Eigen Attention: Attention in Low-Rank Space for KV Cache Compression

0

Sign in to get full access
Overview
- The paper introduces "Eigen Attention", a novel attention mechanism for low-rank compression of key-value (KV) caches in large language models (LLMs).
- KV caches store previous attention patterns to improve model inference speed, but they can consume significant memory. Eigen Attention aims to compress these caches efficiently.
- The technique leverages the low-rank structure of attention patterns to represent them in a compact form, reducing memory usage without significantly impacting model performance.
Plain English Explanation
Imagine you're building a very large AI model that can understand and generate human language. As the model processes more and more text, it starts to notice patterns in how words and phrases are related to each other. The model stores these patterns in a special memory bank called a "key-value cache" to help it respond quickly to future questions or prompts.
However, this cache can quickly become very large and take up a lot of memory, which makes the model run slower. The researchers behind this paper came up with a clever way to compress the cache without losing too much of its usefulness.
The key insight is that the patterns stored in the cache often have a "low-rank" structure, meaning they can be represented using just a few core components. The researchers' "Eigen Attention" technique taps into this low-rank structure to create a compact version of the cache that takes up much less memory. When the model needs to access the cache, it can quickly reconstruct the full pattern from this compressed version.
This compression technique allows the large AI model to run more efficiently, without sacrificing its language understanding capabilities. It's a smart way to optimize the model's use of memory and make it faster and more practical to use in real-world applications.
Technical Explanation
The paper introduces "Eigen Attention", a novel attention mechanism for compressing key-value (KV) caches in large language models (LLMs). KV caches store previous attention patterns to improve model inference speed, but they can consume significant memory.
Eigen Attention leverages the low-rank structure of attention patterns to represent them in a compact form. The key idea is to decompose the attention matrix into a product of low-rank matrices, effectively compressing the KV cache.
During inference, the model can efficiently reconstruct the full attention matrix from this low-rank representation, enabling fast cache lookups without a significant loss in performance. The paper demonstrates the effectiveness of Eigen Attention on several LLM benchmarks, achieving up to 4x compression rates while maintaining model accuracy.
This work builds upon recent advances in efficient attention mechanisms and KV cache compression for LLMs. By exploiting the low-rank structure of attention, Eigen Attention provides a novel and effective approach to managing KV caches in a memory-efficient manner.
Critical Analysis
The paper makes a compelling case for Eigen Attention as an effective technique for compressing KV caches in LLMs. The key strength of the approach is its ability to leverage the low-rank structure of attention patterns, enabling significant memory savings without a substantial impact on model performance.
However, the paper does not explore the potential limitations of this technique. For example, it would be valuable to understand how Eigen Attention might perform on attention patterns with more complex structures that deviate from the assumed low-rank form. Additionally, the paper could have provided more insights into the computational overhead and latency impact of the compression and decompression operations during inference.
Further research could also investigate the interplay between Eigen Attention and other efficient attention mechanisms, such as Sparse Attention or Shared Attention. Combining these approaches may lead to even more memory-efficient and performant LLM architectures.
Overall, the Eigen Attention technique represents an important contribution to the ongoing efforts to optimize the memory footprint and inference speed of large language models. As AI systems continue to grow in size and complexity, innovations like this will be crucial for making these models practical and accessible in real-world applications.
Conclusion
The Eigen Attention paper introduces a novel compression technique for key-value caches in large language models. By exploiting the low-rank structure of attention patterns, the method can significantly reduce the memory required to store these caches without a substantial impact on model performance.
This work represents an important advancement in the field of efficient attention mechanisms and KV cache management for LLMs. As AI models continue to grow in size and complexity, techniques like Eigen Attention will be crucial for making these systems more memory-efficient and practical to deploy in real-world applications. While the paper could have explored some potential limitations, it nonetheless provides a valuable contribution to the ongoing efforts to optimize the performance and scalability of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Eigen Attention: Attention in Low-Rank Space for KV Cache Compression
Utkarsh Saxena, Gobinda Saha, Sakshi Choudhary, Kaushik Roy
Large language models (LLMs) represent a groundbreaking advancement in the domain of natural language processing due to their impressive reasoning abilities. Recently, there has been considerable interest in increasing the context lengths for these models to enhance their applicability to complex tasks. However, at long context lengths and large batch sizes, the key-value (KV) cache, which stores the attention keys and values, emerges as the new bottleneck in memory usage during inference. To address this, we propose Eigen Attention, which performs the attention operation in a low-rank space, thereby reducing the KV cache memory overhead. Our proposed approach is orthogonal to existing KV cache compression techniques and can be used synergistically with them. Through extensive experiments over OPT, MPT, and Llama model families, we demonstrate that Eigen Attention results in up to 40% reduction in KV cache sizes and up to 60% reduction in attention operation latency with minimal drop in performance.
Read more8/13/2024

0
RazorAttention: Efficient KV Cache Compression Through Retrieval Heads
Hanlin Tang, Yang Lin, Jing Lin, Qingsen Han, Shikuan Hong, Yiwu Yao, Gongyi Wang
The memory and computational demands of Key-Value (KV) cache present significant challenges for deploying long-context language models. Previous approaches attempt to mitigate this issue by selectively dropping tokens, which irreversibly erases critical information that might be needed for future queries. In this paper, we propose a novel compression technique for KV cache that preserves all token information. Our investigation reveals that: i) Most attention heads primarily focus on the local context; ii) Only a few heads, denoted as retrieval heads, can essentially pay attention to all input tokens. These key observations motivate us to use separate caching strategy for attention heads. Therefore, we propose RazorAttention, a training-free KV cache compression algorithm, which maintains a full cache for these crucial retrieval heads and discards the remote tokens in non-retrieval heads. Furthermore, we introduce a novel mechanism involving a compensation token to further recover the information in the dropped tokens. Extensive evaluations across a diverse set of large language models (LLMs) demonstrate that RazorAttention achieves a reduction in KV cache size by over 70% without noticeable impacts on performance. Additionally, RazorAttention is compatible with FlashAttention, rendering it an efficient and plug-and-play solution that enhances LLM inference efficiency without overhead or retraining of the original model.
Read more7/24/2024
0
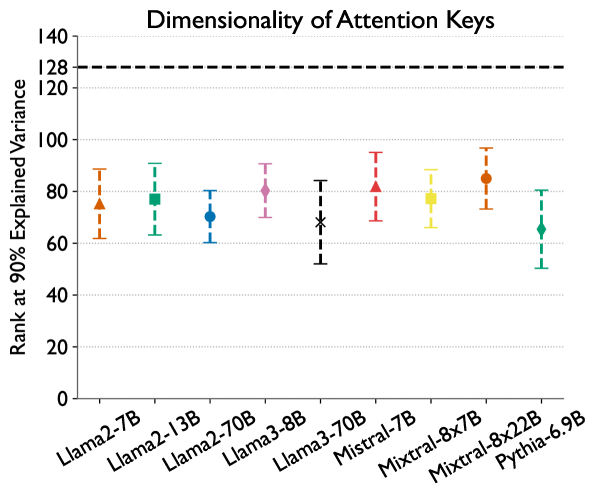
Loki: Low-Rank Keys for Efficient Sparse Attention
Prajwal Singhania, Siddharth Singh, Shwai He, Soheil Feizi, Abhinav Bhatele
Inference on large language models can be expensive in terms of the compute and memory costs involved, especially when long sequence lengths are used. In particular, the self-attention mechanism used in such models contributes significantly to these costs, which has resulted in several recent works that propose sparse attention approximations for inference. In this work, we propose to approximate the self-attention computation by focusing on the dimensionality of key vectors computed in the attention block. Our analysis reveals that the key vectors lie in a significantly lower-dimensional space, consistently across several datasets and models. Exploiting this observation, we propose Loki, a novel sparse attention method that ranks and selects tokens in the KV-cache based on attention scores computed in low-dimensional space. Our evaluations show that Loki is able to maintain the efficacy of the models better than other popular approximation methods, while speeding up the attention computation due to reduced data movement (load/store) and compute costs.
Read more6/5/2024

0
Beyond KV Caching: Shared Attention for Efficient LLMs
Bingli Liao, Danilo Vasconcellos Vargas
The efficiency of large language models (LLMs) remains a critical challenge, particularly in contexts where computational resources are limited. Traditional attention mechanisms in these models, while powerful, require significant computational and memory resources due to the necessity of recalculating and storing attention weights across different layers. This paper introduces a novel Shared Attention (SA) mechanism, designed to enhance the efficiency of LLMs by directly sharing computed attention weights across multiple layers. Unlike previous methods that focus on sharing intermediate Key-Value (KV) caches, our approach utilizes the isotropic tendencies of attention distributions observed in advanced LLMs post-pretraining to reduce both the computational flops and the size of the KV cache required during inference. We empirically demonstrate that implementing SA across various LLMs results in minimal accuracy loss on standard benchmarks. Our findings suggest that SA not only conserves computational resources but also maintains robust model performance, thereby facilitating the deployment of more efficient LLMs in resource-constrained environments.
Read more7/19/2024