Conv-INR: Convolutional Implicit Neural Representation for Multimodal Visual Signals

0

Sign in to get full access
Overview
- This paper introduces Conv-INR, a novel convolutional implicit neural representation (INR) for multimodal visual signals.
- Conv-INR combines the benefits of convolutional neural networks (CNNs) and INRs to efficiently encode and process complex visual data.
- The model demonstrates strong performance on various tasks, including image reconstruction, super-resolution, and cross-modal translation.
Plain English Explanation
Implicit neural representations (INRs) are a powerful way to encode complex visual data, like images and videos, using neural networks. They can efficiently represent high-resolution and multimodal information, but they can be computationally expensive to process.
In this paper, the researchers introduce Conv-INR, a new type of INR that combines the strengths of convolutional neural networks (CNNs) and traditional INRs. CNNs are great at efficiently processing spatial information, like the pixels in an image, but they can struggle with high-resolution or multimodal data.
Conv-INR takes the best of both worlds. It uses convolutional layers to efficiently encode the spatial structure of visual data, while still maintaining the flexibility and expressive power of INRs. This allows Conv-INR to handle complex, high-resolution, and multimodal visual signals, like image-text pairs or 3D scenes, with impressive performance.
The researchers demonstrate the capabilities of Conv-INR on a variety of tasks, including reconstructing images, super-resolving low-res images, and translating between different visual modalities, like generating images from text. The model outperforms previous state-of-the-art approaches, demonstrating the power of combining convolutional and implicit neural representations.
Technical Explanation
The key innovation of Conv-INR is the integration of convolutional layers into the implicit neural representation framework. Traditionally, INRs have used fully connected neural networks to encode visual signals, which can be computationally expensive and struggle with spatial structure.
Conv-INR addresses this by incorporating convolutional layers into the INR architecture. These convolutional layers efficiently extract and encode the spatial features of the input data, while the rest of the INR network maintains the flexible, multimodal representation capabilities of traditional INRs.
The researchers evaluate Conv-INR on a range of tasks, including image reconstruction, super-resolution, and cross-modal translation between images and text. Compared to previous state-of-the-art approaches, Conv-INR demonstrates superior performance, particularly on high-resolution and multimodal visual signals.
For example, in image super-resolution experiments, Conv-INR was able to produce higher-quality, more detailed upscaled images compared to traditional CNN-based super-resolution models. And in cross-modal translation tasks, Conv-INR outperformed other INR-based methods at generating realistic images from text descriptions.
Critical Analysis
One potential limitation of Conv-INR is that the integration of convolutional layers may limit the model's ability to capture long-range dependencies in the input data. Traditional INRs, with their fully connected architecture, can more easily model global relationships, while the local receptive fields of convolutions may struggle with certain types of visual patterns.
Additionally, as with many neural network-based approaches, the training of Conv-INR may be computationally intensive and require large datasets to achieve good performance. The researchers address this to some extent by leveraging pre-trained CNN backbones, but the overall training process could still be challenging, especially for smaller-scale applications.
Further research could explore ways to enhance the global reasoning capabilities of Conv-INR, perhaps by incorporating attention mechanisms or other techniques to better capture long-range dependencies. Investigations into more efficient training procedures or ways to reduce the model's computational requirements could also improve its practicality for real-world deployments.
Conclusion
The Conv-INR model presented in this paper represents a significant advancement in the field of visual representation learning. By combining the strengths of convolutional neural networks and implicit neural representations, the researchers have developed a powerful framework that can efficiently encode and process complex, high-resolution, and multimodal visual signals.
The impressive performance of Conv-INR on tasks like image reconstruction, super-resolution, and cross-modal translation suggests that this approach could have widespread applications in computer vision, multimedia processing, and beyond. As the research community continues to explore the potential of implicit neural representations, innovations like Conv-INR will likely play a crucial role in unlocking new capabilities and pushing the boundaries of what's possible in visual computing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Conv-INR: Convolutional Implicit Neural Representation for Multimodal Visual Signals
Zhicheng Cai
Implicit neural representation (INR) has recently emerged as a promising paradigm for signal representations. Typically, INR is parameterized by a multiplayer perceptron (MLP) which takes the coordinates as the inputs and generates corresponding attributes of a signal. However, MLP-based INRs face two critical issues: i) individually considering each coordinate while ignoring the connections; ii) suffering from the spectral bias thus failing to learn high-frequency components. While target visual signals usually exhibit strong local structures and neighborhood dependencies, and high-frequency components are significant in these signals, the issues harm the representational capacity of INRs. This paper proposes Conv-INR, the first INR model fully based on convolution. Due to the inherent attributes of convolution, Conv-INR can simultaneously consider adjacent coordinates and learn high-frequency components effectively. Compared to existing MLP-based INRs, Conv-INR has better representational capacity and trainability without requiring primary function expansion. We conduct extensive experiments on four tasks, including image fitting, CT/MRI reconstruction, and novel view synthesis, Conv-INR all significantly surpasses existing MLP-based INRs, validating the effectiveness. Finally, we raise three reparameterization methods that can further enhance the performance of the vanilla Conv-INR without introducing any extra inference cost.
Read more6/7/2024

0
Streaming Neural Images
Marcos V. Conde, Andy Bigos, Radu Timofte
Implicit Neural Representations (INRs) are a novel paradigm for signal representation that have attracted considerable interest for image compression. INRs offer unprecedented advantages in signal resolution and memory efficiency, enabling new possibilities for compression techniques. However, the existing limitations of INRs for image compression have not been sufficiently addressed in the literature. In this work, we explore the critical yet overlooked limiting factors of INRs, such as computational cost, unstable performance, and robustness. Through extensive experiments and empirical analysis, we provide a deeper and more nuanced understanding of implicit neural image compression methods such as Fourier Feature Networks and Siren. Our work also offers valuable insights for future research in this area.
Read more9/26/2024

0
Learning Transferable Features for Implicit Neural Representations
Kushal Vyas, Ahmed Imtiaz Humayun, Aniket Dashpute, Richard G. Baraniuk, Ashok Veeraraghavan, Guha Balakrishnan
Implicit neural representations (INRs) have demonstrated success in a variety of applications, including inverse problems and neural rendering. An INR is typically trained to capture one signal of interest, resulting in learned neural features that are highly attuned to that signal. Assumed to be less generalizable, we explore the aspect of transferability of such learned neural features for fitting similar signals. We introduce a new INR training framework, STRAINER that learns transferrable features for fitting INRs to new signals from a given distribution, faster and with better reconstruction quality. Owing to the sequential layer-wise affine operations in an INR, we propose to learn transferable representations by sharing initial encoder layers across multiple INRs with independent decoder layers. At test time, the learned encoder representations are transferred as initialization for an otherwise randomly initialized INR. We find STRAINER to yield extremely powerful initialization for fitting images from the same domain and allow for $approx +10dB$ gain in signal quality early on compared to an untrained INR itself. STRAINER also provides a simple way to encode data-driven priors in INRs. We evaluate STRAINER on multiple in-domain and out-of-domain signal fitting tasks and inverse problems and further provide detailed analysis and discussion on the transferability of STRAINER's features. Our demo can be accessed at https://colab.research.google.com/drive/1fBZAwqE8C_lrRPAe-hQZJTWrMJuAKtG2?usp=sharing .
Read more9/17/2024
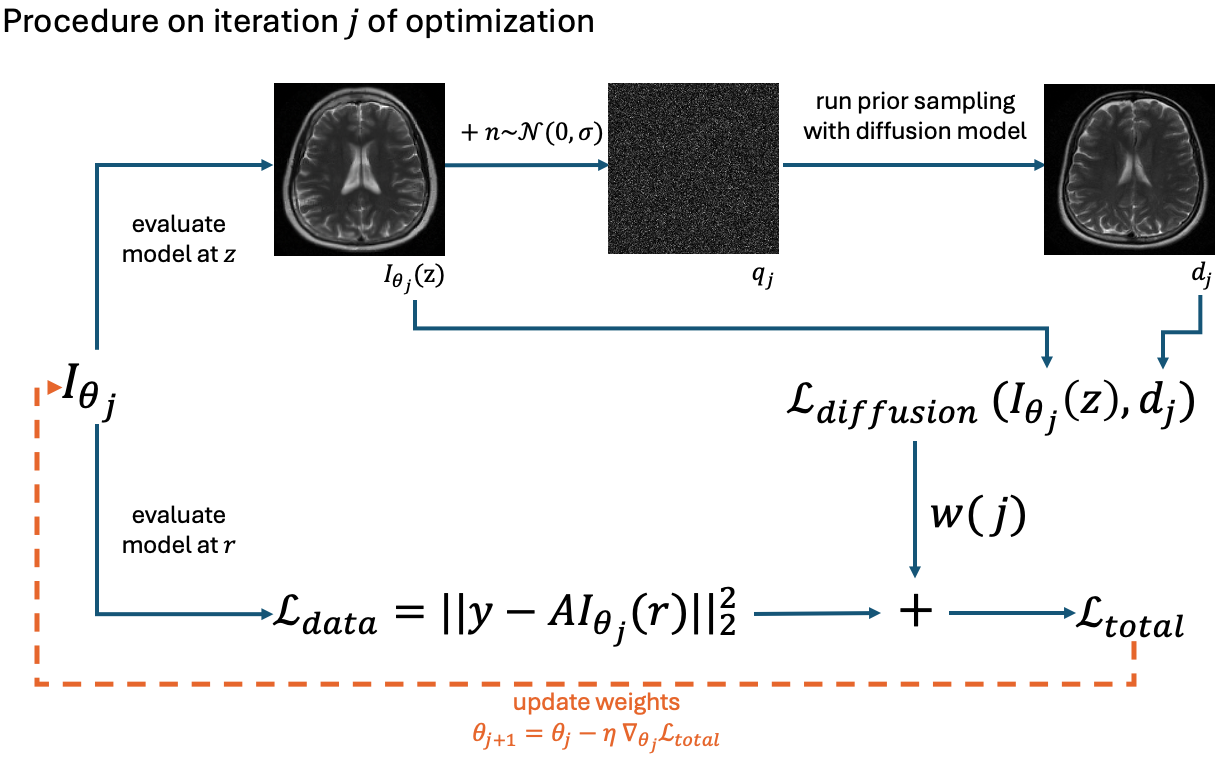
0
INFusion: Diffusion Regularized Implicit Neural Representations for 2D and 3D accelerated MRI reconstruction
Yamin Arefeen, Brett Levac, Zach Stoebner, Jonathan Tamir
Implicit Neural Representations (INRs) are a learning-based approach to accelerate Magnetic Resonance Imaging (MRI) acquisitions, particularly in scan-specific settings when only data from the under-sampled scan itself are available. Previous work demonstrates that INRs improve rapid MRI through inherent regularization imposed by neural network architectures. Typically parameterized by fully-connected neural networks, INRs support continuous image representations by taking a physical coordinate location as input and outputting the intensity at that coordinate. Previous work has applied unlearned regularization priors during INR training and have been limited to 2D or low-resolution 3D acquisitions. Meanwhile, diffusion based generative models have received recent attention as they learn powerful image priors decoupled from the measurement model. This work proposes INFusion, a technique that regularizes the optimization of INRs from under-sampled MR measurements with pre-trained diffusion models for improved image reconstruction. In addition, we propose a hybrid 3D approach with our diffusion regularization that enables INR application on large-scale 3D MR datasets. 2D experiments demonstrate improved INR training with our proposed diffusion regularization, and 3D experiments demonstrate feasibility of INR training with diffusion regularization on 3D matrix sizes of 256 by 256 by 80.
Read more6/21/2024