Cool-Fusion: Fuse Large Language Models without Training

0

Sign in to get full access
Overview
- The paper proposes a method called "Cool-Fusion" to fuse large language models (LLMs) without requiring fine-tuning.
- This allows combining the capabilities of multiple LLMs to improve performance on various tasks.
- The approach is designed to be efficient and easy to implement, making it accessible for practical applications.
Plain English Explanation
Cool-Fusion is a technique that lets you combine the strengths of different large language models (LLMs) without having to retrain them. LLMs are powerful AI systems that can understand and generate human-like text, but each one has its own unique capabilities.
The key idea behind Cool-Fusion is to find a way to fuse or merge these different LLMs together, so you can get the best of what each one has to offer. This is useful because it means you don't have to go through the time-consuming and expensive process of fine-tuning or retraining the models from scratch. Instead, you can just take the pre-trained models and combine them in a smart way.
The paper shows that this Cool-Fusion approach can improve performance on a variety of language tasks, like answering questions or translating between languages. And it does this in an efficient and easy-to-use way, making it practical for real-world applications.
Technical Explanation
The Cool-Fusion approach works by learning a set of weights that can be applied to the outputs of multiple pre-trained LLMs to produce a combined output. This is done without having to retrain or fine-tune the original LLMs.
The key steps are:
-
Model Selection: The researcher selects a set of pre-trained LLMs they want to combine, such as GPT-3, BERT, and RoBERTa.
-
Prompting: For a given input, each LLM is prompted to generate an output. This produces a set of outputs, one from each model.
-
Fusion: A fusion module is then used to combine the outputs from the different LLMs. This fusion module learns a set of weights that are applied to the individual model outputs to produce the final combined output.
-
Optimization: The fusion module is trained to optimize the combined output for a particular task, such as question answering or language translation. This is done without modifying the underlying LLMs.
The key advantage of this approach is that it allows you to leverage the capabilities of multiple pre-trained LLMs without having to retrain them from scratch. This can be much more efficient and practical than fine-tuning each model individually.
Critical Analysis
The Cool-Fusion paper presents a promising approach for combining large language models, but there are a few potential limitations and areas for further research:
-
Model Compatibility: The paper doesn't address how well the Cool-Fusion approach would work if the selected LLMs have very different architectures or capabilities. More research may be needed to understand the limits of model compatibility.
-
Task Generalization: While the experiments show improvements on a few specific tasks, it's unclear how well the Cool-Fusion approach would generalize to a wider range of language tasks. Further testing on a broader set of benchmarks would be helpful.
-
Interpretability: The fusion module in Cool-Fusion acts as a black box, combining the LLM outputs in a way that may be difficult to interpret. Investigating ways to make the fusion process more transparent could be valuable.
-
Computational Efficiency: The paper doesn't provide detailed information on the computational cost and runtime of the Cool-Fusion approach. Understanding the efficiency tradeoffs compared to other LLM combination methods would be useful.
Overall, the Cool-Fusion technique is an interesting and potentially impactful contribution to the field of large language model combination. Further research to address these limitations could help unlock the full potential of this approach.
Conclusion
The Cool-Fusion paper introduces a novel method for fusing multiple pre-trained large language models without the need for expensive fine-tuning. This allows the capabilities of different LLMs to be combined in a practical and efficient way, potentially improving performance on a variety of language tasks.
While the paper presents promising results, there are some areas for further exploration, such as model compatibility, task generalization, interpretability, and computational efficiency. Addressing these aspects could help make Cool-Fusion an even more powerful and versatile tool for leveraging the collective knowledge and abilities of large language models.
Overall, this research represents an important step forward in the quest to unlock the full potential of large language models and make them more accessible and useful for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cool-Fusion: Fuse Large Language Models without Training
Cong Liu, Xiaojun Quan, Yan Pan, Liang Lin, Weigang Wu, Xu Chen
We focus on the problem of fusing two or more heterogeneous large language models (LLMs) to facilitate their complementary strengths. One of the challenges on model fusion is high computational load, i.e. to fine-tune or to align vocabularies via combinatorial optimization. To this end, we propose emph{Cool-Fusion}, a simple yet effective approach that fuses the knowledge of heterogeneous source LLMs to leverage their complementary strengths. emph{Cool-Fusion} is the first method that does not require any type of training like the ensemble approaches. But unlike ensemble methods, it is applicable to any set of source LLMs that have different vocabularies. The basic idea is to have each source LLM individually generate tokens until the tokens can be decoded into a text segment that ends at word boundaries common to all source LLMs. Then, the source LLMs jointly rerank the generated text segment and select the best one, which is the fused text generation in one step. Extensive experiments are conducted across a variety of benchmark datasets. On emph{GSM8K}, emph{Cool-Fusion} increases accuracy from three strong source LLMs by a significant 8%-17.8%.
Read more7/30/2024
0
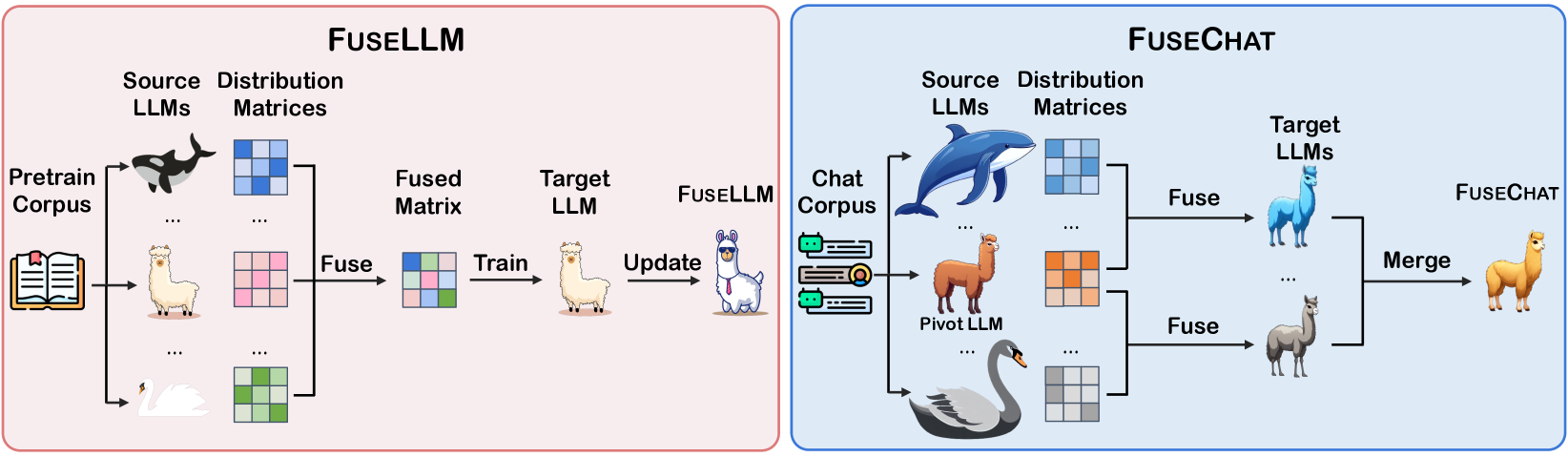
FuseChat: Knowledge Fusion of Chat Models
Fanqi Wan, Longguang Zhong, Ziyi Yang, Ruijun Chen, Xiaojun Quan
While training large language models (LLMs) from scratch can indeed lead to models with distinct capabilities and strengths, it incurs substantial costs and may lead to redundancy in competencies. Knowledge fusion aims to integrate existing LLMs of diverse architectures and capabilities into a more potent LLM through lightweight continual training, thereby reducing the need for costly LLM development. In this work, we propose a new framework for the knowledge fusion of chat LLMs through two main stages, resulting in FuseChat. Firstly, we conduct pairwise knowledge fusion on source chat LLMs of varying structures and scales to create multiple target LLMs with identical structure and size via lightweight fine-tuning. During this process, a statistics-based token alignment approach is introduced as the cornerstone for fusing LLMs with different structures. Secondly, we merge these target LLMs within the parameter space, where we propose a novel method for determining the merging coefficients based on the magnitude of parameter updates before and after fine-tuning. We implement and validate FuseChat using six prominent chat LLMs with diverse architectures and scales, including OpenChat-3.5-7B, Starling-LM-7B-alpha, NH2-SOLAR-10.7B, InternLM2-Chat-20B, Mixtral-8x7B-Instruct, and Qwen-1.5-Chat-72B. Experimental results on two instruction-following benchmarks, AlpacaEval 2.0 and MT-Bench, demonstrate the superiority of FuseChat-7B over baselines of various sizes. Our model is even comparable to the larger Mixtral-8x7B-Instruct and approaches GPT-3.5-Turbo-1106 on MT-Bench. Our code, model weights, and data are public at url{https://github.com/fanqiwan/FuseAI}.
Read more8/16/2024
💬
0
On-the-Fly Fusion of Large Language Models and Machine Translation
Hieu Hoang, Huda Khayrallah, Marcin Junczys-Dowmunt
We propose the on-the-fly ensembling of a machine translation model with an LLM, prompted on the same task and input. We perform experiments on 4 language pairs (both directions) with varying data amounts. We find that a slightly weaker-at-translation LLM can improve translations of a NMT model, and ensembling with an LLM can produce better translations than ensembling two stronger MT models. We combine our method with various techniques from LLM prompting, such as in context learning and translation context.
Read more5/7/2024

0
FuseChat: Knowledge Fusion of Chat Models
Fanqi Wan, Ziyi Yang, Longguang Zhong, Xiaojun Quan, Xinting Huang, Wei Bi
Recently, FuseLLM introduced the concept of knowledge fusion to transfer the collective knowledge of multiple structurally varied LLMs into a target LLM through lightweight continual training. In this report, we extend the scalability and flexibility of the FuseLLM framework to realize the fusion of chat LLMs, resulting in FusionChat. FusionChat comprises two main stages. Firstly, we undertake knowledge fusion for structurally and scale-varied source LLMs to derive multiple target LLMs of identical structure and size via lightweight fine-tuning. Then, these target LLMs are merged within the parameter space, wherein we propose a novel method for determining the merging weights based on the variation ratio of parameter matrices before and after fine-tuning. We validate our approach using three prominent chat LLMs with diverse architectures and scales, namely NH2-Mixtral-8x7B, NH2-Solar-10.7B, and OpenChat-3.5-7B. Experimental results spanning various chat domains demonstrate the superiority of FusionChat-7B across a broad spectrum of chat LLMs at 7B and 34B scales, even surpassing GPT-3.5 (March) and approaching Mixtral-8x7B-Instruct.
Read more5/29/2024