Preference Elicitation for Offline Reinforcement Learning
2406.18450
0
0
Abstract
Applying reinforcement learning (RL) to real-world problems is often made challenging by the inability to interact with the environment and the difficulty of designing reward functions. Offline RL addresses the first challenge by considering access to an offline dataset of environment interactions labeled by the reward function. In contrast, Preference-based RL does not assume access to the reward function and learns it from preferences, but typically requires an online interaction with the environment. We bridge the gap between these frameworks by exploring efficient methods for acquiring preference feedback in a fully offline setup. We propose Sim-OPRL, an offline preference-based reinforcement learning algorithm, which leverages a learned environment model to elicit preference feedback on simulated rollouts. Drawing on insights from both the offline RL and the preference-based RL literature, our algorithm employs a pessimistic approach for out-of-distribution data, and an optimistic approach for acquiring informative preferences about the optimal policy. We provide theoretical guarantees regarding the sample complexity of our approach, dependent on how well the offline data covers the optimal policy. Finally, we demonstrate the empirical performance of Sim-OPRL in different environments.
Create account to get full access
Overview
- This paper explores preference elicitation for offline reinforcement learning (RL), where the goal is to learn an agent's preferences from observed behavior rather than through direct interaction.
- The authors propose a novel framework that combines preference elicitation with offline RL, aiming to learn a reward function that best explains the observed behavior.
- They introduce several algorithms and analyze their theoretical guarantees, as well as evaluate their performance on real-world datasets.
Plain English Explanation
In offline reinforcement learning, the agent doesn't get to interact with the environment directly. Instead, it has to learn from previously recorded data, like a person's past decisions or actions. The goal of this paper is to help the agent figure out what the person's preferences are, based on those past behaviors.
The researchers developed a new approach that combines preference elicitation (figuring out what someone likes) with offline reinforcement learning. The idea is to find a reward function - a way to measure how good or bad different outcomes are - that best explains the person's observed behavior. This could be useful for applications like personalized recommendations or modeling human decision-making.
The paper introduces several algorithms for this task and analyzes their theoretical properties. The authors also evaluate the performance of these methods on real-world datasets, to see how well they work in practice.
Technical Explanation
The paper proposes a framework for preference elicitation for offline reinforcement learning. The goal is to learn a reward function that best explains the observed behavior of an agent, without the ability to directly interact with the environment.
The authors formulate the problem as a constrained optimization task, where the objective is to find a reward function that maximizes the likelihood of the observed trajectories. They introduce several algorithms to solve this problem, including a maximum entropy approach and a constrained RL formulation.
The paper provides theoretical analysis of the proposed algorithms, establishing regret bounds and showing that they can recover the true reward function under certain conditions. The authors also evaluate the algorithms on real-world datasets, demonstrating their effectiveness in practice.
Critical Analysis
The paper presents a novel and promising approach to learning preferences from offline data, which can be valuable for a wide range of applications. However, the authors acknowledge several limitations and avenues for future research.
One key limitation is the assumption that the observed behavior is optimal or near-optimal with respect to the true reward function. In many real-world settings, this may not be the case, and the algorithms may struggle to recover the true preferences. The authors suggest exploring approaches that can handle suboptimal behavior, but more work is needed in this area.
Another concern is the scalability of the proposed methods, especially for high-dimensional state and action spaces. The authors discuss potential extensions, such as leveraging function approximation, but the practical feasibility of applying these techniques to complex, real-world problems remains an open question.
Additionally, the paper does not address the issue of reward misspecification, where the true reward function may not be representable within the chosen function class. Robust approaches that can handle reward model uncertainty would be an important direction for future research.
Conclusion
This paper presents a novel framework for preference elicitation in offline reinforcement learning. The authors introduce several algorithms with theoretical guarantees and evaluate their performance on real-world datasets. While the proposed methods show promise, the paper also highlights important limitations and opportunities for further research in this area.
The ability to learn preferences from offline data has significant implications for a wide range of applications, from personalized recommendation systems to human-robot interaction. The techniques developed in this paper provide a solid foundation for future work in this direction, paving the way for more robust and scalable preference elicitation methods that can handle the complexities of real-world decision-making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Optimal Reward Labeling: Bridging Offline Preference and Reward-Based Reinforcement Learning
Yinglun Xu, David Zhu, Rohan Gumastate, Gagandeep Singh
0
0
Offline reinforcement learning has become one of the most practical RL settings. A recent success story has been RLHF, offline preference-based RL (PBRL) with preference from humans. However, most existing works on offline RL focus on the standard setting with scalar reward feedback. It remains unknown how to universally transfer the existing rich understanding of offline RL from the reward-based to the preference-based setting. In this work, we propose a general framework to bridge this gap. Our key insight is transforming preference feedback to scalar rewards via optimal reward labeling (ORL), and then any reward-based offline RL algorithms can be applied to the dataset with the reward labels. We theoretically show the connection between several recent PBRL techniques and our framework combined with specific offline RL algorithms in terms of how they utilize the preference signals. By combining reward labeling with different algorithms, our framework can lead to new and potentially more efficient offline PBRL algorithms. We empirically test our framework on preference datasets based on the standard D4RL benchmark. When combined with a variety of efficient reward-based offline RL algorithms, the learning result achieved under our framework is comparable to training the same algorithm on the dataset with actual rewards in many cases and better than the recent PBRL baselines in most cases.
6/18/2024

Online Bandit Learning with Offline Preference Data
Akhil Agnihotri, Rahul Jain, Deepak Ramachandran, Zheng Wen
0
0
Reinforcement Learning with Human Feedback (RLHF) is at the core of fine-tuning methods for generative AI models for language and images. Such feedback is often sought as rank or preference feedback from human raters, as opposed to eliciting scores since the latter tends to be very noisy. On the other hand, RL theory and algorithms predominantly assume that a reward feedback is available. In particular, approaches for online learning that can be helpful in adaptive data collection via active learning cannot incorporate offline preference data. In this paper, we adopt a finite-armed linear bandit model as a prototypical model of online learning. We consider an offline preference dataset to be available generated by an expert of unknown 'competence'. We propose $texttt{warmPref-PS}$, a posterior sampling algorithm for online learning that can be warm-started with an offline dataset with noisy preference feedback. We show that by modeling the competence of the expert that generated it, we are able to use such a dataset most effectively. We support our claims with novel theoretical analysis of its Bayesian regret, as well as extensive empirical evaluation of an approximate algorithm which performs substantially better (almost 25 to 50% regret reduction in our studies) as compared to baselines.
6/17/2024
Preferred-Action-Optimized Diffusion Policies for Offline Reinforcement Learning
Tianle Zhang, Jiayi Guan, Lin Zhao, Yihang Li, Dongjiang Li, Zecui Zeng, Lei Sun, Yue Chen, Xuelong Wei, Lusong Li, Xiaodong He
0
0
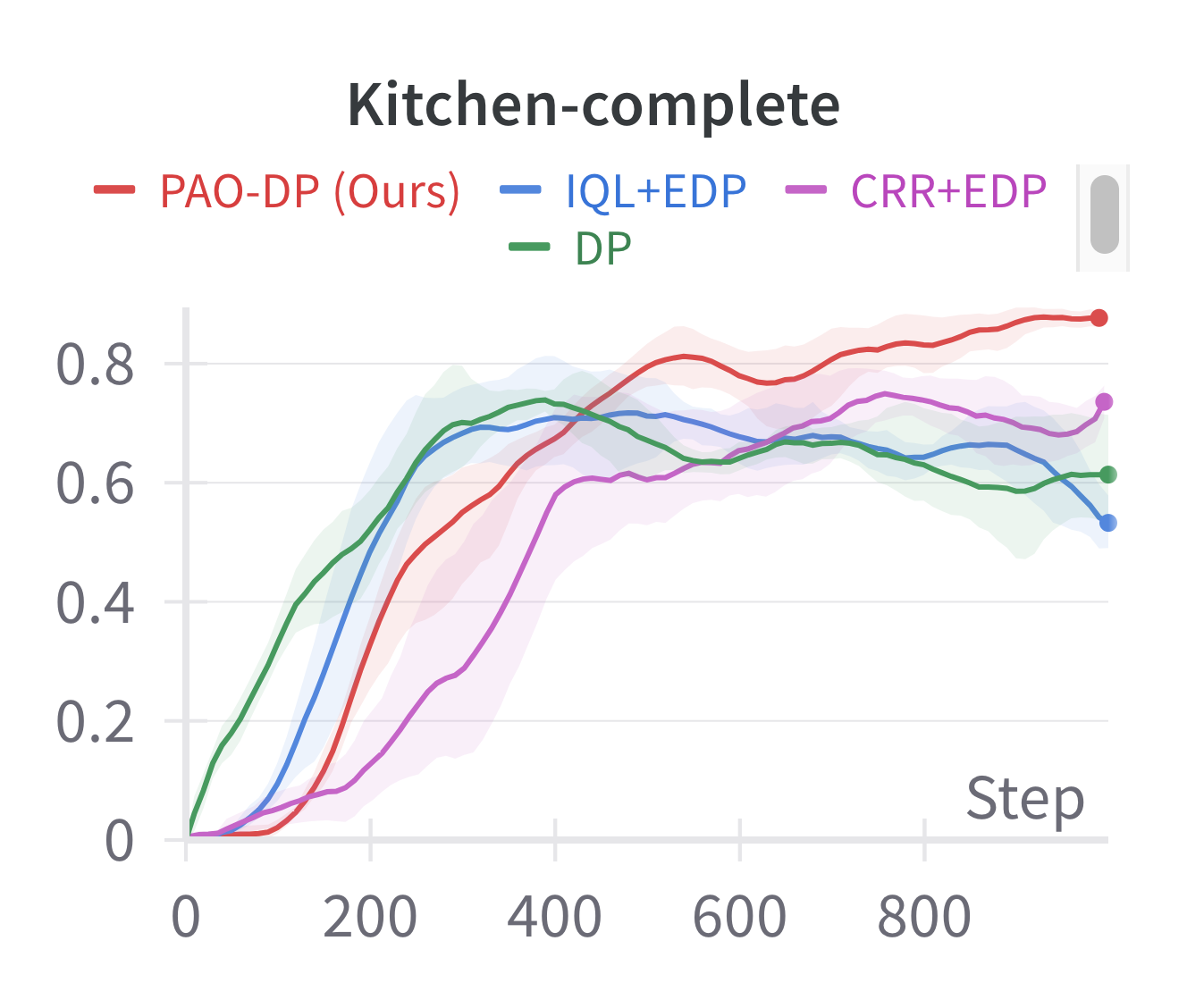
Offline reinforcement learning (RL) aims to learn optimal policies from previously collected datasets. Recently, due to their powerful representational capabilities, diffusion models have shown significant potential as policy models for offline RL issues. However, previous offline RL algorithms based on diffusion policies generally adopt weighted regression to improve the policy. This approach optimizes the policy only using the collected actions and is sensitive to Q-values, which limits the potential for further performance enhancement. To this end, we propose a novel preferred-action-optimized diffusion policy for offline RL. In particular, an expressive conditional diffusion model is utilized to represent the diverse distribution of a behavior policy. Meanwhile, based on the diffusion model, preferred actions within the same behavior distribution are automatically generated through the critic function. Moreover, an anti-noise preference optimization is designed to achieve policy improvement by using the preferred actions, which can adapt to noise-preferred actions for stable training. Extensive experiments demonstrate that the proposed method provides competitive or superior performance compared to previous state-of-the-art offline RL methods, particularly in sparse reward tasks such as Kitchen and AntMaze. Additionally, we empirically prove the effectiveness of anti-noise preference optimization.
5/30/2024
Value-Incentivized Preference Optimization: A Unified Approach to Online and Offline RLHF
Shicong Cen, Jincheng Mei, Katayoon Goshvadi, Hanjun Dai, Tong Yang, Sherry Yang, Dale Schuurmans, Yuejie Chi, Bo Dai
0
0
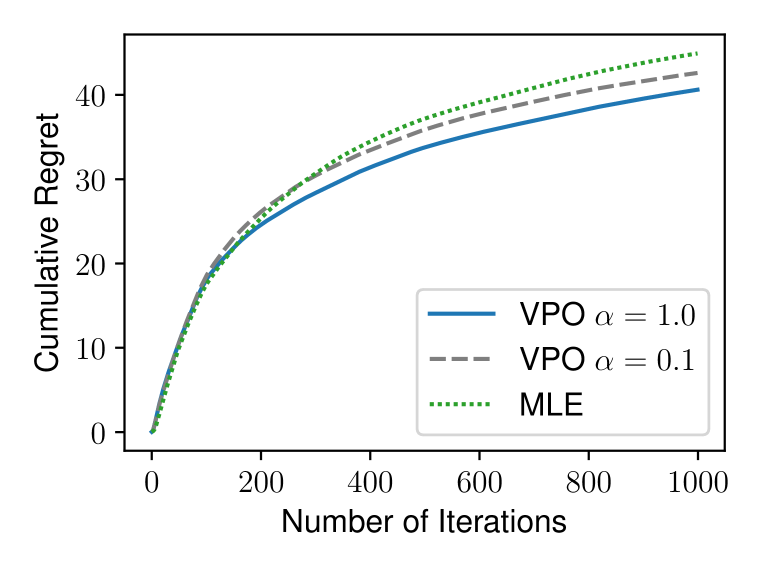
Reinforcement learning from human feedback (RLHF) has demonstrated great promise in aligning large language models (LLMs) with human preference. Depending on the availability of preference data, both online and offline RLHF are active areas of investigation. A key bottleneck is understanding how to incorporate uncertainty estimation in the reward function learned from the preference data for RLHF, regardless of how the preference data is collected. While the principles of optimism or pessimism under uncertainty are well-established in standard reinforcement learning (RL), a practically-implementable and theoretically-grounded form amenable to large language models is not yet available, as standard techniques for constructing confidence intervals become intractable under arbitrary policy parameterizations. In this paper, we introduce a unified approach to online and offline RLHF -- value-incentivized preference optimization (VPO) -- which regularizes the maximum-likelihood estimate of the reward function with the corresponding value function, modulated by a $textit{sign}$ to indicate whether the optimism or pessimism is chosen. VPO also directly optimizes the policy with implicit reward modeling, and therefore shares a simpler RLHF pipeline similar to direct preference optimization. Theoretical guarantees of VPO are provided for both online and offline settings, matching the rates of their standard RL counterparts. Moreover, experiments on text summarization and dialog verify the practicality and effectiveness of VPO.
6/6/2024