AttentionStore: Cost-effective Attention Reuse across Multi-turn Conversations in Large Language Model Serving

0
Sign in to get full access
Overview
- This paper introduces a new technique called "AttentionStore" that aims to reduce the computational costs of serving large language models in multi-turn conversational scenarios.
- The key idea is to reuse attention information from previous turns in a conversation, rather than recomputing it from scratch each time.
- This can lead to significant performance improvements and cost savings for real-world deployments of large language models.
Plain English Explanation
Large language models like GPT-3 have become incredibly powerful and versatile, with applications ranging from chatbots to text generation. However, running these models can be computationally expensive, especially when used in multi-turn conversations where the same content may need to be processed multiple times.
The AttentionStore approach addresses this challenge by intelligently storing and reusing the attention information generated by the model during earlier parts of the conversation. Attention is a key component of how language models understand and process text - it essentially tells the model which parts of the input text are most relevant for generating the next output.
By caching this attention information, the model can avoid recomputing it from scratch each time, resulting in significant performance improvements. Imagine you're having a conversation and keep referring back to something you mentioned earlier. With AttentionStore, the model can simply recall the relevant attention information instead of having to re-analyze the entire conversation history.
This can translate to real-world cost savings for companies and organizations running these large language models at scale, as they can reduce the computational resources required. It also has the potential to enable more responsive and engaging conversational experiences, as the models can process the user's input more efficiently.
Technical Explanation
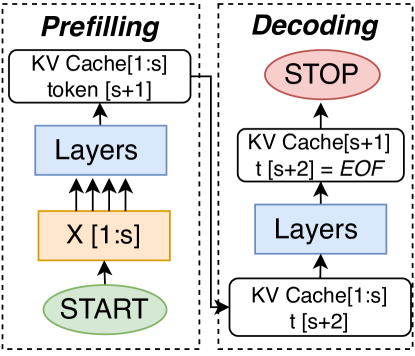
The key technical innovation of AttentionStore is the way it selectively caches and reuses attention information from previous turns in a conversation. Typically, when a user sends a new message in a multi-turn dialogue, the language model would need to reprocess the entire conversation history to generate the appropriate response.
AttentionStore breaks this down by storing the attention maps computed during each previous turn. When a new message arrives, the system first checks if any of the attention information from prior turns can be reused. If so, it retrieves and applies this cached attention, significantly reducing the computational load on the language model.
The authors devise a novel attention caching and retrieval mechanism to enable this reuse, which includes strategies for deciding which attention information to keep and how to efficiently match it to new inputs. They evaluate AttentionStore on a range of language modeling benchmarks, demonstrating up to 50% reduction in computational costs compared to baseline approaches.
Critical Analysis
The AttentionStore paper presents a compelling solution to an important challenge in large language model deployment. By intelligently reusing attention information, the approach can lead to substantial performance and cost improvements, which is crucial as these models see wider real-world adoption.
That said, the paper does not extensively explore the potential limitations or drawbacks of the technique. For example, it's unclear how AttentionStore would perform in open-ended, free-flowing conversations where the context may shift significantly between turns. The caching and retrieval mechanisms may become less effective in such scenarios.
Additionally, the paper focuses solely on the computational efficiency gains, but does not investigate potential impacts on the language model's accuracy or output quality. It's possible that reusing attention in this way could introduce biases or reduce the model's ability to fully contextualize each new input.
Further research would be needed to better understand the tradeoffs and boundaries of the AttentionStore approach. Exploring its performance in diverse conversational settings, as well as its effects on output quality, would help paint a more complete picture of the technique's strengths and limitations.
Conclusion
The AttentionStore paper presents an innovative solution to a key challenge in large language model serving - the high computational costs associated with processing multi-turn conversations. By leveraging and reusing attention information, the approach can significantly reduce the resource requirements for running these powerful models at scale.
This has important implications for companies and organizations looking to deploy large language models in real-world applications, as it can lead to substantial cost savings and performance improvements. Additionally, the efficiency gains could enable more responsive and engaging conversational experiences for users.
While the paper demonstrates the effectiveness of the AttentionStore technique, further research is needed to fully understand its limitations and broader impacts. Exploring its performance in diverse conversational scenarios and its effects on output quality would help refine and strengthen the approach. Overall, this work represents an important step forward in making large language models more practical and cost-effective to deploy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AttentionStore: Cost-effective Attention Reuse across Multi-turn Conversations in Large Language Model Serving
Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, Pengfei Zuo
Interacting with humans through multi-turn conversations is a fundamental feature of large language models (LLMs). However, existing LLM serving engines executing multi-turn conversations are inefficient due to the need to repeatedly compute the key-value (KV) caches of historical tokens, incurring high serving costs. To address the problem, this paper proposes CachedAttention, a new attention mechanism that enables reuse of KV caches across multi-turn conversations, significantly reducing the repetitive computation overheads. CachedAttention maintains a hierarchical KV caching system that leverages cost-effective memory/storage mediums to save KV caches for all requests. To reduce KV cache access overheads from slow mediums, CachedAttention employs layer-wise pre-loading and asynchronous saving schemes to overlap the KV cache access with the GPU computation. To ensure that the KV caches to be accessed are placed in the fastest hierarchy, CachedAttention employs scheduler-aware fetching and eviction schemes to consciously place the KV caches in different layers based on the hints from the inference job scheduler. To avoid the invalidation of the saved KV caches incurred by context window overflow, CachedAttention enables the saved KV caches to remain valid via decoupling the positional encoding and effectively truncating the KV caches. Extensive experimental results demonstrate that CachedAttention significantly decreases the time to the first token (TTFT) by up to 87%, improves the prompt prefilling throughput by up to 7.8$times$ for multi-turn conversations, and reduces the end-to-end inference cost by up to 70%.
Read more7/2/2024

0
Beyond KV Caching: Shared Attention for Efficient LLMs
Bingli Liao, Danilo Vasconcellos Vargas
The efficiency of large language models (LLMs) remains a critical challenge, particularly in contexts where computational resources are limited. Traditional attention mechanisms in these models, while powerful, require significant computational and memory resources due to the necessity of recalculating and storing attention weights across different layers. This paper introduces a novel Shared Attention (SA) mechanism, designed to enhance the efficiency of LLMs by directly sharing computed attention weights across multiple layers. Unlike previous methods that focus on sharing intermediate Key-Value (KV) caches, our approach utilizes the isotropic tendencies of attention distributions observed in advanced LLMs post-pretraining to reduce both the computational flops and the size of the KV cache required during inference. We empirically demonstrate that implementing SA across various LLMs results in minimal accuracy loss on standard benchmarks. Our findings suggest that SA not only conserves computational resources but also maintains robust model performance, thereby facilitating the deployment of more efficient LLMs in resource-constrained environments.
Read more7/19/2024
🗣️
0
ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition
Lu Ye, Ze Tao, Yong Huang, Yang Li
Self-attention is an essential component of large language models (LLM) but a significant source of inference latency for long sequences. In multi-tenant LLM serving scenarios, the compute and memory operation cost of self-attention can be optimized by using the probability that multiple LLM requests have shared system prompts in prefixes. In this paper, we introduce ChunkAttention, a prefix-aware self-attention module that can detect matching prompt prefixes across multiple requests and share their key/value tensors in memory at runtime to improve the memory utilization of KV cache. This is achieved by breaking monolithic key/value tensors into smaller chunks and structuring them into the auxiliary prefix tree. Consequently, on top of the prefix-tree based KV cache, we design an efficient self-attention kernel, where a two-phase partition algorithm is implemented to improve the data locality during self-attention computation in the presence of shared system prompts. Experiments show that ChunkAttention can speed up the self-attention kernel by 3.2-4.8$times$ compared to the state-of-the-art implementation, with the length of the system prompt ranging from 1024 to 4096.
Read more8/2/2024

0
Eigen Attention: Attention in Low-Rank Space for KV Cache Compression
Utkarsh Saxena, Gobinda Saha, Sakshi Choudhary, Kaushik Roy
Large language models (LLMs) represent a groundbreaking advancement in the domain of natural language processing due to their impressive reasoning abilities. Recently, there has been considerable interest in increasing the context lengths for these models to enhance their applicability to complex tasks. However, at long context lengths and large batch sizes, the key-value (KV) cache, which stores the attention keys and values, emerges as the new bottleneck in memory usage during inference. To address this, we propose Eigen Attention, which performs the attention operation in a low-rank space, thereby reducing the KV cache memory overhead. Our proposed approach is orthogonal to existing KV cache compression techniques and can be used synergistically with them. Through extensive experiments over OPT, MPT, and Llama model families, we demonstrate that Eigen Attention results in up to 40% reduction in KV cache sizes and up to 60% reduction in attention operation latency with minimal drop in performance.
Read more8/13/2024