Convolutional variational autoencoders for secure lossy image compression in remote sensing
2404.03696
0
0

Abstract
The volume of remote sensing data is experiencing rapid growth, primarily due to the plethora of space and air platforms equipped with an array of sensors. Due to limited hardware and battery constraints the data is transmitted back to Earth for processing. The large amounts of data along with security concerns call for new compression and encryption techniques capable of preserving reconstruction quality while minimizing the transmission cost of this data back to Earth. This study investigates image compression based on convolutional variational autoencoders (CVAE), which are capable of substantially reducing the volume of transmitted data while guaranteeing secure lossy image reconstruction. CVAEs have been demonstrated to outperform conventional compression methods such as JPEG2000 by a substantial margin on compression benchmark datasets. The proposed model draws on the strength of the CVAEs capability to abstract data into highly insightful latent spaces, and combining it with the utilization of an entropy bottleneck is capable of finding an optimal balance between compressibility and reconstruction quality. The balance is reached by optimizing over a composite loss function that represents the rate-distortion curve.
Create account to get full access
Overview
- This paper presents a new approach for secure and efficient lossy image compression in remote sensing applications using convolutional variational autoencoders (CVAEs).
- The proposed method aims to address the challenges of traditional compression techniques, which can be vulnerable to adversarial attacks and fail to provide adequate security.
- The authors demonstrate the effectiveness of their CVAE-based compression framework in terms of compression ratio, reconstruction quality, and security against various attacks.
Plain English Explanation
The paper discusses a new way to compress satellite images while also keeping them secure. Traditionally, compressing images can make them vulnerable to attacks where the compressed data is tampered with. The researchers in this paper use a type of artificial intelligence called a convolutional variational autoencoder (CVAE) to compress the images in a more secure way.
A CVAE is a machine learning model that can take an image, shrink it down into a smaller, compressed version, and then reconstruct the original image from the compressed version. The key innovation in this paper is using the CVAE in a way that makes the compressed image data more resistant to tampering or attacks.
The authors show that their CVAE-based compression approach can achieve good compression ratios, meaning the compressed images are much smaller than the originals, while also maintaining high quality in the reconstructed images. Importantly, they demonstrate that the compressed images are also more secure and less vulnerable to different types of attacks compared to traditional compression methods.
Technical Explanation
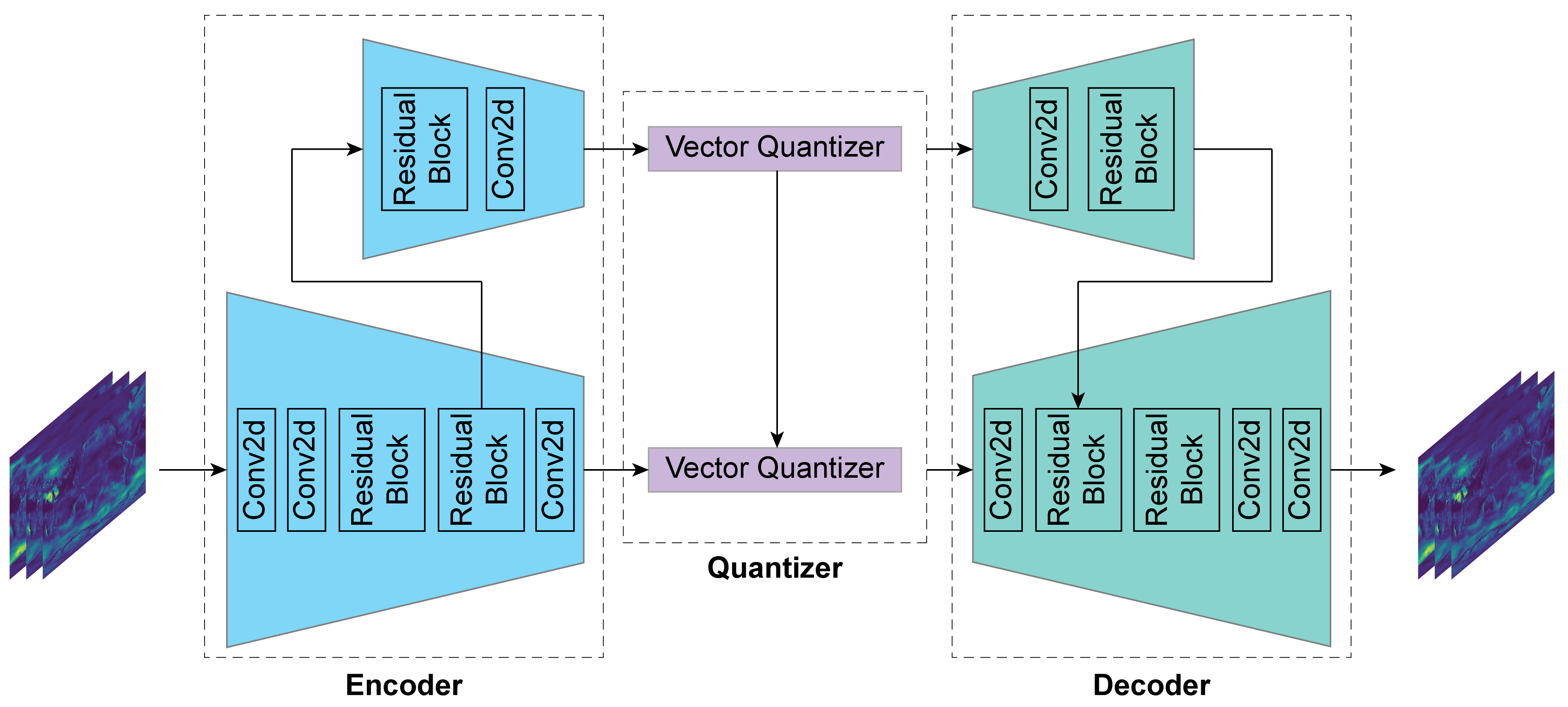
The paper proposes a novel compression framework based on convolutional variational autoencoders (CVAEs) for secure lossy compression of satellite images. CVAEs are a type of deep learning model that can learn a compact latent representation of input images, which can then be used for efficient compression and reconstruction.
The key aspects of the proposed CVAE-based compression framework are:
- Architecture: The CVAE encoder consists of convolutional layers that map the input image to a low-dimensional latent representation. The decoder uses transposed convolutions to reconstruct the image from the latent code.
- Training: The CVAE is trained end-to-end using a combination of reconstruction loss and a Kullback-Leibler divergence term to encourage a Gaussian latent distribution, which enhances the security properties.
- Compression and Decompression: To compress an image, the encoder maps it to the latent code, which is then quantized and entropy-coded. Decompression is achieved by decoding the latent code through the decoder.
- Security Evaluation: The authors assess the security of the compressed images against various adversarial attacks, such as image manipulation and latent code tampering, and compare the results to traditional JPEG compression.
The experimental results on a remote sensing dataset demonstrate that the proposed CVAE-based compression approach achieves competitive compression ratios and reconstruction quality, while also providing improved security against different attack scenarios compared to JPEG compression.
Critical Analysis
The paper presents a promising approach for secure lossy image compression in remote sensing applications. The use of CVAEs for this task is well-motivated, as the latent representation learned by the model can be designed to have desirable security properties.
However, the paper could be strengthened by addressing a few potential limitations:
- Generalization to other datasets: The evaluation is limited to a single remote sensing dataset, so it would be valuable to assess the performance and security of the proposed method on a broader range of satellite imagery data.
- Computational complexity: While the CVAE-based approach aims to provide security, the added complexity of the model architecture and training process may have implications for the computational and memory requirements compared to traditional compression methods. The authors could discuss the trade-offs in this regard.
- Real-world deployment considerations: The paper does not delve into the practical challenges of deploying a CVAE-based compression system in real-world remote sensing applications, such as integration with existing workflows, transmission bandwidth limitations, or end-user device capabilities. Addressing these aspects could enhance the relevance and impact of the research.
Overall, the CVAE-based compression framework presented in this paper is a valuable contribution to the field of secure lossy compression for scientific datasets, and the authors' evaluation of its security properties is an important step forward. Further research and real-world validation would help solidify the practical applicability of this approach.
Conclusion
This paper introduces a novel convolutional variational autoencoder (CVAE)-based framework for secure and efficient lossy compression of satellite images. The proposed method addresses the limitations of traditional compression techniques, which can be vulnerable to adversarial attacks and fail to provide adequate security.
The CVAE-based compression approach demonstrated competitive compression ratios and reconstruction quality, while also exhibiting improved security against various attack scenarios compared to JPEG compression. This work contributes to the ongoing efforts to develop robust and secure compression solutions for remote sensing applications, where the integrity and confidentiality of the image data are crucial.
The CVAE-based compression framework presented in this paper represents a promising direction for further research and development in the field of secure lossy image compression, with potential implications for a wide range of remote sensing and other data-intensive applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Hierarchical Autoencoder-based Lossy Compression for Large-scale High-resolution Scientific Data
Hieu Le, Jian Tao
0
0
Lossy compression has become an important technique to reduce data size in many domains. This type of compression is especially valuable for large-scale scientific data, whose size ranges up to several petabytes. Although Autoencoder-based models have been successfully leveraged to compress images and videos, such neural networks have not widely gained attention in the scientific data domain. Our work presents a neural network that not only significantly compresses large-scale scientific data, but also maintains high reconstruction quality. The proposed model is tested with scientific benchmark data available publicly and applied to a large-scale high-resolution climate modeling data set. Our model achieves a compression ratio of 140 on several benchmark data sets without compromising the reconstruction quality. 2D simulation data from the High-Resolution Community Earth System Model (CESM) Version 1.3 over 500 years are also being compressed with a compression ratio of 200 while the reconstruction error is negligible for scientific analysis.
5/8/2024
🌀
LiteVAE: Lightweight and Efficient Variational Autoencoders for Latent Diffusion Models
Seyedmorteza Sadat, Jakob Buhmann, Derek Bradley, Otmar Hilliges, Romann M. Weber
0
0
Advances in latent diffusion models (LDMs) have revolutionized high-resolution image generation, but the design space of the autoencoder that is central to these systems remains underexplored. In this paper, we introduce LiteVAE, a family of autoencoders for LDMs that leverage the 2D discrete wavelet transform to enhance scalability and computational efficiency over standard variational autoencoders (VAEs) with no sacrifice in output quality. We also investigate the training methodologies and the decoder architecture of LiteVAE and propose several enhancements that improve the training dynamics and reconstruction quality. Our base LiteVAE model matches the quality of the established VAEs in current LDMs with a six-fold reduction in encoder parameters, leading to faster training and lower GPU memory requirements, while our larger model outperforms VAEs of comparable complexity across all evaluated metrics (rFID, LPIPS, PSNR, and SSIM).
5/24/2024
Towards Extreme Image Compression with Latent Feature Guidance and Diffusion Prior
Zhiyuan Li, Yanhui Zhou, Hao Wei, Chenyang Ge, Jingwen Jiang
0
0
Image compression at extremely low bitrates (below 0.1 bits per pixel (bpp)) is a significant challenge due to substantial information loss. In this work, we propose a novel two-stage extreme image compression framework that exploits the powerful generative capability of pre-trained diffusion models to achieve realistic image reconstruction at extremely low bitrates. In the first stage, we treat the latent representation of images in the diffusion space as guidance, employing a VAE-based compression approach to compress images and initially decode the compressed information into content variables. The second stage leverages pre-trained stable diffusion to reconstruct images under the guidance of content variables. Specifically, we introduce a small control module to inject content information while keeping the stable diffusion model fixed to maintain its generative capability. Furthermore, we design a space alignment loss to force the content variables to align with the diffusion space and provide the necessary constraints for optimization. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art approaches in terms of visual performance at extremely low bitrates.
6/14/2024

Capsule Enhanced Variational AutoEncoder for Underwater Image Reconstruction
Rita Pucci, Niki Martinel
0
0
Underwater image analysis is crucial for marine monitoring. However, it presents two major challenges (i) the visual quality of the images is often degraded due to wavelength-dependent light attenuation, scattering, and water types; (ii) capturing and storing high-resolution images is limited by hardware, which hinders long-term environmental analyses. Recently, deep neural networks have been introduced for underwater enhancement yet neglecting the challenge posed by the limitations of autonomous underwater image acquisition systems. We introduce a novel architecture that jointly tackles both issues by drawing inspiration from the discrete features quantization approach of Vector Quantized Variational Autoencoder (myVQVAE). Our model combines an encoding network, that compresses the input into a latent representation, with two independent decoding networks, that enhance/reconstruct images using only the latent representation. One decoder focuses on the spatial information while the other captures information about the entities in the image by leveraging the concept of capsules. With the usage of capsule layers, we also overcome the differentiabilty issues of myVQVAE making our solution trainable in an end-to-end fashion without the need for particular optimization tricks. Capsules perform feature quantization in a fully differentiable manner. We conducted thorough quantitative and qualitative evaluations on 6 benchmark datasets to assess the effectiveness of our contributions. Results demonstrate that we perform better than existing methods (eg, about $+1.4dB$ gain on the challenging LSUI Test-L400 dataset), while significantly reducing the amount of space needed for data storage (ie, $3times$ more efficient).
6/4/2024