Federated Fine-Tuning of LLMs on the Very Edge: The Good, the Bad, the Ugly
2310.03150
0
0
Abstract
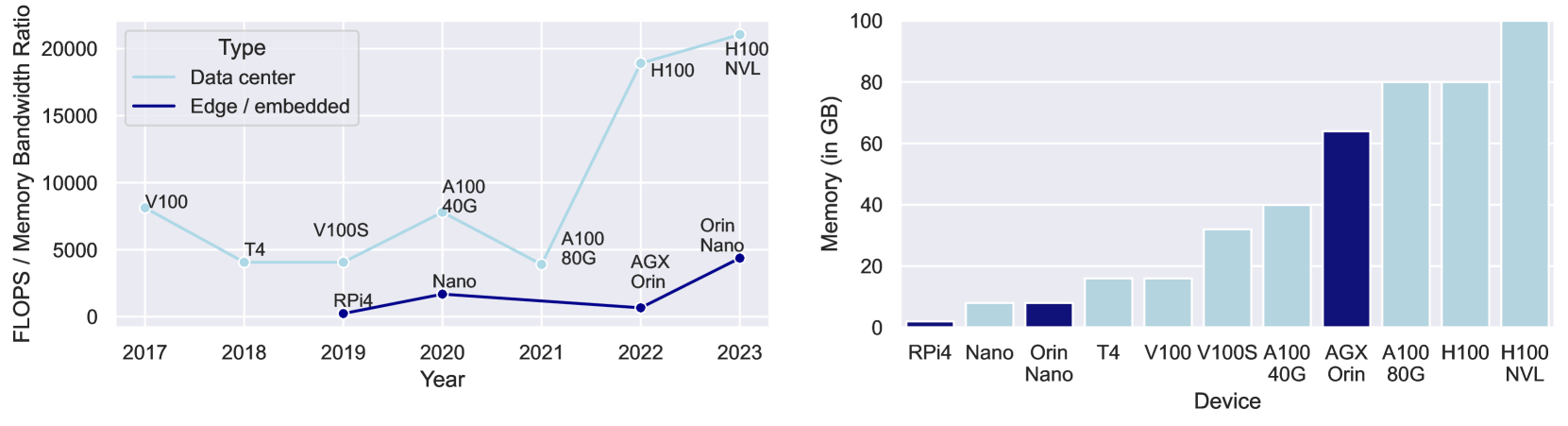
Large Language Models (LLM) and foundation models are popular as they offer new opportunities for individuals and businesses to improve natural language processing, interact with data, and retrieve information faster. However, training or fine-tuning LLMs requires a vast amount of data, which can be challenging to access due to legal or technical restrictions and may require private computing resources. Federated Learning (FL) is a solution designed to overcome these challenges and expand data access for deep learning applications. This paper takes a hardware-centric approach to explore how LLMs can be brought to modern edge computing systems. Our study fine-tunes the FLAN-T5 model family, ranging from 80M to 3B parameters, using FL for a text summarization task. We provide a micro-level hardware benchmark, compare the model FLOP utilization to a state-of-the-art data center GPU, and study the network utilization in realistic conditions. Our contribution is twofold: First, we evaluate the current capabilities of edge computing systems and their potential for LLM FL workloads. Second, by comparing these systems with a data-center GPU, we demonstrate the potential for improvement and the next steps toward achieving greater computational efficiency at the edge.
Create account to get full access
Overview
- This paper explores the opportunities and challenges of federated fine-tuning of large language models (LLMs) on edge devices.
- Federated learning allows LLMs to be customized for individual users or devices without compromising privacy, but implementing it on resource-constrained edge devices presents unique difficulties.
- The authors examine the "good, the bad, and the ugly" aspects of this approach, providing insights that can inform the development of practical federated learning systems for LLMs.
Plain English Explanation
Federated learning is a technique that allows machine learning models, like large language models (LLMs), to be personalized for individual users or devices without the need to share private data. Instead of sending data to a central server, the model is updated on each device and the updates are aggregated to improve the overall model.
This paper looks at the pros and cons of using federated learning to fine-tune LLMs on edge devices - that is, small, low-power devices like smartphones or IoT sensors, rather than in a central data center. The authors highlight the "good, the bad, and the ugly" aspects of this approach.
The "good" aspects include the ability to customize LLMs for specific user needs while preserving privacy. The "bad" includes the technical challenges of running complex machine learning models on resource-constrained edge devices. The "ugly" refers to potential issues like security vulnerabilities or unfairness that can arise when deploying federated learning systems in the real world.
By understanding these different facets, the researchers hope to provide insights that can guide the development of practical federated learning systems for LLMs, which could have important applications in areas like personalized assistants, healthcare, and edge computing.
Technical Explanation
The paper examines the feasibility and challenges of federated fine-tuning of large language models (LLMs) on edge devices. Federated learning allows LLMs to be customized for individual users or devices without the need to share private data, but implementing it on resource-constrained edge hardware presents unique difficulties.
The authors propose a federated fine-tuning framework that can efficiently update an LLM on edge devices. They evaluate this approach using the FedJUDGE, FedEval, and PersonalizedFL datasets, as well as a custom dataset for legal document summarization.
The key findings include:
- Federated fine-tuning can effectively customize LLMs for individual edge devices, but requires careful optimization of model size and training hyperparameters.
- There are significant challenges in terms of compute and memory constraints on edge devices, which can limit the model size and depth that can be effectively fine-tuned.
- Techniques like Automated Federated Pipeline and Agglomerative Federated Learning can help address these hardware limitations.
- Federated fine-tuning also raises potential issues around security, privacy, and fairness that must be carefully considered.
Overall, the paper provides a comprehensive analysis of the opportunities and challenges in deploying federated fine-tuning of LLMs on edge devices, offering guidance for future research and development in this area.
Critical Analysis
The paper provides a thorough and balanced examination of the "good, the bad, and the ugly" aspects of federated fine-tuning of LLMs on edge devices. The authors clearly identify the potential benefits, such as the ability to customize models for individual users while preserving privacy, as well as the significant technical challenges.
One limitation acknowledged in the paper is the use of simulated edge device environments, which may not fully capture the real-world constraints and performance characteristics of actual edge hardware. Further evaluation on physical edge devices could provide additional insights.
The authors also note potential security and fairness concerns that require careful consideration when deploying federated learning systems in practice. These include risks of model poisoning attacks and the potential for federated fine-tuning to exacerbate biases or create unfair disparities between users.
While the paper provides a comprehensive technical analysis, it would be helpful for the authors to explore the broader societal implications of this technology. For example, how might federated fine-tuning of LLMs on edge devices impact areas like healthcare, education, or personal digital assistants? What are the ethical considerations around the use of such systems?
Overall, this paper offers valuable contributions to the understanding of federated learning for LLMs on the edge, but additional research is needed to fully address the complex challenges and considerations involved in real-world deployment.
Conclusion
This paper presents a detailed examination of the opportunities and challenges in applying federated fine-tuning to large language models (LLMs) on edge devices. The authors highlight the "good" (personalization and privacy preservation), the "bad" (hardware constraints), and the "ugly" (security and fairness concerns) aspects of this approach.
The insights from this research can help guide the development of practical federated learning systems for LLMs, which have the potential to enable a wide range of personalized applications on resource-constrained edge devices. However, the authors also emphasize the need to carefully address the technical, security, and ethical considerations that come with deploying such systems in the real world.
As edge computing and federated learning continue to evolve, this paper provides a valuable framework for understanding the tradeoffs and challenges involved in bringing the power of LLMs to the very edge of the network.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
FedJudge: Federated Legal Large Language Model
Linan Yue, Qi Liu, Yichao Du, Weibo Gao, Ye Liu, Fangzhou Yao
0
0
Large Language Models (LLMs) have gained prominence in the field of Legal Intelligence, offering potential applications in assisting legal professionals and laymen. However, the centralized training of these Legal LLMs raises data privacy concerns, as legal data is distributed among various institutions containing sensitive individual information. This paper addresses this challenge by exploring the integration of Legal LLMs with Federated Learning (FL) methodologies. By employing FL, Legal LLMs can be fine-tuned locally on devices or clients, and their parameters are aggregated and distributed on a central server, ensuring data privacy without directly sharing raw data. However, computation and communication overheads hinder the full fine-tuning of LLMs under the FL setting. Moreover, the distribution shift of legal data reduces the effectiveness of FL methods. To this end, in this paper, we propose the first Federated Legal Large Language Model (FedJudge) framework, which fine-tunes Legal LLMs efficiently and effectively. Specifically, FedJudge utilizes parameter-efficient fine-tuning methods to update only a few additional parameters during the FL training. Besides, we explore the continual learning methods to preserve the global model's important parameters when training local clients to mitigate the problem of data shifts. Extensive experimental results on three real-world datasets clearly validate the effectiveness of FedJudge. Code is released at https://github.com/yuelinan/FedJudge.
4/11/2024
Personalized Wireless Federated Learning for Large Language Models
Feibo Jiang, Li Dong, Siwei Tu, Yubo Peng, Kezhi Wang, Kun Yang, Cunhua Pan, Dusit Niyato
0
0
Large Language Models (LLMs) have revolutionized natural language processing tasks. However, their deployment in wireless networks still face challenges, i.e., a lack of privacy and security protection mechanisms. Federated Learning (FL) has emerged as a promising approach to address these challenges. Yet, it suffers from issues including inefficient handling with big and heterogeneous data, resource-intensive training, and high communication overhead. To tackle these issues, we first compare different learning stages and their features of LLMs in wireless networks. Next, we introduce two personalized wireless federated fine-tuning methods with low communication overhead, i.e., (1) Personalized Federated Instruction Tuning (PFIT), which employs reinforcement learning to fine-tune local LLMs with diverse reward models to achieve personalization; (2) Personalized Federated Task Tuning (PFTT), which can leverage global adapters and local Low-Rank Adaptations (LoRA) to collaboratively fine-tune local LLMs, where the local LoRAs can be applied to achieve personalization without aggregation. Finally, we perform simulations to demonstrate the effectiveness of the proposed two methods and comprehensively discuss open issues.
4/23/2024
💬
Federated Fine-tuning of Large Language Models under Heterogeneous Tasks and Client Resources
Jiamu Bai, Daoyuan Chen, Bingchen Qian, Liuyi Yao, Yaliang Li
0
0
Federated Learning (FL) has recently been applied to the parameter-efficient fine-tuning of Large Language Models (LLMs). While promising, it raises significant challenges due to the heterogeneous resources and data distributions of clients. This study introduces FlexLoRA, a simple yet effective aggregation scheme for LLM fine-tuning, which mitigates the ``bucket effect'' in traditional FL that restricts the potential of clients with ample resources by tying them to the capabilities of the least-resourced participants. FlexLoRA allows for dynamic adjustment of local LoRA ranks, fostering the development of a global model imbued with broader, less task-specific knowledge. By synthesizing a full-size LoRA weight from individual client contributions and employing Singular Value Decomposition (SVD) for weight redistribution, FlexLoRA fully leverages heterogeneous client resources. Involving thousands of clients performing heterogeneous NLP tasks and client resources, our experiments validate the efficacy of FlexLoRA, with the federated global model achieving consistently better improvement over SOTA FL methods in downstream NLP task performance across various heterogeneous distributions. FlexLoRA's practicality is further underscored by our theoretical analysis and its seamless integration with existing LoRA-based FL methods, offering a path toward cross-device, privacy-preserving federated tuning for LLMs.
5/31/2024

Automated Federated Pipeline for Parameter-Efficient Fine-Tuning of Large Language Models
Zihan Fang, Zheng Lin, Zhe Chen, Xianhao Chen, Yue Gao, Yuguang Fang
0
0
Recently, there has been a surge in the development of advanced intelligent generative content (AIGC), especially large language models (LLMs). However, for many downstream tasks, it is necessary to fine-tune LLMs using private data. While federated learning offers a promising privacy-preserving solution to LLM fine-tuning, the substantial size of an LLM, combined with high computational and communication demands, makes it hard to apply to downstream tasks. More importantly, private edge servers often possess varying computing and network resources in real-world scenarios, introducing additional complexities to LLM fine-tuning. To tackle these problems, we design and implement an automated federated pipeline, named FedPipe, to fine-tune LLMs with minimal training cost but without adding any inference latency. FedPipe firstly identifies the weights to be fine-tuned based on their contributions to the LLM training. It then configures a low-rank adapter for each selected weight to train local low-rank adapters on an edge server, and aggregate local adapters of all edge servers to fine-tune the whole LLM. Finally, it appropriately quantizes the parameters of LLM to reduce memory space according to the requirements of edge servers. Extensive experiments demonstrate that FedPipe expedites the model training and achieves higher accuracy than state-of-the-art benchmarks.
4/10/2024