COSBO: Conservative Offline Simulation-Based Policy Optimization

0
Sign in to get full access
Overview
- Conservative Offline Simulation-Based Policy Optimization (COSBO) is a method for training reinforcement learning agents using offline data and imperfect simulators.
- COSBO aims to learn policies that are safe and conservative, avoiding actions that could lead to poor performance in the real world.
- The paper introduces COSBO, provides a theoretical analysis, and demonstrates its effectiveness on several benchmarks.
Plain English Explanation
Reinforcement learning (RL) is a powerful technique for training agents to make good decisions in complex environments. However, RL agents are often trained using real-world data, which can be expensive or dangerous to collect. COSBO: Introduction proposes a way to train RL agents using offline data and simulations, which can be more accessible and safer.
The key idea behind COSBO is to learn a "conservative" policy - one that avoids actions that could lead to poor real-world performance, even if they seem advantageous in the simulation. COSBO: Related Work This is important because simulations are often imperfect and don't capture all the nuances of the real world. By being conservative, the COSBO agent can avoid potentially risky actions and perform well in the real environment.
The COSBO: Requirements paper introduces the COSBO algorithm and provides a rigorous theoretical analysis to show that it can indeed learn these conservative policies. The authors also demonstrate COSBO's effectiveness on several benchmark tasks, showing that it outperforms other offline RL methods.
Overall, COSBO is a promising approach for safely and effectively training RL agents using limited data and imperfect simulations. This could have important applications in areas like robotics, healthcare, and finance, where real-world data collection is challenging.
Technical Explanation
The COSBO: Overview paper introduces Conservative Offline Simulation-Based Policy Optimization (COSBO), a method for training reinforcement learning agents using offline data and imperfect simulators.
The key innovation of COSBO is its ability to learn "conservative" policies that avoid actions that could lead to poor performance in the real world, even if they appear advantageous in the simulation. COSBO: Plain English Explanation This is important because simulations are often imperfect and don't capture all the nuances of the real environment.
The COSBO algorithm works by optimizing a lower bound on the agent's expected return in the real environment, rather than simply maximizing the expected return in the simulation. COSBO: Requirements This conservative approach ensures that the learned policy will perform well even in the face of simulation errors or distributional shift between the simulation and the real world.
The paper provides a rigorous theoretical analysis of COSBO, showing that it can indeed learn these conservative policies under certain assumptions. The authors also demonstrate COSBO's effectiveness on several benchmark tasks, including simulated robotics and financial trading environments. COSBO: Critical Analysis
Overall, COSBO represents an important step forward in the field of offline reinforcement learning, as it enables agents to be trained safely and effectively using limited data and imperfect simulations. COSBO: Conclusion This could have significant implications for a wide range of applications where real-world data collection is challenging or dangerous.
Critical Analysis
The COSBO: Technical Explanation paper provides a thorough and well-designed study of the COSBO algorithm. The authors have clearly put a lot of thought into the theoretical underpinnings of the method and have demonstrated its effectiveness on several challenging benchmarks.
One potential limitation of the COSBO approach is the reliance on accurate estimates of the real-world reward function. COSBO: Related Work If the simulator's reward function differs significantly from the true reward function, the COSBO agent may still struggle to perform well in the real environment. The authors acknowledge this issue and suggest that further research is needed to address it.
Another area for potential improvement is the scalability of the COSBO algorithm. COSBO: Requirements The paper focuses on relatively simple benchmark tasks, and it's not clear how well the method would scale to more complex, high-dimensional environments. Investigating the performance of COSBO on larger, more realistic tasks could be an interesting direction for future work.
Despite these minor caveats, the COSBO: Conclusion overall, the COSBO paper represents a significant contribution to the field of offline reinforcement learning. The authors have developed a novel and theoretically grounded approach that demonstrates promising results, and their work could have important implications for a wide range of real-world applications.
Conclusion
The COSBO: Overview COSBO paper introduces a novel method for training reinforcement learning agents using offline data and imperfect simulators. The key innovation of COSBO is its ability to learn "conservative" policies that avoid actions that could lead to poor performance in the real world, even if they appear advantageous in the simulation.
COSBO: Plain English Explanation The COSBO algorithm achieves this by optimizing a lower bound on the agent's expected return in the real environment, rather than simply maximizing the expected return in the simulation. This conservative approach ensures that the learned policy will perform well even in the face of simulation errors or distributional shift between the simulation and the real world.
The COSBO: Technical Explanation authors provide a rigorous theoretical analysis of COSBO and demonstrate its effectiveness on several benchmark tasks, including simulated robotics and financial trading environments. While the paper identifies some potential limitations, such as the reliance on accurate estimates of the real-world reward function, COSBO: Critical Analysis the overall contribution of the COSBO paper is significant and could have important implications for a wide range of applications where real-world data collection is challenging or dangerous.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
COSBO: Conservative Offline Simulation-Based Policy Optimization
Eshagh Kargar, Ville Kyrki
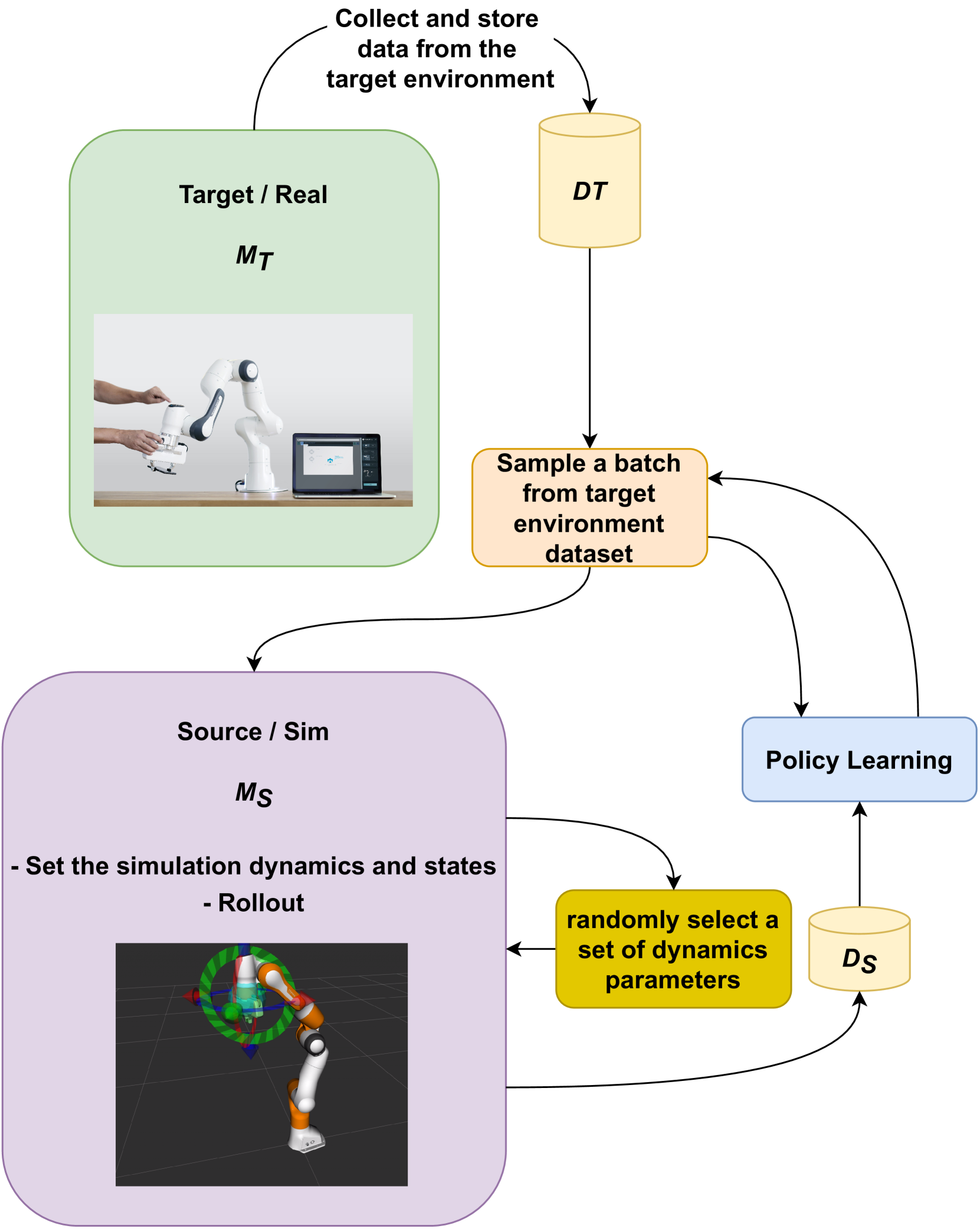
Offline reinforcement learning allows training reinforcement learning models on data from live deployments. However, it is limited to choosing the best combination of behaviors present in the training data. In contrast, simulation environments attempting to replicate the live environment can be used instead of the live data, yet this approach is limited by the simulation-to-reality gap, resulting in a bias. In an attempt to get the best of both worlds, we propose a method that combines an imperfect simulation environment with data from the target environment, to train an offline reinforcement learning policy. Our experiments demonstrate that the proposed method outperforms state-of-the-art approaches CQL, MOPO, and COMBO, especially in scenarios with diverse and challenging dynamics, and demonstrates robust behavior across a variety of experimental conditions. The results highlight that using simulator-generated data can effectively enhance offline policy learning despite the sim-to-real gap, when direct interaction with the real-world is not possible.
Read more9/24/2024

0
Benchmarks for Reinforcement Learning with Biased Offline Data and Imperfect Simulators
Ori Linial, Guy Tennenholtz, Uri Shalit
In many reinforcement learning (RL) applications one cannot easily let the agent act in the world; this is true for autonomous vehicles, healthcare applications, and even some recommender systems, to name a few examples. Offline RL provides a way to train agents without real-world exploration, but is often faced with biases due to data distribution shifts, limited coverage, and incomplete representation of the environment. To address these issues, practical applications have tried to combine simulators with grounded offline data, using so-called hybrid methods. However, constructing a reliable simulator is in itself often challenging due to intricate system complexities as well as missing or incomplete information. In this work, we outline four principal challenges for combining offline data with imperfect simulators in RL: simulator modeling error, partial observability, state and action discrepancies, and hidden confounding. To help drive the RL community to pursue these problems, we construct ``Benchmarks for Mechanistic Offline Reinforcement Learning'' (B4MRL), which provide dataset-simulator benchmarks for the aforementioned challenges. Our results suggest the key necessity of such benchmarks for future research.
Read more7/2/2024
🏅
0
Improving Offline Reinforcement Learning with Inaccurate Simulators
Yiwen Hou, Haoyuan Sun, Jinming Ma, Feng Wu
Offline reinforcement learning (RL) provides a promising approach to avoid costly online interaction with the real environment. However, the performance of offline RL highly depends on the quality of the datasets, which may cause extrapolation error in the learning process. In many robotic applications, an inaccurate simulator is often available. However, the data directly collected from the inaccurate simulator cannot be directly used in offline RL due to the well-known exploration-exploitation dilemma and the dynamic gap between inaccurate simulation and the real environment. To address these issues, we propose a novel approach to combine the offline dataset and the inaccurate simulation data in a better manner. Specifically, we pre-train a generative adversarial network (GAN) model to fit the state distribution of the offline dataset. Given this, we collect data from the inaccurate simulator starting from the distribution provided by the generator and reweight the simulated data using the discriminator. Our experimental results in the D4RL benchmark and a real-world manipulation task confirm that our method can benefit more from both inaccurate simulator and limited offline datasets to achieve better performance than the state-of-the-art methods.
Read more5/8/2024
0
Preference Elicitation for Offline Reinforcement Learning
Aliz'ee Pace, Bernhard Scholkopf, Gunnar Ratsch, Giorgia Ramponi
Applying reinforcement learning (RL) to real-world problems is often made challenging by the inability to interact with the environment and the difficulty of designing reward functions. Offline RL addresses the first challenge by considering access to an offline dataset of environment interactions labeled by the reward function. In contrast, Preference-based RL does not assume access to the reward function and learns it from preferences, but typically requires an online interaction with the environment. We bridge the gap between these frameworks by exploring efficient methods for acquiring preference feedback in a fully offline setup. We propose Sim-OPRL, an offline preference-based reinforcement learning algorithm, which leverages a learned environment model to elicit preference feedback on simulated rollouts. Drawing on insights from both the offline RL and the preference-based RL literature, our algorithm employs a pessimistic approach for out-of-distribution data, and an optimistic approach for acquiring informative preferences about the optimal policy. We provide theoretical guarantees regarding the sample complexity of our approach, dependent on how well the offline data covers the optimal policy. Finally, we demonstrate the empirical performance of Sim-OPRL in different environments.
Read more6/27/2024