MALLM-GAN: Multi-Agent Large Language Model as Generative Adversarial Network for Synthesizing Tabular Data
2406.10521
0
0
Abstract
In the era of big data, access to abundant data is crucial for driving research forward. However, such data is often inaccessible due to privacy concerns or high costs, particularly in healthcare domain. Generating synthetic (tabular) data can address this, but existing models typically require substantial amounts of data to train effectively, contradicting our objective to solve data scarcity. To address this challenge, we propose a novel framework to generate synthetic tabular data, powered by large language models (LLMs) that emulates the architecture of a Generative Adversarial Network (GAN). By incorporating data generation process as contextual information and utilizing LLM as the optimizer, our approach significantly enhance the quality of synthetic data generation in common scenarios with small sample sizes. Our experimental results on public and private datasets demonstrate that our model outperforms several state-of-art models regarding generating higher quality synthetic data for downstream tasks while keeping privacy of the real data.
Create account to get full access
Overview
- This paper presents a novel generative adversarial network (GAN) called MALLM-GAN that uses a multi-agent large language model (MALLM) to synthesize high-quality tabular data.
- The proposed approach addresses the limitations of existing tabular data synthesis methods, such as the inability to capture complex data distributions and the need for extensive feature engineering.
- MALLM-GAN leverages the powerful representation learning capabilities of large language models to generate tabular data that closely matches the statistical properties of the original dataset.
Plain English Explanation
MALLM-GAN: Multi-Agent Large Language Model as Generative Adversarial Network for Synthesizing Tabular Data is a new method for creating artificial tabular data that looks and behaves like real data, without revealing any sensitive information from the original dataset.
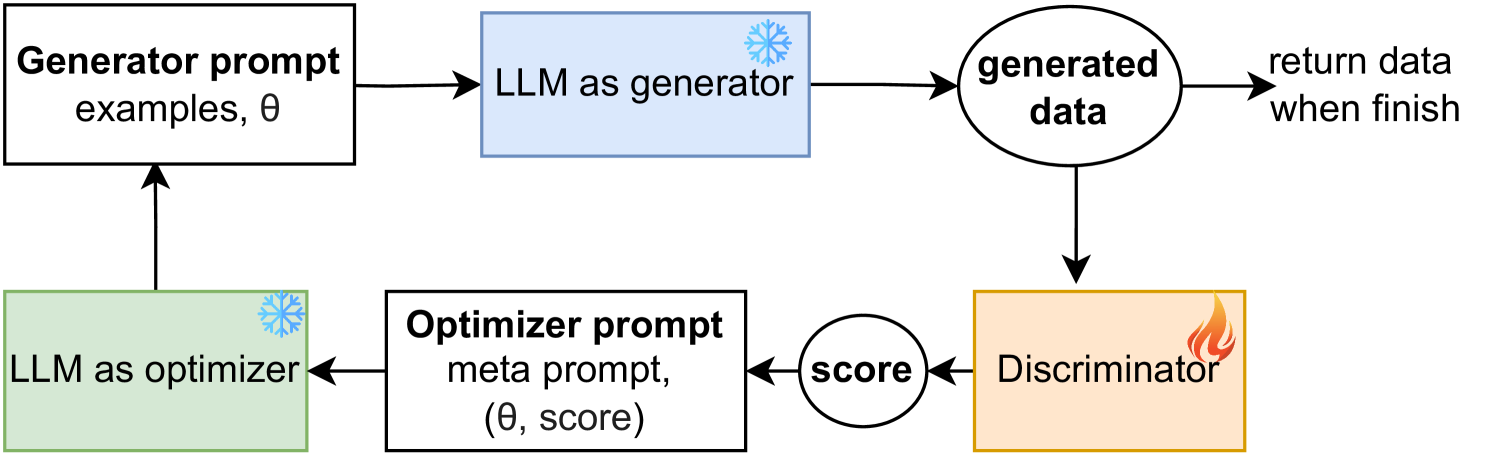
The key idea is to use a special type of machine learning model called a "generative adversarial network" (GAN) that has two parts: a "generator" that tries to create fake data, and a "discriminator" that tries to tell the real data apart from the fake data. By training these two parts against each other, the generator eventually learns to create highly realistic synthetic data.
What makes this approach unique is that the generator uses a "multi-agent large language model" (MALLM) - a powerful AI system that has been trained on massive amounts of text data and can understand and generate human-like language. The researchers found that this MALLM-based generator was able to capture the complex statistical patterns in real tabular data much better than previous methods.
The benefit of this is that the synthetic data can be used for tasks like testing machine learning models or analyzing trends, without having to worry about privacy or security issues with the original sensitive data. The data looks and behaves realistically, but does not contain any actual private information.
Technical Explanation
The core of the MALLM-GAN framework is a generative adversarial network (GAN) that uses a multi-agent large language model (MALLM) as the generator. The MALLM-GAN architecture consists of two main components:
-
Generator: The generator is a MALLM that takes in a random noise vector as input and generates a synthetic tabular data sample. The MALLM is pre-trained on a large corpus of text data, which gives it a strong prior for understanding the statistical structure of data.
-
Discriminator: The discriminator is a neural network classifier that takes in a tabular data sample (either real or synthetic) and predicts whether it is real or fake. The discriminator is trained to accurately distinguish between the real and synthetic data.
During training, the generator and discriminator play an adversarial game, where the generator tries to fool the discriminator by generating increasingly realistic synthetic data, while the discriminator tries to get better at identifying the fakes. This iterative process allows the generator to learn to produce high-quality synthetic tabular data that matches the statistical properties of the original dataset.
The researchers evaluate MALLM-GAN on several real-world tabular datasets and compare it to state-of-the-art tabular data synthesis methods, such as differentially private tabular data synthesis using large language models and improved tabular data generator: VAE-GMM integration. The results show that MALLM-GAN outperforms these baselines in terms of generating synthetic data that preserves the statistical characteristics of the original dataset.
Critical Analysis
One potential limitation of the MALLM-GAN approach is that it requires a large amount of computational resources to train the MALLM generator, which may limit its practical applicability for smaller organizations or datasets. Additionally, the paper does not discuss the privacy or security implications of the generated synthetic data, which is an important consideration for real-world deployment.
Another area for further research could be exploring ways to incorporate additional domain-specific knowledge or constraints into the MALLM-GAN framework, which may help improve the fidelity of the generated data for certain applications. For example, the researchers could investigate ways to integrate large language models with tabular data prediction and generation or explore a supervised generative optimization approach for tabular data synthesis.
Despite these potential limitations, the MALLM-GAN approach represents an important step forward in the field of tabular data synthesis, leveraging the powerful representation learning capabilities of large language models to generate highly realistic synthetic data that can be used for a variety of applications.
Conclusion
The MALLM-GAN paper presents a novel generative adversarial network that uses a multi-agent large language model to synthesize high-quality tabular data. This approach addresses the limitations of existing tabular data synthesis methods by capturing complex data distributions without the need for extensive feature engineering.
The key contribution of this work is the use of a MALLM as the generator in the GAN framework, which allows the model to learn the underlying statistical structure of the data more effectively than previous approaches. The results demonstrate that MALLM-GAN outperforms state-of-the-art tabular data synthesis methods, opening up new possibilities for privacy-preserving data analysis and machine learning model testing.
While the MALLM-GAN approach has some limitations, such as the computational resources required for training, it represents an important step forward in the field of tabular data synthesis and has the potential to significantly impact a wide range of applications that rely on high-quality, privacy-preserving synthetic data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Group-wise Prompting for Synthetic Tabular Data Generation using Large Language Models
Jinhee Kim, Taesung Kim, Jaegul Choo
0
0
Large language models (LLMs) have demonstrated impressive in-context learning capabilities across various domains. Inspired by this, our study explores the effectiveness of LLMs in generating realistic tabular data to mitigate class imbalance. We investigate and identify key prompt design elements such as data format, class presentation, and variable mapping to optimize the generation performance. Our findings indicate that using CSV format, balancing classes, and employing unique variable mapping produces realistic and reliable data, significantly enhancing machine learning performance for minor classes in imbalanced datasets. Additionally, these approaches improve the stability and efficiency of LLM data generation. We validate our approach using six real-world datasets and a toy dataset, achieving state-of-the-art performance in classification tasks. The code is available at: https://github.com/seharanul17/synthetic-tabular-LLM
5/28/2024
Differentially Private Tabular Data Synthesis using Large Language Models
Toan V. Tran, Li Xiong
0
0
Synthetic tabular data generation with differential privacy is a crucial problem to enable data sharing with formal privacy. Despite a rich history of methodological research and development, developing differentially private tabular data generators that can provide realistic synthetic datasets remains challenging. This paper introduces DP-LLMTGen -- a novel framework for differentially private tabular data synthesis that leverages pretrained large language models (LLMs). DP-LLMTGen models sensitive datasets using a two-stage fine-tuning procedure with a novel loss function specifically designed for tabular data. Subsequently, it generates synthetic data through sampling the fine-tuned LLMs. Our empirical evaluation demonstrates that DP-LLMTGen outperforms a variety of existing mechanisms across multiple datasets and privacy settings. Additionally, we conduct an ablation study and several experimental analyses to deepen our understanding of LLMs in addressing this important problem. Finally, we highlight the controllable generation ability of DP-LLMTGen through a fairness-constrained generation setting.
6/4/2024
Are LLMs Naturally Good at Synthetic Tabular Data Generation?
Shengzhe Xu, Cho-Ting Lee, Mandar Sharma, Raquib Bin Yousuf, Nikhil Muralidhar, Naren Ramakrishnan
0
0
Large language models (LLMs) have demonstrated their prowess in generating synthetic text and images; however, their potential for generating tabular data -- arguably the most common data type in business and scientific applications -- is largely underexplored. This paper demonstrates that LLMs, used as-is, or after traditional fine-tuning, are severely inadequate as synthetic table generators. Due to the autoregressive nature of LLMs, fine-tuning with random order permutation runs counter to the importance of modeling functional dependencies, and renders LLMs unable to model conditional mixtures of distributions (key to capturing real world constraints). We showcase how LLMs can be made to overcome some of these deficiencies by making them permutation-aware.
6/24/2024
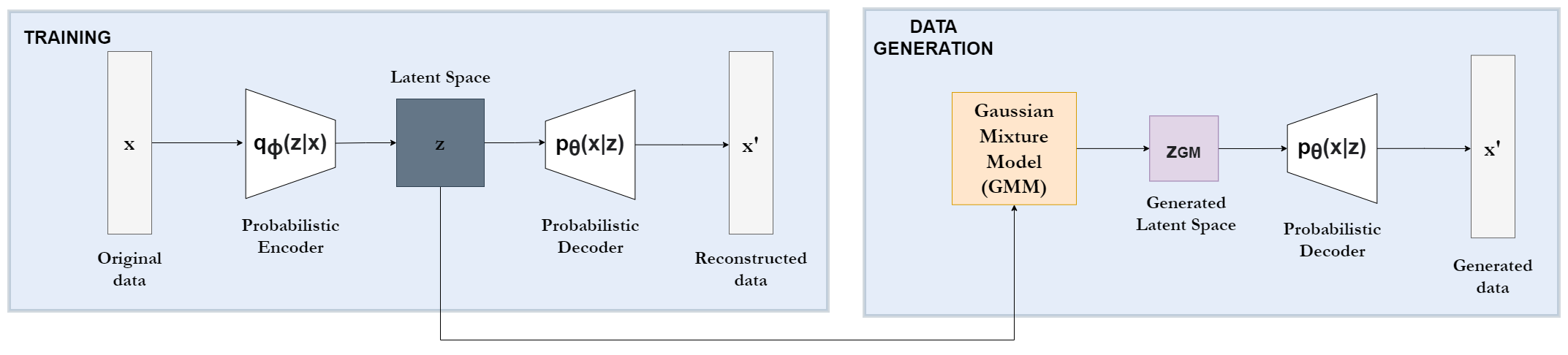
An improved tabular data generator with VAE-GMM integration
Patricia A. Apell'aniz, Juan Parras, Santiago Zazo
0
0
The rising use of machine learning in various fields requires robust methods to create synthetic tabular data. Data should preserve key characteristics while addressing data scarcity challenges. Current approaches based on Generative Adversarial Networks, such as the state-of-the-art CTGAN model, struggle with the complex structures inherent in tabular data. These data often contain both continuous and discrete features with non-Gaussian distributions. Therefore, we propose a novel Variational Autoencoder (VAE)-based model that addresses these limitations. Inspired by the TVAE model, our approach incorporates a Bayesian Gaussian Mixture model (BGM) within the VAE architecture. This avoids the limitations imposed by assuming a strictly Gaussian latent space, allowing for a more accurate representation of the underlying data distribution during data generation. Furthermore, our model offers enhanced flexibility by allowing the use of various differentiable distributions for individual features, making it possible to handle both continuous and discrete data types. We thoroughly validate our model on three real-world datasets with mixed data types, including two medically relevant ones, based on their resemblance and utility. This evaluation demonstrates significant outperformance against CTGAN and TVAE, establishing its potential as a valuable tool for generating synthetic tabular data in various domains, particularly in healthcare.
4/15/2024