On-the-Fly Fusion of Large Language Models and Machine Translation
2311.08306
0
0
💬
Abstract
We propose the on-the-fly ensembling of a machine translation model with an LLM, prompted on the same task and input. We perform experiments on 4 language pairs (both directions) with varying data amounts. We find that a slightly weaker-at-translation LLM can improve translations of a NMT model, and ensembling with an LLM can produce better translations than ensembling two stronger MT models. We combine our method with various techniques from LLM prompting, such as in context learning and translation context.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper proposes a method to improve machine translation (MT) models by ensembling them with large language models (LLMs) on the same translation task.
- Experiments are conducted on 4 language pairs in both directions, with varying amounts of training data.
- The key finding is that a weaker LLM can enhance the performance of an MT model, and ensembling with an LLM can produce better translations than ensembling two stronger MT models.
- The method incorporates techniques from LLM prompting, such as in-context learning and translation context.
Plain English Explanation
The researchers have developed a way to make machine translation (MT) models better at translating text by combining them with large language models (LLMs). LLMs are AI systems trained on massive amounts of text data, which allows them to understand and generate human-like language.
The researchers found that even an LLM that isn't as good at translation as the MT model can still improve the MT model's translations when the two are used together. This is because the LLM can provide additional context and understanding that the MT model can use to produce better translations.
The researchers tested their method on 4 different language pairs, translating in both directions (e.g., English to French and French to English). They varied the amount of training data the MT models had, and found that the LLM-based approach worked well regardless of the MT model's performance.
The researchers also incorporated some advanced techniques from LLM prompting, such as in-context learning and translation context, to further enhance the translation quality.
Technical Explanation
The paper presents a novel approach for improving machine translation (MT) models by ensembling them with large language models (LLMs) on the same translation task. The researchers conducted experiments on 4 language pairs (in both directions) with varying amounts of training data for the MT models.
The key insight is that even an LLM that is slightly weaker at translation than the MT model can still enhance the MT model's performance when the two are used together. The researchers found that ensembling an MT model with an LLM can produce better translations than ensembling two stronger MT models.
The method incorporates techniques from LLM prompting, such as in-context learning and translation context, to further improve the translation quality. The researchers also explore the use of cross-modal and cross-lingual capabilities of LLMs to enhance the translation process.
Critical Analysis
The paper presents a promising approach for boosting the translation capabilities of MT models by ensembling them with LLMs. However, the researchers acknowledge some caveats and areas for further research.
One potential limitation is that the experiments were conducted on a limited set of language pairs and data amounts. It would be valuable to explore the method's performance across a wider range of language combinations and data regimes, including low-resource settings.
Additionally, the paper does not provide a detailed analysis of the specific translation errors or quality improvements introduced by the LLM-based ensembling. Further investigation into the types of errors the method can address and the underlying reasons for the performance gains would be beneficial.
The researchers also note that the computational and memory requirements of the ensembling approach may be a practical consideration, and future work could explore ways to optimize the efficiency of the method.
Conclusion
This paper introduces a novel paradigm for boosting the translation capabilities of machine translation models by ensembling them with large language models. The key finding is that even a slightly weaker LLM can enhance the performance of an MT model, and that this ensembling approach can outperform the combination of two stronger MT models.
The method incorporates advanced LLM prompting techniques to further improve translation quality. While the paper presents promising results, there are opportunities for further research to explore the method's performance across a wider range of languages and data regimes, as well as to provide a deeper analysis of the specific translation improvements achieved.
Overall, this work highlights the potential of leveraging large language models to enhance machine translation systems, opening up new avenues for improving the quality and accessibility of multilingual communication.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!GenTranslate: Large Language Models are Generative Multilingual Speech and Machine Translators
Yuchen Hu, Chen Chen, Chao-Han Huck Yang, Ruizhe Li, Dong Zhang, Zhehuai Chen, Eng Siong Chng
0
0
Recent advances in large language models (LLMs) have stepped forward the development of multilingual speech and machine translation by its reduced representation errors and incorporated external knowledge. However, both translation tasks typically utilize beam search decoding and top-1 hypothesis selection for inference. These techniques struggle to fully exploit the rich information in the diverse N-best hypotheses, making them less optimal for translation tasks that require a single, high-quality output sequence. In this paper, we propose a new generative paradigm for translation tasks, namely GenTranslate, which builds upon LLMs to generate better results from the diverse translation versions in N-best list. Leveraging the rich linguistic knowledge and strong reasoning abilities of LLMs, our new paradigm can integrate the rich information in N-best candidates to generate a higher-quality translation result. Furthermore, to support LLM finetuning, we build and release a HypoTranslate dataset that contains over 592K hypotheses-translation pairs in 11 languages. Experiments on various speech and machine translation benchmarks (e.g., FLEURS, CoVoST-2, WMT) demonstrate that our GenTranslate significantly outperforms the state-of-the-art model.
5/17/2024

A Novel Paradigm Boosting Translation Capabilities of Large Language Models
Jiaxin Guo, Hao Yang, Zongyao Li, Daimeng Wei, Hengchao Shang, Xiaoyu Chen
0
0
This paper presents a study on strategies to enhance the translation capabilities of large language models (LLMs) in the context of machine translation (MT) tasks. The paper proposes a novel paradigm consisting of three stages: Secondary Pre-training using Extensive Monolingual Data, Continual Pre-training with Interlinear Text Format Documents, and Leveraging Source-Language Consistent Instruction for Supervised Fine-Tuning. Previous research on LLMs focused on various strategies for supervised fine-tuning (SFT), but their effectiveness has been limited. While traditional machine translation approaches rely on vast amounts of parallel bilingual data, our paradigm highlights the importance of using smaller sets of high-quality bilingual data. We argue that the focus should be on augmenting LLMs' cross-lingual alignment abilities during pre-training rather than solely relying on extensive bilingual data during SFT. Experimental results conducted using the Llama2 model, particularly on Chinese-Llama2 after monolingual augmentation, demonstrate the improved translation capabilities of LLMs. A significant contribution of our approach lies in Stage2: Continual Pre-training with Interlinear Text Format Documents, which requires less than 1B training data, making our method highly efficient. Additionally, in Stage3, we observed that setting instructions consistent with the source language benefits the supervised fine-tuning process. Experimental results demonstrate that our approach surpasses previous work and achieves superior performance compared to models such as NLLB-54B and GPT3.5-text-davinci-003, despite having a significantly smaller parameter count of only 7B or 13B. This achievement establishes our method as a pioneering strategy in the field of machine translation.
4/16/2024
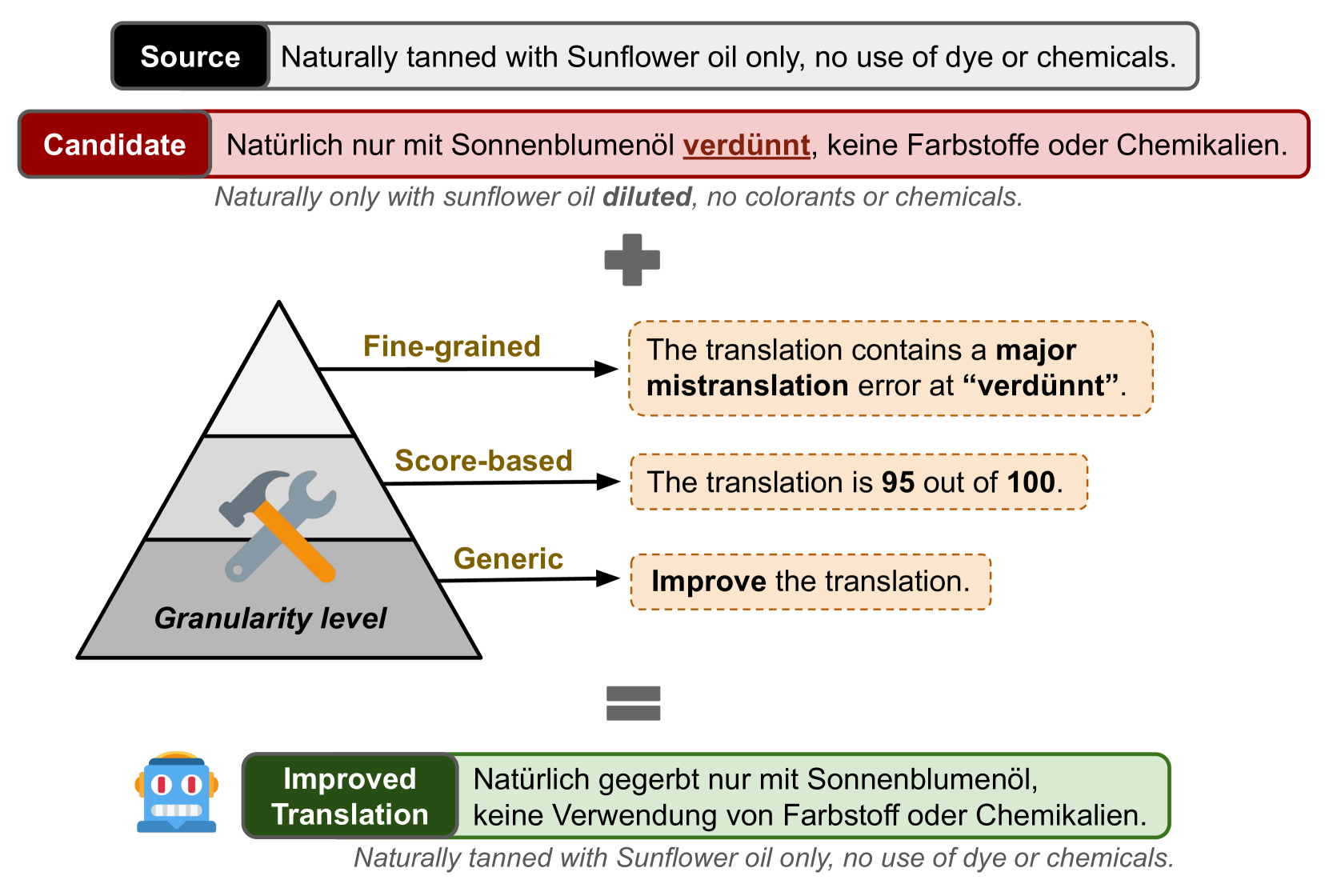
Guiding Large Language Models to Post-Edit Machine Translation with Error Annotations
Dayeon Ki, Marine Carpuat
0
0
Machine Translation (MT) remains one of the last NLP tasks where large language models (LLMs) have not yet replaced dedicated supervised systems. This work exploits the complementary strengths of LLMs and supervised MT by guiding LLMs to automatically post-edit MT with external feedback on its quality, derived from Multidimensional Quality Metric (MQM) annotations. Working with LLaMA-2 models, we consider prompting strategies varying the nature of feedback provided and then fine-tune the LLM to improve its ability to exploit the provided guidance. Through experiments on Chinese-English, English-German, and English-Russian MQM data, we demonstrate that prompting LLMs to post-edit MT improves TER, BLEU and COMET scores, although the benefits of fine-grained feedback are not clear. Fine-tuning helps integrate fine-grained feedback more effectively and further improves translation quality based on both automatic and human evaluation.
4/12/2024
💬
Large Language Models for Expansion of Spoken Language Understanding Systems to New Languages
Jakub Hoscilowicz, Pawel Pawlowski, Marcin Skorupa, Marcin Sowa'nski, Artur Janicki
0
0
Spoken Language Understanding (SLU) models are a core component of voice assistants (VA), such as Alexa, Bixby, and Google Assistant. In this paper, we introduce a pipeline designed to extend SLU systems to new languages, utilizing Large Language Models (LLMs) that we fine-tune for machine translation of slot-annotated SLU training data. Our approach improved on the MultiATIS++ benchmark, a primary multi-language SLU dataset, in the cloud scenario using an mBERT model. Specifically, we saw an improvement in the Overall Accuracy metric: from 53% to 62.18%, compared to the existing state-of-the-art method, Fine and Coarse-grained Multi-Task Learning Framework (FC-MTLF). In the on-device scenario (tiny and not pretrained SLU), our method improved the Overall Accuracy from 5.31% to 22.06% over the baseline Global-Local Contrastive Learning Framework (GL-CLeF) method. Contrary to both FC-MTLF and GL-CLeF, our LLM-based machine translation does not require changes in the production architecture of SLU. Additionally, our pipeline is slot-type independent: it does not require any slot definitions or examples.
4/4/2024