LiteVAE: Lightweight and Efficient Variational Autoencoders for Latent Diffusion Models
2405.14477
0
0
🌀
Abstract
Advances in latent diffusion models (LDMs) have revolutionized high-resolution image generation, but the design space of the autoencoder that is central to these systems remains underexplored. In this paper, we introduce LiteVAE, a family of autoencoders for LDMs that leverage the 2D discrete wavelet transform to enhance scalability and computational efficiency over standard variational autoencoders (VAEs) with no sacrifice in output quality. We also investigate the training methodologies and the decoder architecture of LiteVAE and propose several enhancements that improve the training dynamics and reconstruction quality. Our base LiteVAE model matches the quality of the established VAEs in current LDMs with a six-fold reduction in encoder parameters, leading to faster training and lower GPU memory requirements, while our larger model outperforms VAEs of comparable complexity across all evaluated metrics (rFID, LPIPS, PSNR, and SSIM).
Create account to get full access
Overview
- Latent diffusion models (LDMs) have revolutionized high-resolution image generation, but the design of the central autoencoder remains underexplored.
- This paper introduces LiteVAE, a family of autoencoders for LDMs that use the 2D discrete wavelet transform to enhance scalability and efficiency over standard variational autoencoders (VAEs).
- The authors investigate training methodologies and decoder architecture, proposing enhancements to improve training dynamics and reconstruction quality.
Plain English Explanation
LDMs are a type of AI model that can generate high-quality, detailed images. However, the core component of these models, the autoencoder, has not been fully optimized. This paper introduces a new family of autoencoders called LiteVAE that use a mathematical technique called the 2D discrete wavelet transform to make the models more scalable and efficient, without sacrificing the quality of the generated images.
The researchers also looked at how to best train these LiteVAE models and redesigned the decoder part of the model to further improve the training process and the final image quality. Compared to the standard VAE autoencoders used in current LDMs, the base LiteVAE model can match the output quality while using six times fewer parameters in the encoder, leading to faster training and lower memory requirements on the GPU. An even larger LiteVAE model can outperform the standard VAEs across various metrics like image similarity and sharpness.
Technical Explanation
The core innovation of this work is the LiteVAE family of autoencoders, which leverage the 2D discrete wavelet transform to enhance the scalability and computational efficiency of VAEs used in LDMs. Typically, VAEs like those used in secure image compression have a large number of parameters in the encoder, which can make training slower and require more GPU memory.
LiteVAE addresses this by using the wavelet transform to decompose the input image into multiple frequency bands, which are then encoded separately. This allows the encoder to be much more compact while still capturing the relevant visual information. The authors also investigate the training methodology and decoder architecture, proposing several enhancements to improve the training dynamics and reconstruction quality.
Experiments show that the base LiteVAE model can match the output quality of established VAEs used in LDMs, but with a six-fold reduction in encoder parameters. This leads to faster training and lower GPU memory requirements. The larger LiteVAE model can even outperform the standard VAEs across various evaluation metrics like Learned Perceptual Image Patch Similarity (LPIPS), Peak Signal-to-Noise Ratio (PSNR), and Structural Similarity Index (SSIM).
Critical Analysis
The paper provides a thorough evaluation of the LiteVAE models, including comparisons to standard VAEs on a range of image quality metrics. However, the authors do not discuss any potential limitations or caveats of their approach.
One area that could be explored further is the impact of the wavelet decomposition on the latent representations learned by the model. While the wavelet transform allows for a more compact encoder, it may also introduce biases or distortions that could affect the downstream performance of the diffusion model. Further research could investigate the properties of the LiteVAE latent space and how it compares to standard VAE latents.
Additionally, the paper focuses on image reconstruction quality, but does not examine the performance of LiteVAE when used as the autoencoder component of a full LDM system. Real-world deployment and evaluation of LiteVAE in end-to-end LDM pipelines would provide valuable insights into its practical benefits and limitations.
Conclusion
This paper presents LiteVAE, a family of efficient autoencoders for latent diffusion models that leverage the 2D discrete wavelet transform. The LiteVAE models can match or exceed the output quality of standard VAEs while using significantly fewer encoder parameters, leading to faster training and lower GPU memory requirements.
The innovations in LiteVAE architecture and training methodologies demonstrate the potential for further optimizing the core components of LDMs to improve their scalability and accessibility. As these generative models become more widely adopted, continued research into more efficient and effective autoencoder designs will be crucial for unlocking their full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CV-VAE: A Compatible Video VAE for Latent Generative Video Models
Sijie Zhao, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Muyao Niu, Xiaoyu Li, Wenbo Hu, Ying Shan
0
0
Spatio-temporal compression of videos, utilizing networks such as Variational Autoencoders (VAE), plays a crucial role in OpenAI's SORA and numerous other video generative models. For instance, many LLM-like video models learn the distribution of discrete tokens derived from 3D VAEs within the VQVAE framework, while most diffusion-based video models capture the distribution of continuous latent extracted by 2D VAEs without quantization. The temporal compression is simply realized by uniform frame sampling which results in unsmooth motion between consecutive frames. Currently, there lacks of a commonly used continuous video (3D) VAE for latent diffusion-based video models in the research community. Moreover, since current diffusion-based approaches are often implemented using pre-trained text-to-image (T2I) models, directly training a video VAE without considering the compatibility with existing T2I models will result in a latent space gap between them, which will take huge computational resources for training to bridge the gap even with the T2I models as initialization. To address this issue, we propose a method for training a video VAE of latent video models, namely CV-VAE, whose latent space is compatible with that of a given image VAE, e.g., image VAE of Stable Diffusion (SD). The compatibility is achieved by the proposed novel latent space regularization, which involves formulating a regularization loss using the image VAE. Benefiting from the latent space compatibility, video models can be trained seamlessly from pre-trained T2I or video models in a truly spatio-temporally compressed latent space, rather than simply sampling video frames at equal intervals. With our CV-VAE, existing video models can generate four times more frames with minimal finetuning. Extensive experiments are conducted to demonstrate the effectiveness of the proposed video VAE.
5/31/2024
🔎
Poisson Variational Autoencoder
Hadi Vafaii, Dekel Galor, Jacob L. Yates
0
0
Variational autoencoders (VAE) employ Bayesian inference to interpret sensory inputs, mirroring processes that occur in primate vision across both ventral (Higgins et al., 2021) and dorsal (Vafaii et al., 2023) pathways. Despite their success, traditional VAEs rely on continuous latent variables, which deviates sharply from the discrete nature of biological neurons. Here, we developed the Poisson VAE (P-VAE), a novel architecture that combines principles of predictive coding with a VAE that encodes inputs into discrete spike counts. Combining Poisson-distributed latent variables with predictive coding introduces a metabolic cost term in the model loss function, suggesting a relationship with sparse coding which we verify empirically. Additionally, we analyze the geometry of learned representations, contrasting the P-VAE to alternative VAE models. We find that the P-VAEencodes its inputs in relatively higher dimensions, facilitating linear separability of categories in a downstream classification task with a much better (5x) sample efficiency. Our work provides an interpretable computational framework to study brain-like sensory processing and paves the way for a deeper understanding of perception as an inferential process.
5/24/2024

Convolutional variational autoencoders for secure lossy image compression in remote sensing
Alessandro Giuliano, S. Andrew Gadsden, Waleed Hilal, John Yawney
0
0
The volume of remote sensing data is experiencing rapid growth, primarily due to the plethora of space and air platforms equipped with an array of sensors. Due to limited hardware and battery constraints the data is transmitted back to Earth for processing. The large amounts of data along with security concerns call for new compression and encryption techniques capable of preserving reconstruction quality while minimizing the transmission cost of this data back to Earth. This study investigates image compression based on convolutional variational autoencoders (CVAE), which are capable of substantially reducing the volume of transmitted data while guaranteeing secure lossy image reconstruction. CVAEs have been demonstrated to outperform conventional compression methods such as JPEG2000 by a substantial margin on compression benchmark datasets. The proposed model draws on the strength of the CVAEs capability to abstract data into highly insightful latent spaces, and combining it with the utilization of an entropy bottleneck is capable of finding an optimal balance between compressibility and reconstruction quality. The balance is reached by optimizing over a composite loss function that represents the rate-distortion curve.
4/8/2024
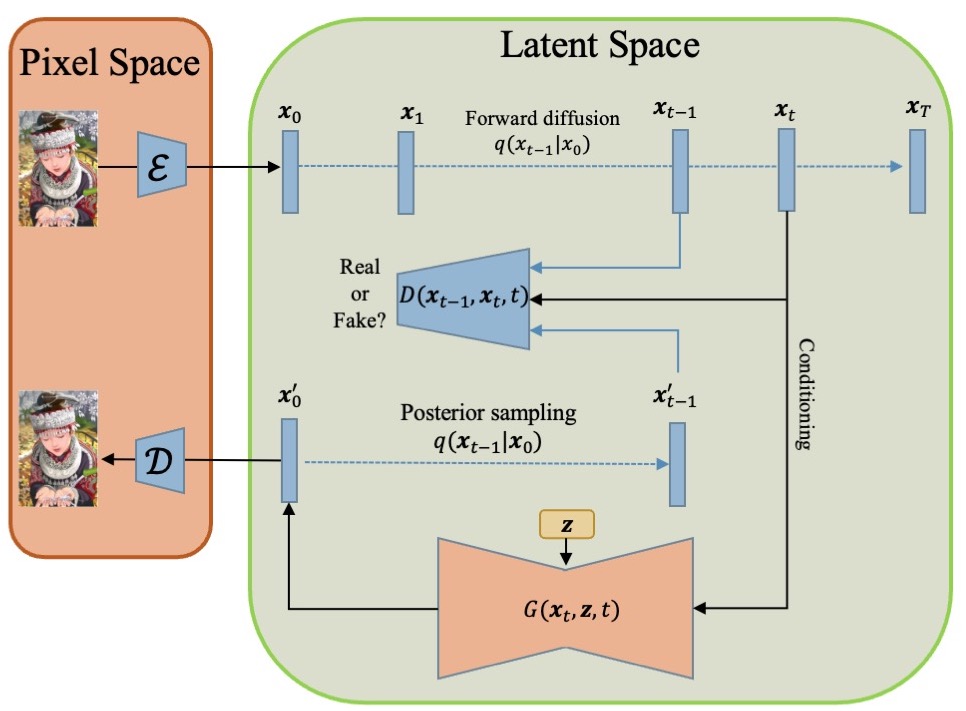
Latent Denoising Diffusion GAN: Faster sampling, Higher image quality
Luan Thanh Trinh, Tomoki Hamagami
0
0
Diffusion models are emerging as powerful solutions for generating high-fidelity and diverse images, often surpassing GANs under many circumstances. However, their slow inference speed hinders their potential for real-time applications. To address this, DiffusionGAN leveraged a conditional GAN to drastically reduce the denoising steps and speed up inference. Its advancement, Wavelet Diffusion, further accelerated the process by converting data into wavelet space, thus enhancing efficiency. Nonetheless, these models still fall short of GANs in terms of speed and image quality. To bridge these gaps, this paper introduces the Latent Denoising Diffusion GAN, which employs pre-trained autoencoders to compress images into a compact latent space, significantly improving inference speed and image quality. Furthermore, we propose a Weighted Learning strategy to enhance diversity and image quality. Experimental results on the CIFAR-10, CelebA-HQ, and LSUN-Church datasets prove that our model achieves state-of-the-art running speed among diffusion models. Compared to its predecessors, DiffusionGAN and Wavelet Diffusion, our model shows remarkable improvements in all evaluation metrics. Code and pre-trained checkpoints: url{https://github.com/thanhluantrinh/LDDGAN.git}
6/18/2024