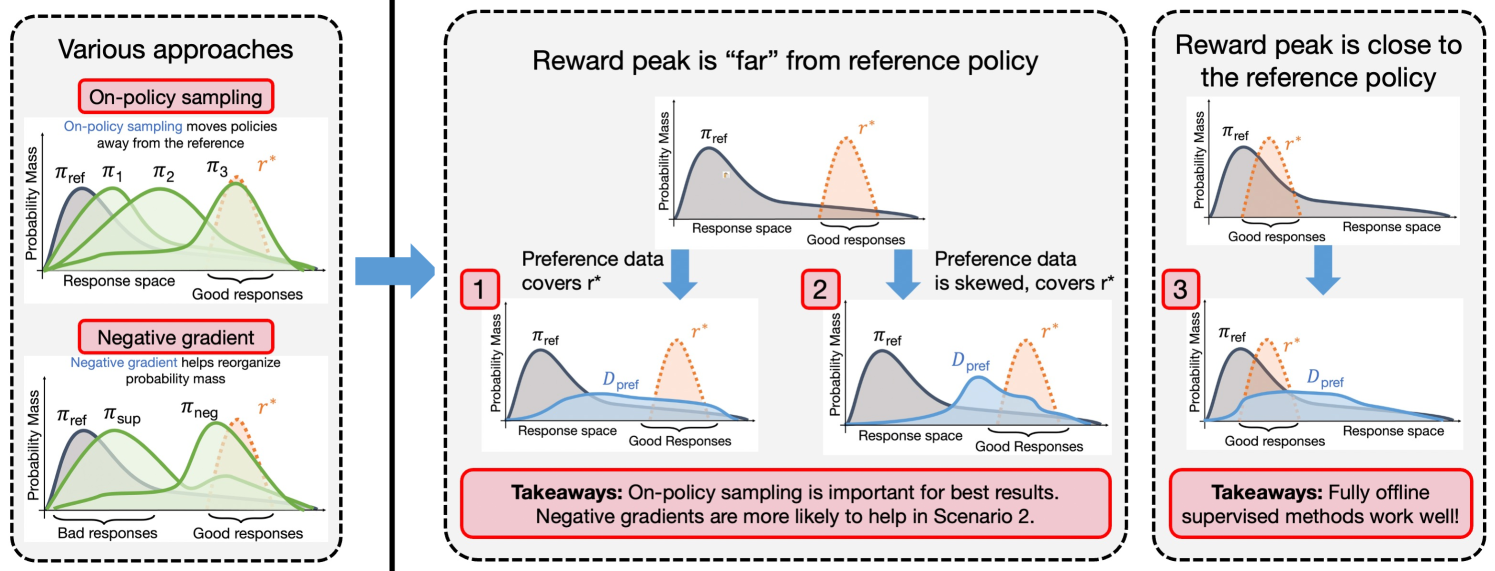
Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data
Fahim Tajwar, Anikait Singh, Archit Sharma, Rafael Rafailov, Jeff Schneider, Tengyang Xie, Stefano Ermon, Chelsea Finn, Aviral Kumar
0
0
Learning from preference labels plays a crucial role in fine-tuning large language models. There are several distinct approaches for preference fine-tuning, including supervised learning, on-policy reinforcement learning (RL), and contrastive learning. Different methods come with different implementation tradeoffs and performance differences, and existing empirical findings present different conclusions, for instance, some results show that online RL is quite important to attain good fine-tuning results, while others find (offline) contrastive or even purely supervised methods sufficient. This raises a natural question: what kind of approaches are important for fine-tuning with preference data and why? In this paper, we answer this question by performing a rigorous analysis of a number of fine-tuning techniques on didactic and full-scale LLM problems. Our main finding is that, in general, approaches that use on-policy sampling or attempt to push down the likelihood on certain responses (i.e., employ a negative gradient) outperform offline and maximum likelihood objectives. We conceptualize our insights and unify methods that use on-policy sampling or negative gradient under a notion of mode-seeking objectives for categorical distributions. Mode-seeking objectives are able to alter probability mass on specific bins of a categorical distribution at a fast rate compared to maximum likelihood, allowing them to relocate masses across bins more effectively. Our analysis prescribes actionable insights for preference fine-tuning of LLMs and informs how data should be collected for maximal improvement.
6/4/2024

Averaging log-likelihoods in direct alignment
Nathan Grinsztajn, Yannis Flet-Berliac, Mohammad Gheshlaghi Azar, Florian Strub, Bill Wu, Eugene Choi, Chris Cremer, Arash Ahmadian, Yash Chandak, Olivier Pietquin, Matthieu Geist
0
0
To better align Large Language Models (LLMs) with human judgment, Reinforcement Learning from Human Feedback (RLHF) learns a reward model and then optimizes it using regularized RL. Recently, direct alignment methods were introduced to learn such a fine-tuned model directly from a preference dataset without computing a proxy reward function. These methods are built upon contrastive losses involving the log-likelihood of (dis)preferred completions according to the trained model. However, completions have various lengths, and the log-likelihood is not length-invariant. On the other side, the cross-entropy loss used in supervised training is length-invariant, as batches are typically averaged token-wise. To reconcile these approaches, we introduce a principled approach for making direct alignment length-invariant. Formally, we introduce a new averaging operator, to be composed with the optimality operator giving the best policy for the underlying RL problem. It translates into averaging the log-likelihood within the loss. We empirically study the effect of such averaging, observing a trade-off between the length of generations and their scores.
6/28/2024