A Correlation- and Mean-Aware Loss Function and Benchmarking Framework to Improve GAN-based Tabular Data Synthesis
2405.16971
0
0
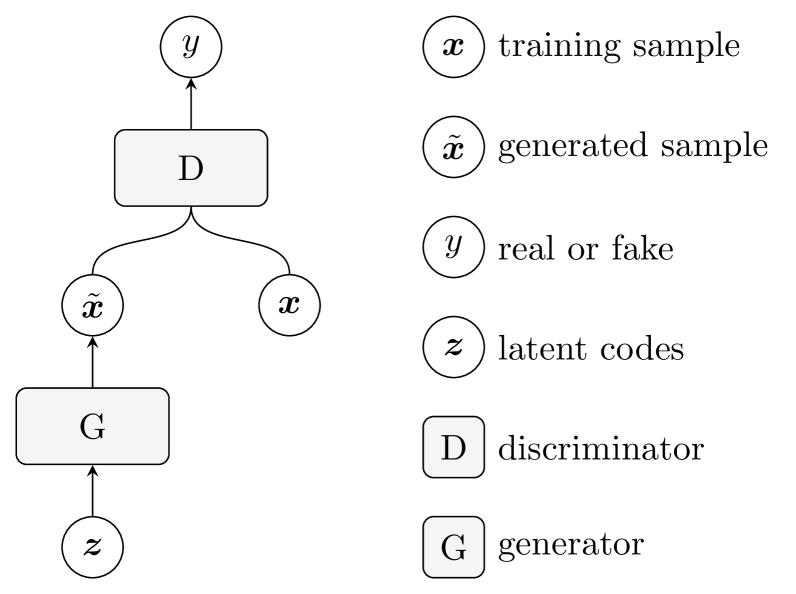
Abstract
Advancements in science rely on data sharing. In medicine, where personal data are often involved, synthetic tabular data generated by generative adversarial networks (GANs) offer a promising avenue. However, existing GANs struggle to capture the complexities of real-world tabular data, which often contain a mix of continuous and categorical variables with potential imbalances and dependencies. We propose a novel correlation- and mean-aware loss function designed to address these challenges as a regularizer for GANs. To ensure a rigorous evaluation, we establish a comprehensive benchmarking framework using ten real-world datasets and eight established tabular GAN baselines. The proposed loss function demonstrates statistically significant improvements over existing methods in capturing the true data distribution, significantly enhancing the quality of synthetic data generated with GANs. The benchmarking framework shows that the enhanced synthetic data quality leads to improved performance in downstream machine learning (ML) tasks, ultimately paving the way for easier data sharing.
Create account to get full access
Overview
- This paper proposes a new loss function and benchmarking framework to improve the performance of Generative Adversarial Networks (GANs) in synthesizing tabular data.
- The authors identify key limitations of existing GAN-based approaches for tabular data synthesis, such as their inability to capture important statistical properties like correlations and means.
- The proposed method, called Correlation- and Mean-Aware GAN (CMAGAN), addresses these issues by incorporating correlation and mean-awareness into the GAN training process.
- The paper also introduces a new benchmark suite to comprehensively evaluate the quality of synthetic tabular data generated by different methods.
Plain English Explanation
The paper focuses on improving the way that Generative Adversarial Networks (GANs) can be used to create synthetic tabular data. Tabular data refers to data that is organized in a table-like format, with rows and columns.
Current GAN-based approaches for generating synthetic tabular data have some limitations. They may not be able to accurately capture important statistical properties of the original data, such as the correlations between different columns or the average (mean) values of the columns.
The researchers propose a new GAN-based method called Correlation- and Mean-Aware GAN (CMAGAN) that addresses these issues. By incorporating correlation and mean-awareness into the GAN training process, the model can generate synthetic tabular data that better reflects the statistical characteristics of the original data.
The paper also introduces a new benchmark suite - a set of tests and metrics - to evaluate how well different methods for generating synthetic tabular data are able to capture the important properties of the original data. This benchmark can help researchers and practitioners compare the performance of various tabular data synthesis approaches.
Technical Explanation
The key technical contributions of this paper are:
-
Correlation- and Mean-Aware Loss Function: The authors propose a new loss function for training GANs to synthesize tabular data. This loss function incorporates measures of the correlation and mean structure of the data, in addition to the standard GAN loss. This helps the generator model capture these important statistical properties of the original data.
-
Benchmarking Framework: The paper introduces a comprehensive benchmarking framework to evaluate the quality of synthetic tabular data generated by different methods. This framework includes a suite of tests and metrics that measure various aspects of the data, such as distribution similarity, correlation structure preservation, and mean preservation.
-
Empirical Evaluation: The authors conduct extensive experiments on several real-world tabular datasets to compare the performance of their proposed Correlation- and Mean-Aware GAN (CMAGAN) approach against state-of-the-art GAN-based and non-GAN-based tabular data synthesis methods, such as Multi-Objective Evolutionary GAN, Improved Tabular Data Generator, and Supervised Generative Optimization. Their results demonstrate the superiority of CMAGAN in terms of preserving the correlation and mean structure of the original data.
Critical Analysis
The paper provides a comprehensive and well-designed solution to address the limitations of existing GAN-based approaches for tabular data synthesis. The proposed Correlation- and Mean-Aware GAN (CMAGAN) method and the benchmarking framework are valuable contributions to the field.
One potential limitation of the research is that it focuses solely on the correlation and mean structure of the data, while other important statistical properties, such as higher-order moments or the presence of outliers, are not explicitly considered. It would be interesting to see if the proposed approach can be extended to incorporate these additional aspects of the data.
Additionally, the paper could have provided more discussion on the practical implications and real-world applications of the proposed method. For example, how might the ability to generate high-quality synthetic tabular data impact industries or research areas that rely on such data?
Overall, the paper presents a well-designed and rigorous study that advances the state-of-the-art in GAN-based tabular data synthesis. The insights and tools provided in this work can be valuable for researchers and practitioners working on data generation and augmentation tasks.
Conclusion
This paper introduces a novel Correlation- and Mean-Aware GAN (CMAGAN) approach to improve the performance of GAN-based tabular data synthesis. By incorporating correlation and mean-awareness into the GAN training process, the proposed method is able to generate synthetic tabular data that better preserves the statistical properties of the original data.
The paper also presents a comprehensive benchmarking framework to evaluate the quality of synthetic tabular data, which can be useful for comparing the performance of different data synthesis methods. The empirical results demonstrate the superiority of CMAGAN over existing state-of-the-art approaches.
The insights and tools provided in this work can have significant implications for a wide range of applications that rely on synthetic tabular data, such as data augmentation, privacy-preserving data sharing, and data simulation. The proposed methods can help researchers and practitioners generate high-quality synthetic data that more accurately captures the statistical characteristics of the original data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
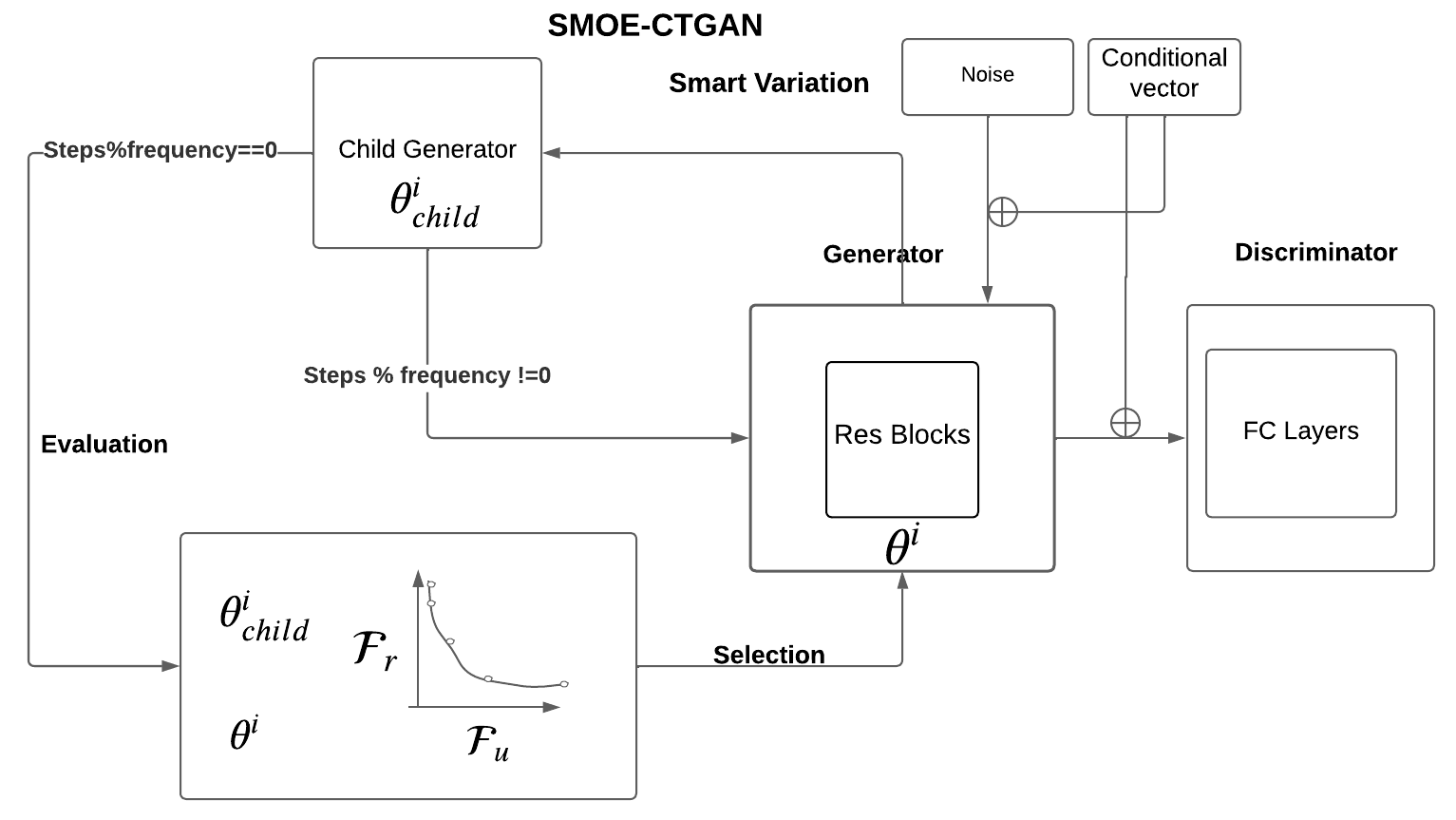
Multi-objective evolutionary GAN for tabular data synthesis
Nian Ran, Bahrul Ilmi Nasution, Claire Little, Richard Allmendinger, Mark Elliot
0
0
Synthetic data has a key role to play in data sharing by statistical agencies and other generators of statistical data products. Generative Adversarial Networks (GANs), typically applied to image synthesis, are also a promising method for tabular data synthesis. However, there are unique challenges in tabular data compared to images, eg tabular data may contain both continuous and discrete variables and conditional sampling, and, critically, the data should possess high utility and low disclosure risk (the risk of re-identifying a population unit or learning something new about them), providing an opportunity for multi-objective (MO) optimization. Inspired by MO GANs for images, this paper proposes a smart MO evolutionary conditional tabular GAN (SMOE-CTGAN). This approach models conditional synthetic data by applying conditional vectors in training, and uses concepts from MO optimisation to balance disclosure risk against utility. Our results indicate that SMOE-CTGAN is able to discover synthetic datasets with different risk and utility levels for multiple national census datasets. We also find a sweet spot in the early stage of training where a competitive utility and extremely low risk are achieved, by using an Improvement Score. The full code can be downloaded from https://github.com/HuskyNian/SMO_EGAN_pytorch.
4/17/2024
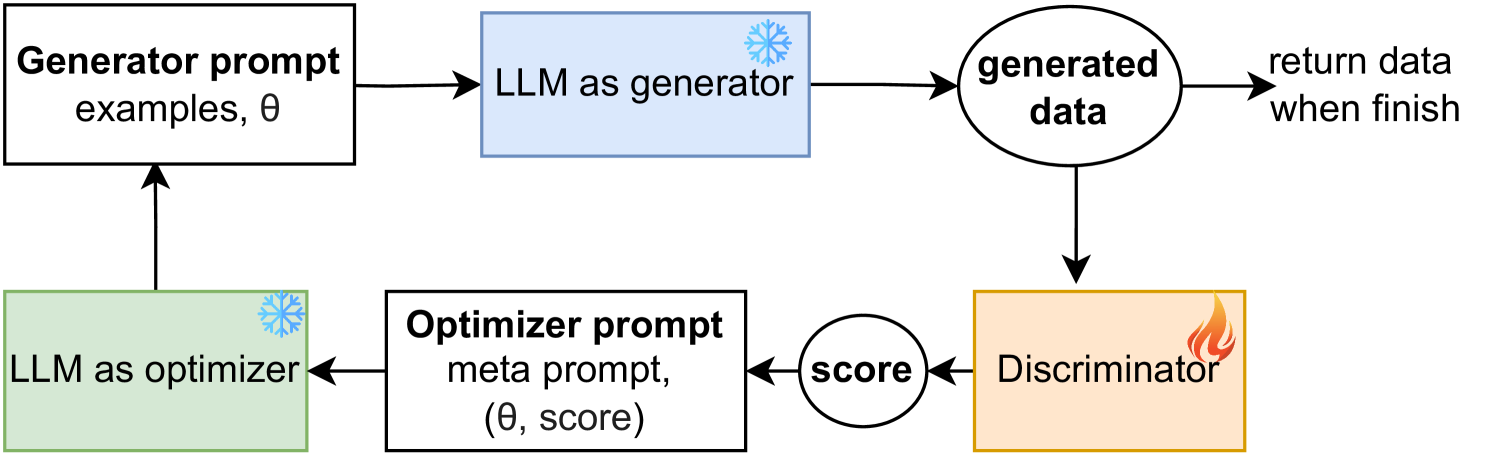
MALLM-GAN: Multi-Agent Large Language Model as Generative Adversarial Network for Synthesizing Tabular Data
Yaobin Ling, Xiaoqian Jiang, Yejin Kim
0
0
In the era of big data, access to abundant data is crucial for driving research forward. However, such data is often inaccessible due to privacy concerns or high costs, particularly in healthcare domain. Generating synthetic (tabular) data can address this, but existing models typically require substantial amounts of data to train effectively, contradicting our objective to solve data scarcity. To address this challenge, we propose a novel framework to generate synthetic tabular data, powered by large language models (LLMs) that emulates the architecture of a Generative Adversarial Network (GAN). By incorporating data generation process as contextual information and utilizing LLM as the optimizer, our approach significantly enhance the quality of synthetic data generation in common scenarios with small sample sizes. Our experimental results on public and private datasets demonstrate that our model outperforms several state-of-art models regarding generating higher quality synthetic data for downstream tasks while keeping privacy of the real data.
6/18/2024
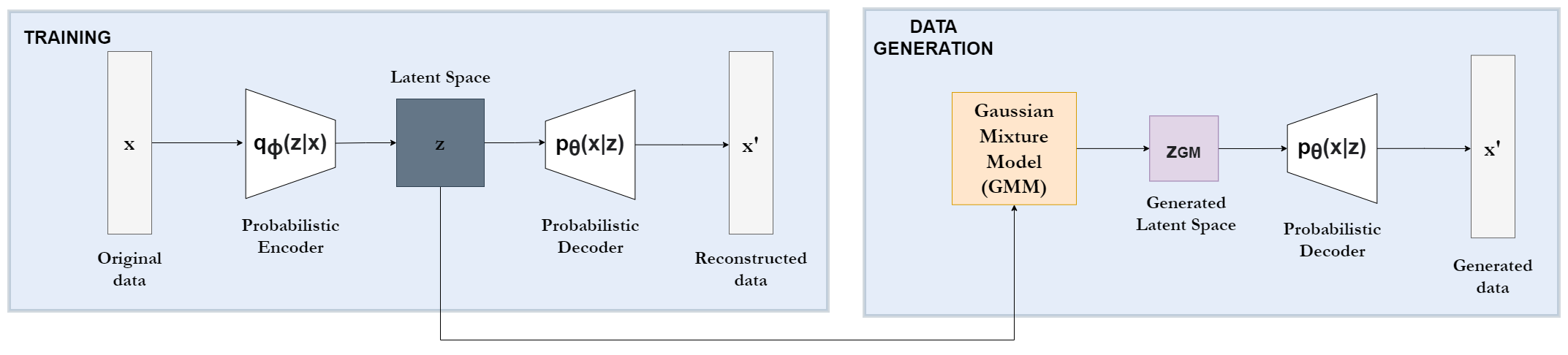
An improved tabular data generator with VAE-GMM integration
Patricia A. Apell'aniz, Juan Parras, Santiago Zazo
0
0
The rising use of machine learning in various fields requires robust methods to create synthetic tabular data. Data should preserve key characteristics while addressing data scarcity challenges. Current approaches based on Generative Adversarial Networks, such as the state-of-the-art CTGAN model, struggle with the complex structures inherent in tabular data. These data often contain both continuous and discrete features with non-Gaussian distributions. Therefore, we propose a novel Variational Autoencoder (VAE)-based model that addresses these limitations. Inspired by the TVAE model, our approach incorporates a Bayesian Gaussian Mixture model (BGM) within the VAE architecture. This avoids the limitations imposed by assuming a strictly Gaussian latent space, allowing for a more accurate representation of the underlying data distribution during data generation. Furthermore, our model offers enhanced flexibility by allowing the use of various differentiable distributions for individual features, making it possible to handle both continuous and discrete data types. We thoroughly validate our model on three real-world datasets with mixed data types, including two medically relevant ones, based on their resemblance and utility. This evaluation demonstrates significant outperformance against CTGAN and TVAE, establishing its potential as a valuable tool for generating synthetic tabular data in various domains, particularly in healthcare.
4/15/2024
👨🏫
A supervised generative optimization approach for tabular data
Shinpei Nakamura-Sakai, Fadi Hamad, Saheed Obitayo, Vamsi K. Potluru
0
0
Synthetic data generation has emerged as a crucial topic for financial institutions, driven by multiple factors, such as privacy protection and data augmentation. Many algorithms have been proposed for synthetic data generation but reaching the consensus on which method we should use for the specific data sets and use cases remains challenging. Moreover, the majority of existing approaches are ``unsupervised'' in the sense that they do not take into account the downstream task. To address these issues, this work presents a novel synthetic data generation framework. The framework integrates a supervised component tailored to the specific downstream task and employs a meta-learning approach to learn the optimal mixture distribution of existing synthetic distributions.
5/13/2024