A supervised generative optimization approach for tabular data
2309.05079
0
0
👨🏫
Abstract
Synthetic data generation has emerged as a crucial topic for financial institutions, driven by multiple factors, such as privacy protection and data augmentation. Many algorithms have been proposed for synthetic data generation but reaching the consensus on which method we should use for the specific data sets and use cases remains challenging. Moreover, the majority of existing approaches are ``unsupervised'' in the sense that they do not take into account the downstream task. To address these issues, this work presents a novel synthetic data generation framework. The framework integrates a supervised component tailored to the specific downstream task and employs a meta-learning approach to learn the optimal mixture distribution of existing synthetic distributions.
Create account to get full access
Overview
- Synthetic data generation has become crucial for financial institutions, driven by privacy protection and data augmentation needs
- Existing approaches are often "unsupervised," not tailored to specific downstream tasks
- This work presents a novel synthetic data generation framework that integrates a supervised component and uses meta-learning to learn an optimal mixture of synthetic distributions
Plain English Explanation
Synthetic data generation has become an important topic for financial institutions. This is driven by a few key factors. First, there is a need to protect the privacy of real customer data. By generating artificial data that mimics the real data, financial institutions can use this synthetic data for various purposes without compromising customer privacy. Second, synthetic data can be used to augment or expand the available data, which is helpful when the real dataset is limited.
Many different algorithms have been proposed for generating synthetic data. However, deciding which method to use for a specific dataset or business use case can be challenging. Additionally, most existing approaches are "unsupervised," meaning they do not take into account the particular task that the synthetic data will be used for downstream.
To address these issues, the researchers in this work developed a new framework for synthetic data generation. Their framework includes a "supervised" component that is tailored to the specific task the synthetic data will be used for. It also employs a meta-learning approach to learn the optimal mixture of existing synthetic data generation techniques for a given dataset and use case.
Technical Explanation
The proposed framework integrates a supervised component to ensure the generated synthetic data is well-suited for the downstream task. This is in contrast to unsupervised approaches that do not consider the end use of the data.
The framework also employs a meta-learning approach to learn the optimal combination of existing synthetic data generation techniques for a specific dataset and use case. This helps address the challenge of choosing the right synthetic data generation method for a given scenario.
The researchers evaluate their framework using a structured evaluation framework for synthetic data generation models. Their results demonstrate the effectiveness of the supervised and meta-learning components in producing high-quality synthetic data tailored to the target downstream task.
Critical Analysis
The paper provides a novel and promising approach to synthetic data generation. By incorporating a supervised component and using meta-learning, the framework aims to address key limitations of existing unsupervised methods. However, the authors acknowledge that further research is needed to fully understand the capabilities and limitations of their approach.
One potential concern is the computational complexity introduced by the meta-learning component. Depending on the size and complexity of the dataset and downstream task, the overhead of learning the optimal mixture of synthetic data generation techniques may be non-trivial.
Additionally, the paper does not delve deeply into the fairness and ethical implications of synthetic data generation. While privacy protection is mentioned as a key driver, there may be concerns around how the generated data reflects or amplifies societal biases present in the original data.
Overall, this work represents an important step forward in the field of synthetic data generation. Encouraging further research and critical analysis in this area will be essential to developing robust and responsible synthetic data solutions for financial institutions and other domains.
Conclusion
This paper presents a novel synthetic data generation framework that addresses key limitations of existing unsupervised approaches. By integrating a supervised component and employing meta-learning, the framework aims to produce synthetic data that is well-suited for specific downstream tasks.
The technical evaluation demonstrates the effectiveness of the proposed approach, but also highlights the need for further research to understand its scalability and potential ethical considerations. As synthetic data generation continues to grow in importance, frameworks like this one will play a crucial role in helping financial institutions and other organizations leverage artificial data while protecting privacy and fairness.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Group-wise Prompting for Synthetic Tabular Data Generation using Large Language Models
Jinhee Kim, Taesung Kim, Jaegul Choo
0
0
Large language models (LLMs) have demonstrated impressive in-context learning capabilities across various domains. Inspired by this, our study explores the effectiveness of LLMs in generating realistic tabular data to mitigate class imbalance. We investigate and identify key prompt design elements such as data format, class presentation, and variable mapping to optimize the generation performance. Our findings indicate that using CSV format, balancing classes, and employing unique variable mapping produces realistic and reliable data, significantly enhancing machine learning performance for minor classes in imbalanced datasets. Additionally, these approaches improve the stability and efficiency of LLM data generation. We validate our approach using six real-world datasets and a toy dataset, achieving state-of-the-art performance in classification tasks. The code is available at: https://github.com/seharanul17/synthetic-tabular-LLM
5/28/2024
Multi-objective evolutionary GAN for tabular data synthesis
Nian Ran, Bahrul Ilmi Nasution, Claire Little, Richard Allmendinger, Mark Elliot
0
0
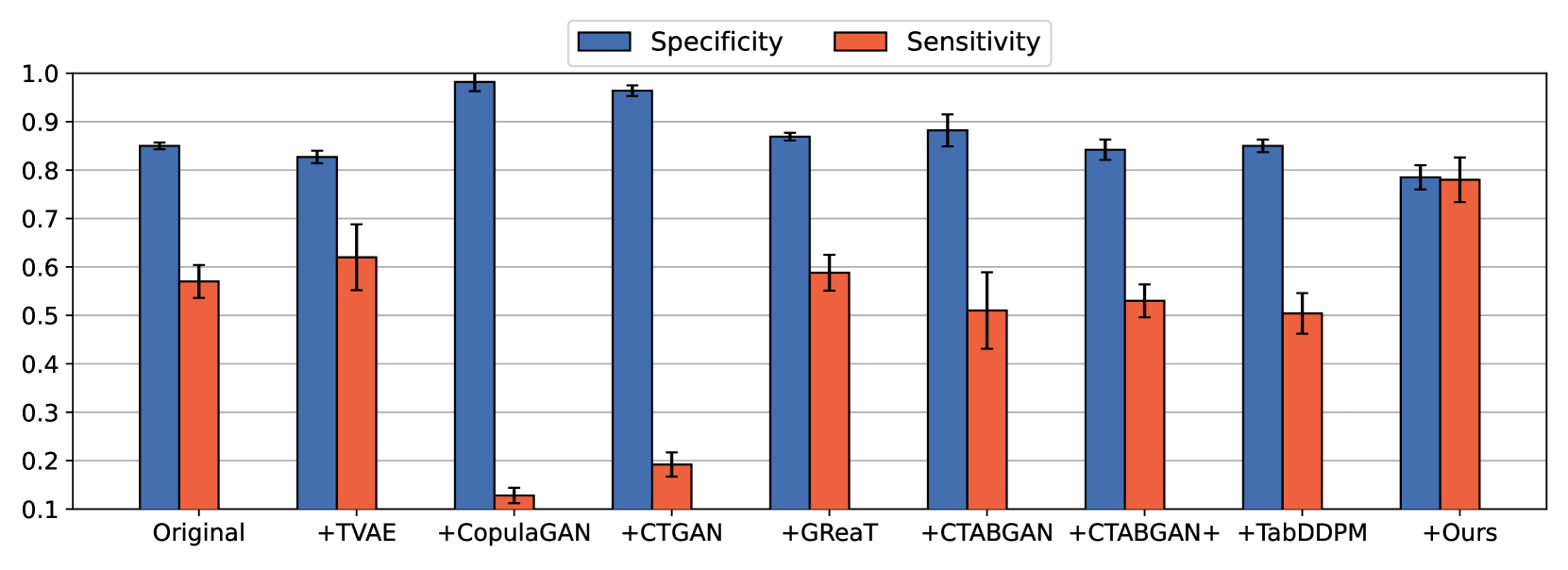
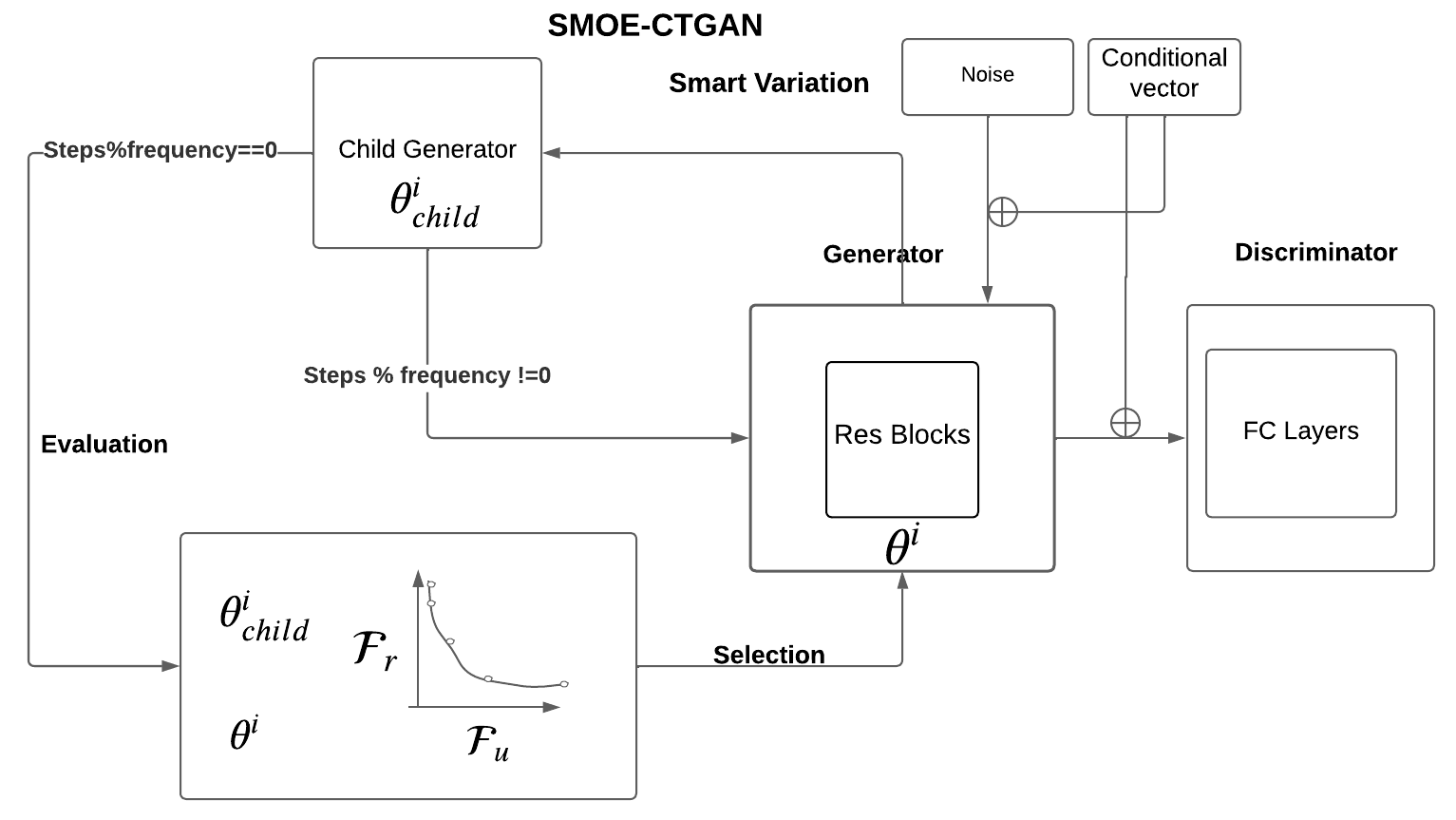
Synthetic data has a key role to play in data sharing by statistical agencies and other generators of statistical data products. Generative Adversarial Networks (GANs), typically applied to image synthesis, are also a promising method for tabular data synthesis. However, there are unique challenges in tabular data compared to images, eg tabular data may contain both continuous and discrete variables and conditional sampling, and, critically, the data should possess high utility and low disclosure risk (the risk of re-identifying a population unit or learning something new about them), providing an opportunity for multi-objective (MO) optimization. Inspired by MO GANs for images, this paper proposes a smart MO evolutionary conditional tabular GAN (SMOE-CTGAN). This approach models conditional synthetic data by applying conditional vectors in training, and uses concepts from MO optimisation to balance disclosure risk against utility. Our results indicate that SMOE-CTGAN is able to discover synthetic datasets with different risk and utility levels for multiple national census datasets. We also find a sweet spot in the early stage of training where a competitive utility and extremely low risk are achieved, by using an Improvement Score. The full code can be downloaded from https://github.com/HuskyNian/SMO_EGAN_pytorch.
4/17/2024
Systematic Assessment of Tabular Data Synthesis Algorithms
Yuntao Du, Ninghui Li
0
0
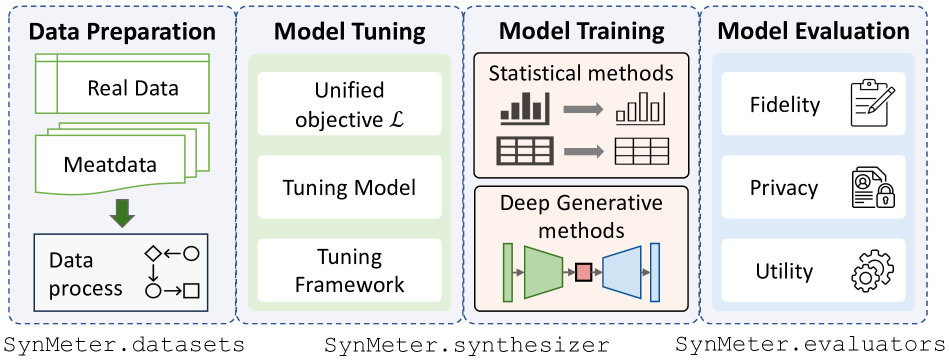
Data synthesis has been advocated as an important approach for utilizing data while protecting data privacy. A large number of tabular data synthesis algorithms (which we call synthesizers) have been proposed. Some synthesizers satisfy Differential Privacy, while others aim to provide privacy in a heuristic fashion. A comprehensive understanding of the strengths and weaknesses of these synthesizers remains elusive due to drawbacks in evaluation metrics and missing head-to-head comparisons of newly developed synthesizers that take advantage of diffusion models and large language models with state-of-the-art marginal-based synthesizers. In this paper, we present a systematic evaluation framework for assessing tabular data synthesis algorithms. Specifically, we examine and critique existing evaluation metrics, and introduce a set of new metrics in terms of fidelity, privacy, and utility to address their limitations. Based on the proposed metrics, we also devise a unified objective for tuning, which can consistently improve the quality of synthetic data for all methods. We conducted extensive evaluations of 8 different types of synthesizers on 12 real-world datasets and identified some interesting findings, which offer new directions for privacy-preserving data synthesis.
4/16/2024
An evaluation framework for synthetic data generation models
Ioannis E. Livieris, Nikos Alimpertis, George Domalis, Dimitris Tsakalidis
0
0
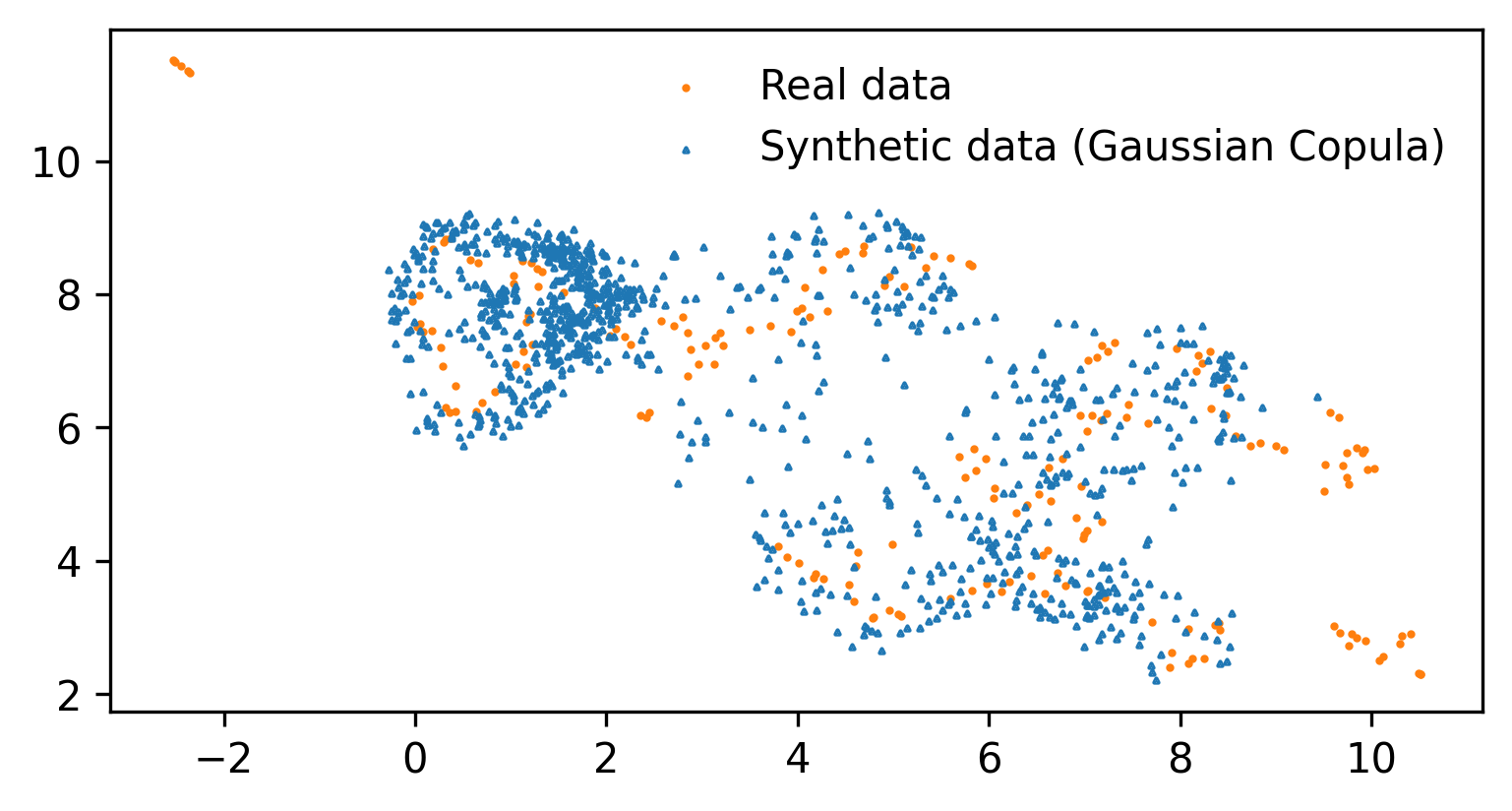
Nowadays, the use of synthetic data has gained popularity as a cost-efficient strategy for enhancing data augmentation for improving machine learning models performance as well as addressing concerns related to sensitive data privacy. Therefore, the necessity of ensuring quality of generated synthetic data, in terms of accurate representation of real data, consists of primary importance. In this work, we present a new framework for evaluating synthetic data generation models' ability for developing high-quality synthetic data. The proposed approach is able to provide strong statistical and theoretical information about the evaluation framework and the compared models' ranking. Two use case scenarios demonstrate the applicability of the proposed framework for evaluating the ability of synthetic data generation models to generated high quality data. The implementation code can be found in https://github.com/novelcore/synthetic_data_evaluation_framework.
4/16/2024