Correlation-Guided Query-Dependency Calibration for Video Temporal Grounding

0
↗️
Sign in to get full access
Overview
- Temporal grounding aims to identify specific moments or highlights from a video that correspond to textual descriptions.
- Typical approaches treat all video clips equally during encoding, regardless of their semantic relevance to the text query.
- The paper proposes Correlation-Guided DEtection TRansformer (CG-DETR), which explores providing clues for query-associated video clips within the cross-modal attention.
Plain English Explanation
The goal of temporal grounding is to match specific moments or highlights in a video with textual descriptions of those moments. For example, if a video shows someone cooking a meal, the system should be able to identify the parts of the video that correspond to steps like "chopping the vegetables" or "stirring the pot."
Existing approaches to this problem have treated all the video clips equally, regardless of how relevant they are to the text query. CG-DETR, the new method proposed in this paper, tries to focus more on the video clips that are most relevant to the text.
It does this by using "dummy tokens" - essentially placeholders - that are conditioned on the text query. These dummy tokens take up some of the attention, preventing irrelevant video clips from being represented by the text. The system also learns the correlation between individual words in the text and the video clips, to better guide the cross-attention between the two.
Finally, CG-DETR uses the specific characteristics of each moment in the video, combined with the overall context, to identify the most important or "salient" parts of the video that match the text.
Technical Explanation
The key technical components of CG-DETR are:
-
Adaptive Cross-Attention with Dummy Tokens: Dummy tokens conditioned on the text query take portions of the attention weights, preventing irrelevant video clips from being represented by the text.
-
Clip-Word Correlation Guidance: The system learns a joint embedding space for high-level concepts (moments and sentences) and infers the fine-grained correlation between video clips and words to better guide the cross-attention.
-
Moment-Adaptive Saliency Detector: The method exploits the degrees of text engagement in each video clip to precisely measure the "highlightness" or salience of each clip, combining moment-specific characteristics and overall video context.
By focusing the attention on the most relevant video clips and modeling the detailed correlations between the text and video, CG-DETR is able to achieve state-of-the-art results on various temporal grounding benchmarks.
Critical Analysis
The paper presents a well-designed and effective approach to the temporal grounding problem. A few potential areas for further consideration:
-
The method relies on learning the clip-word correlations, which may be challenging for longer or more complex text descriptions. Exploring alternative ways to capture these relationships could be worthwhile.
-
The experiments are conducted on standard benchmarks, but real-world applications may involve more diverse and noisy video-text pairs. Evaluating the robustness of CG-DETR in such settings would be valuable.
-
While the saliency detection component is a key contribution, the paper does not deeply analyze its performance or failure cases. Understanding the limitations of this module could inspire future improvements.
Overall, CG-DETR represents a significant advance in temporal grounding, and the technical insights could inspire further research in multimodal alignment and video understanding.
Conclusion
The Correlation-Guided DEtection TRansformer (CG-DETR) proposed in this paper is a novel approach to the task of temporal grounding, which aims to match textual descriptions to specific moments in a video. By focusing the cross-modal attention on the most relevant video clips and modeling the fine-grained correlations between text and video, CG-DETR achieves state-of-the-art results on benchmark datasets.
The key technical contributions, including the use of dummy tokens, clip-word correlation guidance, and moment-adaptive saliency detection, demonstrate how carefully designed multimodal architectures can significantly improve the performance of temporal grounding systems. As video content continues to grow in importance, advancements like CG-DETR will be crucial for unlocking the full potential of video-language understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
↗️
0
Correlation-Guided Query-Dependency Calibration for Video Temporal Grounding
WonJun Moon, Sangeek Hyun, SuBeen Lee, Jae-Pil Heo
Temporal Grounding is to identify specific moments or highlights from a video corresponding to textual descriptions. Typical approaches in temporal grounding treat all video clips equally during the encoding process regardless of their semantic relevance with the text query. Therefore, we propose Correlation-Guided DEtection TRansformer (CG-DETR), exploring to provide clues for query-associated video clips within the cross-modal attention. First, we design an adaptive cross-attention with dummy tokens. Dummy tokens conditioned by text query take portions of the attention weights, preventing irrelevant video clips from being represented by the text query. Yet, not all words equally inherit the text query's correlation to video clips. Thus, we further guide the cross-attention map by inferring the fine-grained correlation between video clips and words. We enable this by learning a joint embedding space for high-level concepts, i.e., moment and sentence level, and inferring the clip-word correlation. Lastly, we exploit the moment-specific characteristics and combine them with the context of each video to form a moment-adaptive saliency detector. By exploiting the degrees of text engagement in each video clip, it precisely measures the highlightness of each clip. CG-DETR achieves state-of-the-art results on various benchmarks for temporal grounding. Codes are available at https://github.com/wjun0830/CGDETR.
Read more7/8/2024
0
Video sentence grounding with temporally global textual knowledge
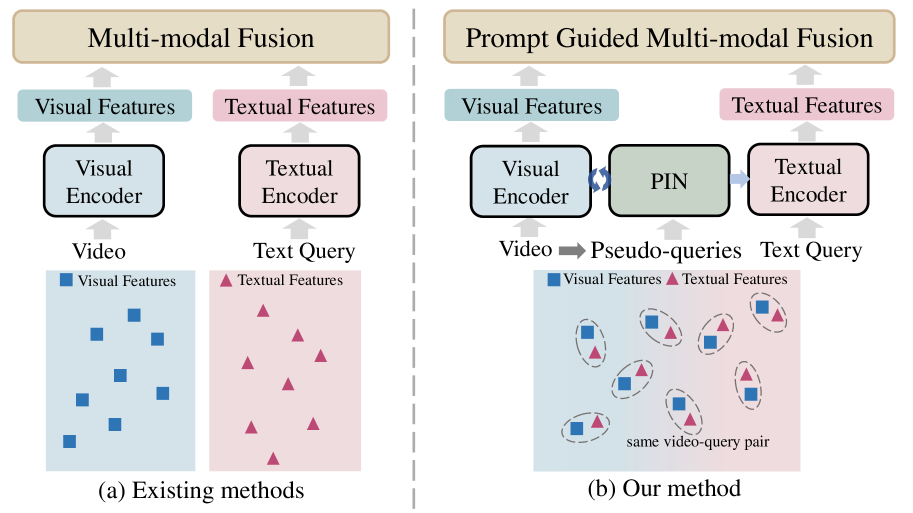
Cai Chen, Runzhong Zhang, Jianjun Gao, Kejun Wu, Kim-Hui Yap, Yi Wang
Temporal sentence grounding involves the retrieval of a video moment with a natural language query. Many existing works directly incorporate the given video and temporally localized query for temporal grounding, overlooking the inherent domain gap between different modalities. In this paper, we utilize pseudo-query features containing extensive temporally global textual knowledge sourced from the same video-query pair, to enhance the bridging of domain gaps and attain a heightened level of similarity between multi-modal features. Specifically, we propose a Pseudo-query Intermediary Network (PIN) to achieve an improved alignment of visual and comprehensive pseudo-query features within the feature space through contrastive learning. Subsequently, we utilize learnable prompts to encapsulate the knowledge of pseudo-queries, propagating them into the textual encoder and multi-modal fusion module, further enhancing the feature alignment between visual and language for better temporal grounding. Extensive experiments conducted on the Charades-STA and ActivityNet-Captions datasets demonstrate the effectiveness of our method.
Read more6/4/2024
0
Diversifying Query: Region-Guided Transformer for Temporal Sentence Grounding
Xiaolong Sun, Liushuai Shi, Le Wang, Sanping Zhou, Kun Xia, Yabing Wang, Gang Hua
Temporal sentence grounding is a challenging task that aims to localize the moment spans relevant to a language description. Although recent DETR-based models have achieved notable progress by leveraging multiple learnable moment queries, they suffer from overlapped and redundant proposals, leading to inaccurate predictions. We attribute this limitation to the lack of task-related guidance for the learnable queries to serve a specific mode. Furthermore, the complex solution space generated by variable and open-vocabulary language descriptions exacerbates the optimization difficulty, making it harder for learnable queries to distinguish each other adaptively. To tackle this limitation, we present a Region-Guided TRansformer (RGTR) for temporal sentence grounding, which diversifies moment queries to eliminate overlapped and redundant predictions. Instead of using learnable queries, RGTR adopts a set of anchor pairs as moment queries to introduce explicit regional guidance. Each anchor pair takes charge of moment prediction for a specific temporal region, which reduces the optimization difficulty and ensures the diversity of the final predictions. In addition, we design an IoU-aware scoring head to improve proposal quality. Extensive experiments demonstrate the effectiveness of RGTR, outperforming state-of-the-art methods on QVHighlights, Charades-STA and TACoS datasets.
Read more6/4/2024

0
Beyond Uncertainty: Evidential Deep Learning for Robust Video Temporal Grounding
Kaijing Ma, Haojian Huang, Jin Chen, Haodong Chen, Pengliang Ji, Xianghao Zang, Han Fang, Chao Ban, Hao Sun, Mulin Chen, Xuelong Li
Existing Video Temporal Grounding (VTG) models excel in accuracy but often overlook open-world challenges posed by open-vocabulary queries and untrimmed videos. This leads to unreliable predictions for noisy, corrupted, and out-of-distribution data. Adapting VTG models to dynamically estimate uncertainties based on user input can address this issue. To this end, we introduce SRAM, a robust network module that benefits from a two-stage cross-modal alignment task. More importantly, it integrates Deep Evidential Regression (DER) to explicitly and thoroughly quantify uncertainty during training, thus allowing the model to say I do not know in scenarios beyond its handling capacity. However, the direct application of traditional DER theory and its regularizer reveals structural flaws, leading to unintended constraints in VTG tasks. In response, we develop a simple yet effective Geom-regularizer that enhances the uncertainty learning framework from the ground up. To the best of our knowledge, this marks the first successful attempt of DER in VTG. Our extensive quantitative and qualitative results affirm the effectiveness, robustness, and interpretability of our modules and the uncertainty learning paradigm in VTG tasks. The code will be made available.
Read more8/30/2024