On the Convergence of Zeroth-Order Federated Tuning for Large Language Models
2402.05926
0
0
💬
Abstract
The confluence of Federated Learning (FL) and Large Language Models (LLMs) is ushering in a new era in privacy-preserving natural language processing. However, the intensive memory requirements for fine-tuning LLMs pose significant challenges, especially when deploying on clients with limited computational resources. To circumvent this, we explore the novel integration of Memory-efficient Zeroth-Order Optimization within a federated setting, a synergy we term as FedMeZO. Our study is the first to examine the theoretical underpinnings of FedMeZO in the context of LLMs, tackling key questions regarding the influence of large parameter spaces on optimization behavior, the establishment of convergence properties, and the identification of critical parameters for convergence to inform personalized federated strategies. Our extensive empirical evidence supports the theory, showing that FedMeZO not only converges faster than traditional first-order methods such as FedAvg but also significantly reduces GPU memory usage during training to levels comparable to those during inference. Moreover, the proposed personalized FL strategy that is built upon the theoretical insights to customize the client-wise learning rate can effectively accelerate loss reduction. We hope our work can help to bridge theoretical and practical aspects of federated fine-tuning for LLMs, thereby stimulating further advancements and research in this area.
Create account to get full access
Overview
- This paper explores the integration of Federated Learning (FL) and Large Language Models (LLMs) to enable privacy-preserving natural language processing.
- The main challenge addressed is the intensive memory requirements for fine-tuning LLMs, which can be problematic when deploying on clients with limited computational resources.
- The researchers propose a novel approach called FedMeZO, which combines Federated Learning with Memory-efficient Zeroth-Order Optimization.
- The study examines the theoretical underpinnings of FedMeZO in the context of LLMs, investigating the influence of large parameter spaces on optimization behavior, convergence properties, and critical parameters for personalized federated strategies.
- The empirical evidence supports the theory, showing that FedMeZO converges faster than traditional first-order methods like FedAvg and significantly reduces GPU memory usage during training.
- The paper also proposes a personalized FL strategy that can effectively accelerate loss reduction, based on the theoretical insights.
Plain English Explanation
Imagine you have a group of friends who each have a special skill or knowledge they want to share, but they don't want to reveal their personal information. That's kind of like what Federated Learning (FL) does - it allows these friends to learn from each other without sharing their private details.
Now, let's say one of your friends is really great at understanding and generating human language, but it takes a lot of memory and processing power to do that. That's kind of like the challenge with using large language models (LLMs) on devices with limited resources.
The researchers in this paper came up with a new way to help your friend share their language skills without using up too much memory. They call it FedMeZO, and it combines FL with a special optimization technique that's more memory-efficient.
The researchers looked at how this FedMeZO approach works for LLMs, and they found that it can actually learn faster and use less GPU memory than other methods, like FedAvg. They also came up with a way to personalize the learning for each of your friends, so they can all get the most out of the language model.
Overall, this research is helping to make it easier to use powerful language models in a way that protects people's privacy and works well on a wide range of devices, even those with limited capabilities. It's an important step towards federated fine-tuning of LLMs at the edge and personalized wireless federated learning for large language models.
Technical Explanation
The paper Federated Full-Parameter Tuning of Billion-Sized Language Models explores the integration of Federated Learning (FL) and Large Language Models (LLMs) to enable privacy-preserving natural language processing. The key challenge addressed is the intensive memory requirements for fine-tuning LLMs, which can be problematic when deploying on clients with limited computational resources.
To address this, the researchers propose a novel approach called FedMeZO, which combines Federated Learning with Memory-efficient Zeroth-Order Optimization. The study examines the theoretical underpinnings of FedMeZO in the context of LLMs, investigating the influence of large parameter spaces on optimization behavior, the establishment of convergence properties, and the identification of critical parameters for personalized federated strategies.
The empirical evidence presented supports the theory, showing that FedMeZO not only converges faster than traditional first-order methods like FedAvg but also significantly reduces GPU memory usage during training to levels comparable to those during inference. Moreover, the proposed personalized FL strategy that is built upon the theoretical insights to customize the client-wise learning rate can effectively accelerate loss reduction.
Critical Analysis
The paper provides a thorough theoretical and empirical investigation of the FedMeZO approach, which appears to be a promising solution for federated fine-tuning of LLMs at the edge and personalized wireless federated learning for large language models.
However, the paper does not explore the potential impact of zeroth-order fine-tuning of LLMs under extreme sparsity, which could be an important consideration for real-world deployment scenarios. Additionally, the researchers acknowledge that the theoretical analysis is limited to the specific settings considered, and further work is needed to generalize the insights.
It would also be valuable to see a more in-depth discussion of the limitations of the proposed approach, such as the potential impact on model performance or the scalability of the personalized federated strategy. Addressing these aspects could help identify areas for future research and further refine the FedMeZO framework.
Conclusion
This paper presents a novel integration of Federated Learning and Large Language Models, called FedMeZO, that aims to enable privacy-preserving natural language processing while addressing the memory constraints of fine-tuning LLMs on resource-limited devices.
The study's theoretical and empirical findings suggest that FedMeZO can converge faster and significantly reduce GPU memory usage compared to traditional first-order methods. Additionally, the proposed personalized federated strategy shows promise in accelerating loss reduction.
This work represents an important step towards federated fine-tuning of LLMs at the edge and personalized wireless federated learning for large language models, which could have significant implications for privacy-preserving natural language processing applications in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Federated Full-Parameter Tuning of Billion-Sized Language Models with Communication Cost under 18 Kilobytes
Zhen Qin, Daoyuan Chen, Bingchen Qian, Bolin Ding, Yaliang Li, Shuiguang Deng
0
0
Pre-trained large language models (LLMs) need fine-tuning to improve their responsiveness to natural language instructions. Federated learning offers a way to fine-tune LLMs using the abundant data on end devices without compromising data privacy. Most existing federated fine-tuning methods for LLMs rely on parameter-efficient fine-tuning techniques, which may not reach the performance height possible with full-parameter tuning. However, federated full-parameter tuning of LLMs is a non-trivial problem due to the immense communication cost. This work introduces FedKSeed that employs zeroth-order optimization with a finite set of random seeds. It significantly reduces transmission requirements between the server and clients to just a few random seeds and scalar gradients, amounting to only a few thousand bytes, making federated full-parameter tuning of billion-sized LLMs possible on devices. Building on it, we develop a strategy enabling probability-differentiated seed sampling, prioritizing perturbations with greater impact on model accuracy. Experiments across six scenarios with various LLMs, datasets and data partitions demonstrate that our approach outperforms existing federated LLM fine-tuning methods in both communication efficiency and new task generalization.
5/28/2024
🛠️
Revisiting Zeroth-Order Optimization for Memory-Efficient LLM Fine-Tuning: A Benchmark
Yihua Zhang, Pingzhi Li, Junyuan Hong, Jiaxiang Li, Yimeng Zhang, Wenqing Zheng, Pin-Yu Chen, Jason D. Lee, Wotao Yin, Mingyi Hong, Zhangyang Wang, Sijia Liu, Tianlong Chen
0
0
In the evolving landscape of natural language processing (NLP), fine-tuning pre-trained Large Language Models (LLMs) with first-order (FO) optimizers like SGD and Adam has become standard. Yet, as LLMs grow {in size}, the substantial memory overhead from back-propagation (BP) for FO gradient computation presents a significant challenge. Addressing this issue is crucial, especially for applications like on-device training where memory efficiency is paramount. This paper proposes a shift towards BP-free, zeroth-order (ZO) optimization as a solution for reducing memory costs during LLM fine-tuning, building on the initial concept introduced by MeZO. Unlike traditional ZO-SGD methods, our work expands the exploration to a wider array of ZO optimization techniques, through a comprehensive, first-of-its-kind benchmarking study across five LLM families (Roberta, OPT, LLaMA, Vicuna, Mistral), three task complexities, and five fine-tuning schemes. Our study unveils previously overlooked optimization principles, highlighting the importance of task alignment, the role of the forward gradient method, and the balance between algorithm complexity and fine-tuning performance. We further introduce novel enhancements to ZO optimization, including block-wise descent, hybrid training, and gradient sparsity. Our study offers a promising direction for achieving further memory-efficient LLM fine-tuning. Codes to reproduce all our experiments are at https://github.com/ZO-Bench/ZO-LLM .
5/29/2024
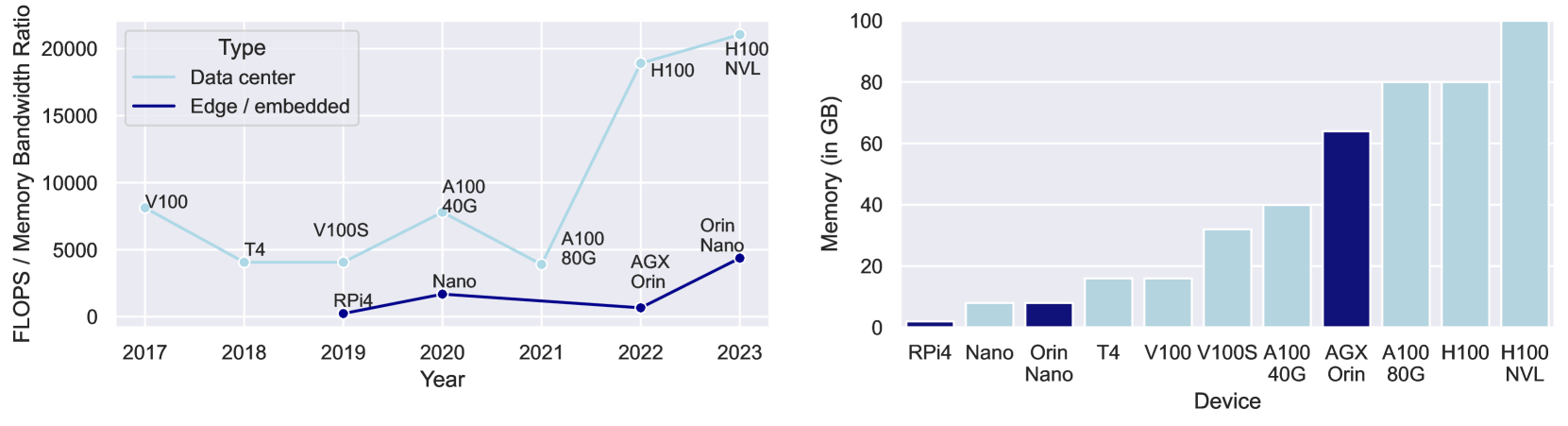
Federated Fine-Tuning of LLMs on the Very Edge: The Good, the Bad, the Ugly
Herbert Woisetschlager, Alexander Isenko, Shiqiang Wang, Ruben Mayer, Hans-Arno Jacobsen
0
0
Large Language Models (LLM) and foundation models are popular as they offer new opportunities for individuals and businesses to improve natural language processing, interact with data, and retrieve information faster. However, training or fine-tuning LLMs requires a vast amount of data, which can be challenging to access due to legal or technical restrictions and may require private computing resources. Federated Learning (FL) is a solution designed to overcome these challenges and expand data access for deep learning applications. This paper takes a hardware-centric approach to explore how LLMs can be brought to modern edge computing systems. Our study fine-tunes the FLAN-T5 model family, ranging from 80M to 3B parameters, using FL for a text summarization task. We provide a micro-level hardware benchmark, compare the model FLOP utilization to a state-of-the-art data center GPU, and study the network utilization in realistic conditions. Our contribution is twofold: First, we evaluate the current capabilities of edge computing systems and their potential for LLM FL workloads. Second, by comparing these systems with a data-center GPU, we demonstrate the potential for improvement and the next steps toward achieving greater computational efficiency at the edge.
5/3/2024
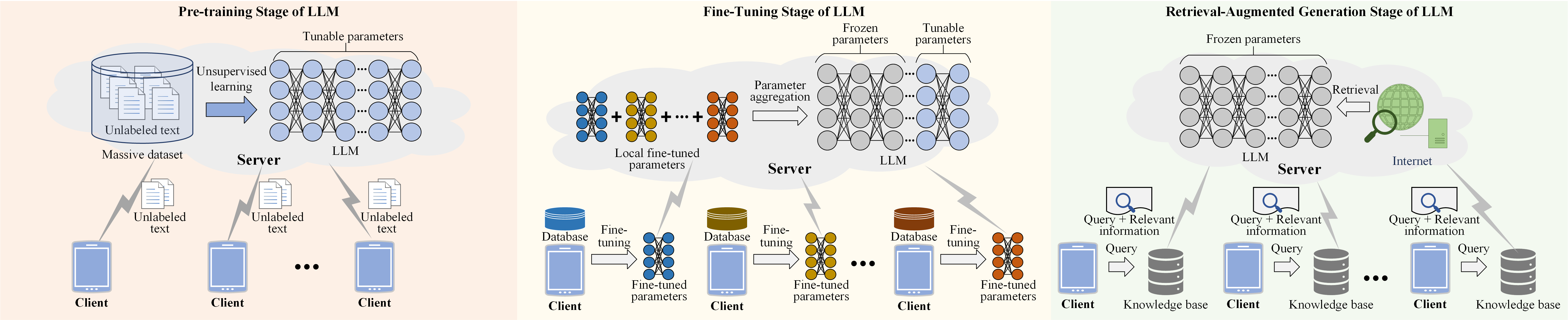
Personalized Wireless Federated Learning for Large Language Models
Feibo Jiang, Li Dong, Siwei Tu, Yubo Peng, Kezhi Wang, Kun Yang, Cunhua Pan, Dusit Niyato
0
0
Large Language Models (LLMs) have revolutionized natural language processing tasks. However, their deployment in wireless networks still face challenges, i.e., a lack of privacy and security protection mechanisms. Federated Learning (FL) has emerged as a promising approach to address these challenges. Yet, it suffers from issues including inefficient handling with big and heterogeneous data, resource-intensive training, and high communication overhead. To tackle these issues, we first compare different learning stages and their features of LLMs in wireless networks. Next, we introduce two personalized wireless federated fine-tuning methods with low communication overhead, i.e., (1) Personalized Federated Instruction Tuning (PFIT), which employs reinforcement learning to fine-tune local LLMs with diverse reward models to achieve personalization; (2) Personalized Federated Task Tuning (PFTT), which can leverage global adapters and local Low-Rank Adaptations (LoRA) to collaboratively fine-tune local LLMs, where the local LoRAs can be applied to achieve personalization without aggregation. Finally, we perform simulations to demonstrate the effectiveness of the proposed two methods and comprehensively discuss open issues.
4/23/2024