Diversifying Query: Region-Guided Transformer for Temporal Sentence Grounding

0
Sign in to get full access
Overview
- This paper introduces a novel transformer-based model called "Diversifying Query: Region-Guided Transformer for Temporal Sentence Grounding" (DQR-TSG) that aims to improve the performance of temporal sentence grounding tasks.
- Temporal sentence grounding involves aligning textual descriptions with the relevant temporal regions in a video.
- The DQR-TSG model leverages region-guided attention to capture both global and local temporal information, leading to better alignment between language and video.
- The authors evaluate their model on several benchmark datasets and demonstrate state-of-the-art results, outperforming previous approaches.
Plain English Explanation
The paper presents a new AI model that can better understand the relationship between text and video over time. Imagine you have a video of someone cooking a meal, and you want to find the specific moments in the video that match a description like "the chef adds the vegetables to the pan." Existing models struggle with this task, as they have trouble grasping the full context and timing of events.
The researchers developed a transformer-based model called DQR-TSG that uses "region-guided attention" to better capture both the global and local temporal information in the video. This allows the model to more accurately align the text description with the relevant moments in the video.
The model was tested on several standard benchmarks for this task, and it outperformed previous state-of-the-art approaches. This suggests the DQR-TSG model is a significant step forward in the field of temporal sentence grounding, which has applications in areas like medical report grounding and spatial-temporal reasoning.
Technical Explanation
The key innovation of the DQR-TSG model is its use of region-guided attention, which allows it to better capture both global and local temporal information when aligning text and video. Traditional approaches often struggle to balance these two types of information, leading to suboptimal performance.
The DQR-TSG model takes as input a video and a textual description, and outputs the relevant temporal regions in the video that match the description. The model consists of a video encoder, a text encoder, and a cross-modal attention module that aligns the two modalities.
The video encoder first divides the video into multiple temporal regions, and the text encoder converts the input text into a sequence of token embeddings. The cross-modal attention module then dynamically attends to the relevant video regions based on the input text, allowing the model to focus on the most important temporal information.
The authors evaluate their model on several benchmark datasets, including ActivityNet Captions, TACoS, and DiDeMo. Their experiments demonstrate state-of-the-art performance, outperforming previous approaches that rely on more traditional techniques.
Critical Analysis
The authors acknowledge several limitations of their work, such as the model's reliance on pre-trained video and text encoders, which may limit its scalability and flexibility. Additionally, the model's performance may be sensitive to the quality and diversity of the training data, an issue that the authors did not explore in depth.
One potential concern is the model's ability to generalize to more complex or ambiguous language, as the paper primarily evaluates the model on relatively straightforward textual descriptions. It would be interesting to see how the DQR-TSG model performs on more challenging language inputs, such as those involving temporal reasoning or spatial-temporal grounding.
Overall, the DQR-TSG model represents a promising advancement in the field of temporal sentence grounding, but further research is needed to address the limitations and explore its broader applicability.
Conclusion
The "Diversifying Query: Region-Guided Transformer for Temporal Sentence Grounding" paper presents a novel transformer-based model that significantly improves the performance of temporal sentence grounding tasks. By leveraging region-guided attention, the DQR-TSG model is able to better capture both global and local temporal information, leading to more accurate alignment between language and video.
The authors' evaluation on several benchmark datasets demonstrates the model's state-of-the-art performance, suggesting it is a valuable contribution to the field. While the model has some limitations, the core ideas behind the region-guided attention mechanism could have broader applications in video-language understanding, medical report grounding, and other areas that require aligning textual descriptions with corresponding visual or temporal information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Diversifying Query: Region-Guided Transformer for Temporal Sentence Grounding
Xiaolong Sun, Liushuai Shi, Le Wang, Sanping Zhou, Kun Xia, Yabing Wang, Gang Hua
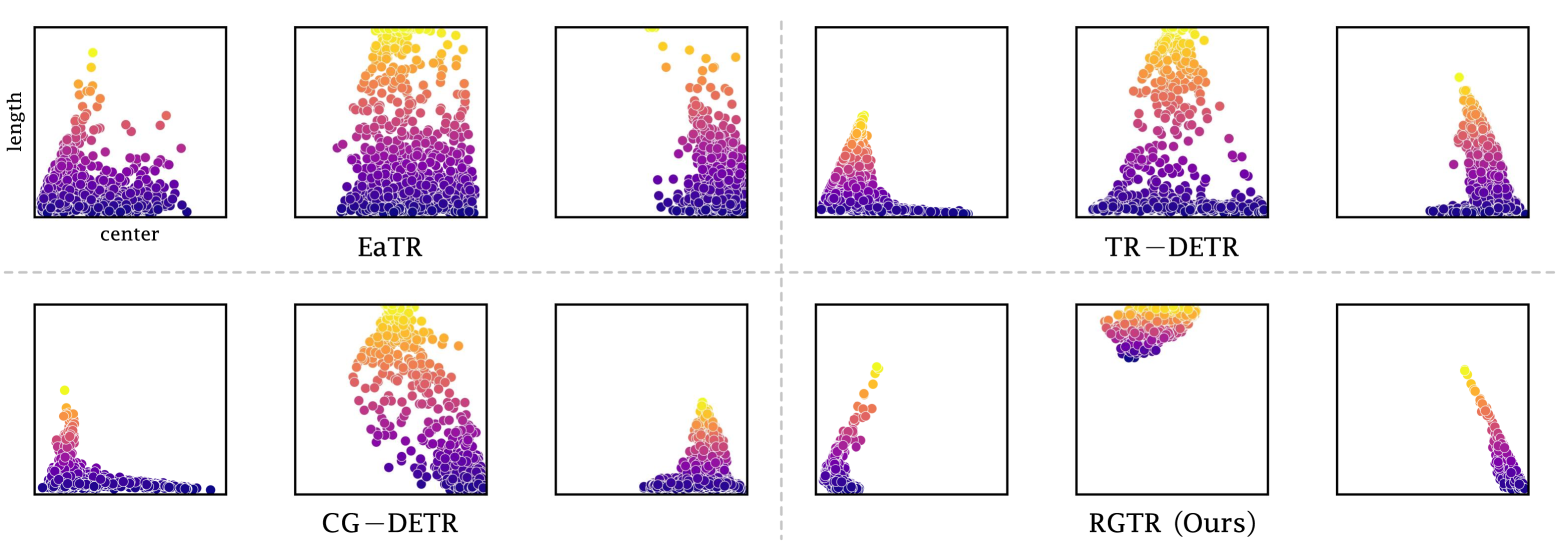
Temporal sentence grounding is a challenging task that aims to localize the moment spans relevant to a language description. Although recent DETR-based models have achieved notable progress by leveraging multiple learnable moment queries, they suffer from overlapped and redundant proposals, leading to inaccurate predictions. We attribute this limitation to the lack of task-related guidance for the learnable queries to serve a specific mode. Furthermore, the complex solution space generated by variable and open-vocabulary language descriptions exacerbates the optimization difficulty, making it harder for learnable queries to distinguish each other adaptively. To tackle this limitation, we present a Region-Guided TRansformer (RGTR) for temporal sentence grounding, which diversifies moment queries to eliminate overlapped and redundant predictions. Instead of using learnable queries, RGTR adopts a set of anchor pairs as moment queries to introduce explicit regional guidance. Each anchor pair takes charge of moment prediction for a specific temporal region, which reduces the optimization difficulty and ensures the diversity of the final predictions. In addition, we design an IoU-aware scoring head to improve proposal quality. Extensive experiments demonstrate the effectiveness of RGTR, outperforming state-of-the-art methods on QVHighlights, Charades-STA and TACoS datasets.
Read more6/4/2024
↗️
0
Correlation-Guided Query-Dependency Calibration for Video Temporal Grounding
WonJun Moon, Sangeek Hyun, SuBeen Lee, Jae-Pil Heo
Temporal Grounding is to identify specific moments or highlights from a video corresponding to textual descriptions. Typical approaches in temporal grounding treat all video clips equally during the encoding process regardless of their semantic relevance with the text query. Therefore, we propose Correlation-Guided DEtection TRansformer (CG-DETR), exploring to provide clues for query-associated video clips within the cross-modal attention. First, we design an adaptive cross-attention with dummy tokens. Dummy tokens conditioned by text query take portions of the attention weights, preventing irrelevant video clips from being represented by the text query. Yet, not all words equally inherit the text query's correlation to video clips. Thus, we further guide the cross-attention map by inferring the fine-grained correlation between video clips and words. We enable this by learning a joint embedding space for high-level concepts, i.e., moment and sentence level, and inferring the clip-word correlation. Lastly, we exploit the moment-specific characteristics and combine them with the context of each video to form a moment-adaptive saliency detector. By exploiting the degrees of text engagement in each video clip, it precisely measures the highlightness of each clip. CG-DETR achieves state-of-the-art results on various benchmarks for temporal grounding. Codes are available at https://github.com/wjun0830/CGDETR.
Read more7/8/2024
0
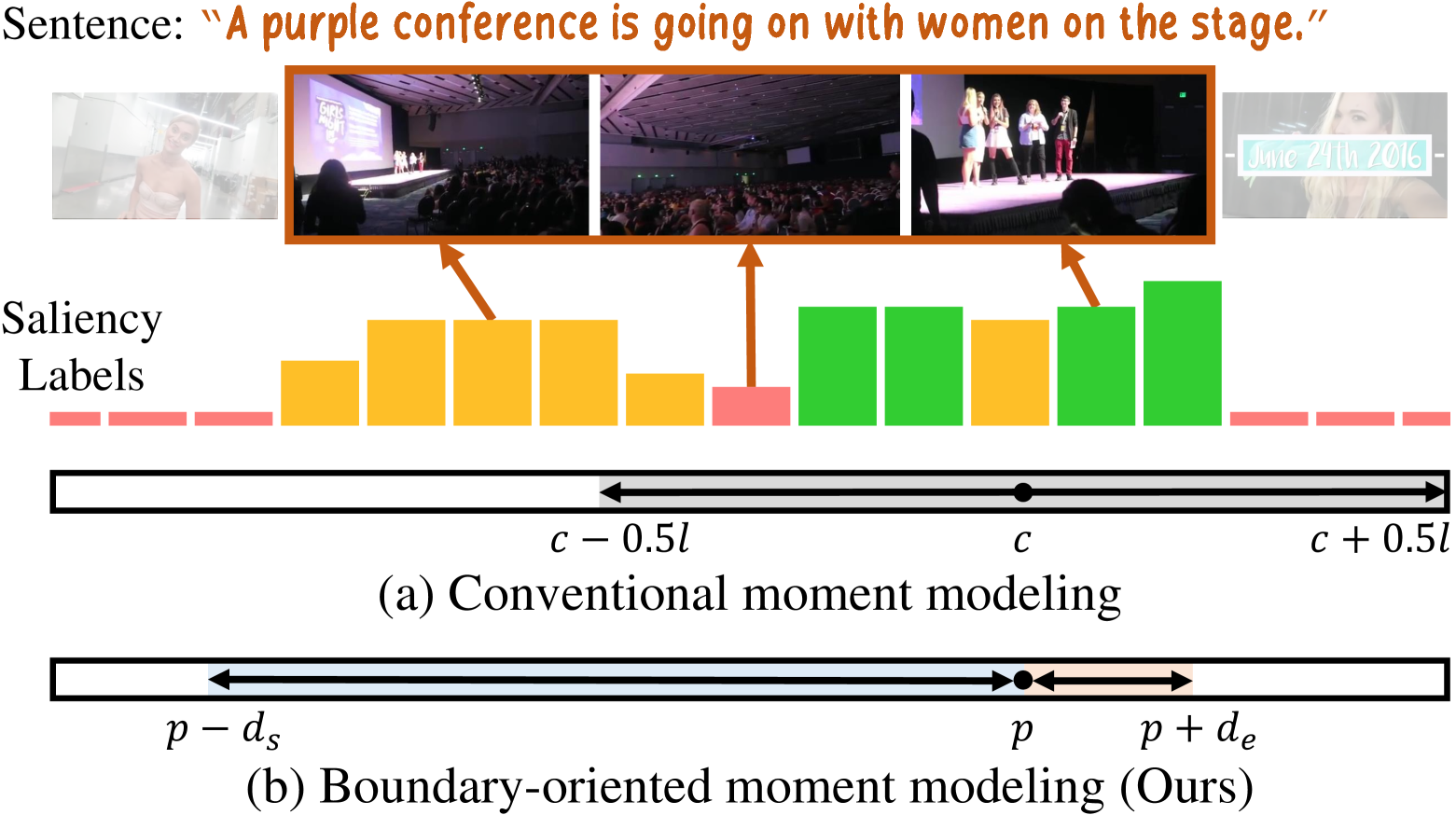
BAM-DETR: Boundary-Aligned Moment Detection Transformer for Temporal Sentence Grounding in Videos
Pilhyeon Lee, Hyeran Byun
Temporal sentence grounding aims to localize moments relevant to a language description. Recently, DETR-like approaches achieved notable progress by predicting the center and length of a target moment. However, they suffer from the issue of center misalignment raised by the inherent ambiguity of moment centers, leading to inaccurate predictions. To remedy this problem, we propose a novel boundary-oriented moment formulation. In our paradigm, the model no longer needs to find the precise center but instead suffices to predict any anchor point within the interval, from which the boundaries are directly estimated. Based on this idea, we design a boundary-aligned moment detection transformer, equipped with a dual-pathway decoding process. Specifically, it refines the anchor and boundaries within parallel pathways using global and boundary-focused attention, respectively. This separate design allows the model to focus on desirable regions, enabling precise refinement of moment predictions. Further, we propose a quality-based ranking method, ensuring that proposals with high localization qualities are prioritized over incomplete ones. Experiments on three benchmarks validate the effectiveness of the proposed methods. The code is available at https://github.com/Pilhyeon/BAM-DETR.
Read more7/19/2024
0
Video sentence grounding with temporally global textual knowledge
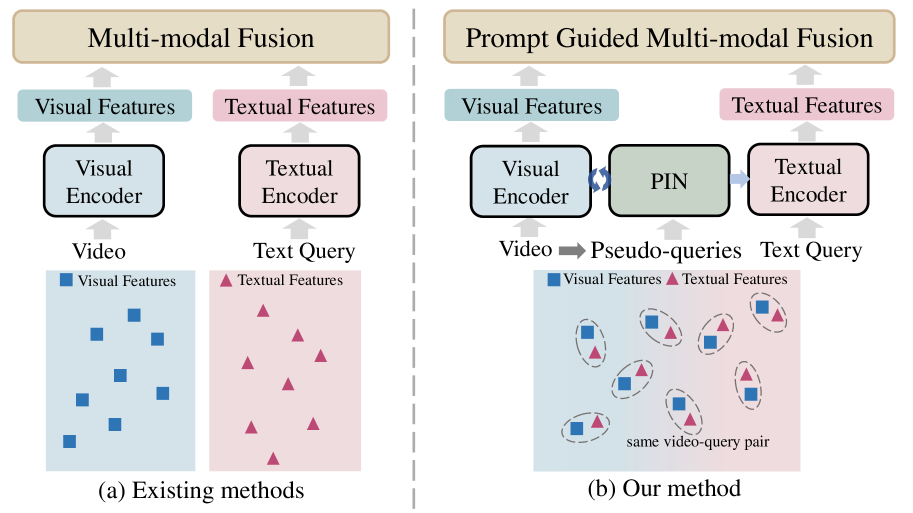
Cai Chen, Runzhong Zhang, Jianjun Gao, Kejun Wu, Kim-Hui Yap, Yi Wang
Temporal sentence grounding involves the retrieval of a video moment with a natural language query. Many existing works directly incorporate the given video and temporally localized query for temporal grounding, overlooking the inherent domain gap between different modalities. In this paper, we utilize pseudo-query features containing extensive temporally global textual knowledge sourced from the same video-query pair, to enhance the bridging of domain gaps and attain a heightened level of similarity between multi-modal features. Specifically, we propose a Pseudo-query Intermediary Network (PIN) to achieve an improved alignment of visual and comprehensive pseudo-query features within the feature space through contrastive learning. Subsequently, we utilize learnable prompts to encapsulate the knowledge of pseudo-queries, propagating them into the textual encoder and multi-modal fusion module, further enhancing the feature alignment between visual and language for better temporal grounding. Extensive experiments conducted on the Charades-STA and ActivityNet-Captions datasets demonstrate the effectiveness of our method.
Read more6/4/2024