Countermeasures Against Adversarial Examples in Radio Signal Classification

0

Sign in to get full access
Overview
- This paper explores countermeasures against adversarial examples in radio signal classification using deep learning models.
- Adversarial examples are carefully crafted input samples that can cause deep learning models to misclassify the input, even though the changes are imperceptible to humans.
- The authors propose several techniques to improve the robustness of radio signal classification models against adversarial attacks, including neural rejection, label smoothing, and ensemble methods.
Plain English Explanation
Deep learning models, which are a type of artificial intelligence, have become very good at tasks like classifying radio signals. However, these models can be fooled by "adversarial examples" - inputs that are slightly altered in ways that humans can't detect, but cause the model to make mistakes.
The researchers in this paper wanted to find ways to make these radio classification models more robust against these adversarial attacks. They tested out a few different techniques:
-
Neural Rejection: This involves training the model to not only classify the input, but also recognize when the input is an adversarial example that it shouldn't trust.
-
Label Smoothing: Instead of training the model to output a single "correct" label, this technique encourages the model to output a distribution of slightly less confident labels. This makes the model more resilient to small perturbations.
-
Ensemble Methods: The researchers combined multiple models together, so that if one model is tricked by an adversarial example, the others might still classify it correctly.
By using these techniques, the researchers were able to significantly improve the ability of radio classification models to resist adversarial attacks, while still maintaining good performance on regular, unaltered inputs. This makes these models more reliable and trustworthy for real-world applications.
Technical Explanation
The paper first introduces the problem of adversarial examples in the context of radio signal classification using deep learning models. Adversarial examples are inputs that have been carefully perturbed in imperceptible ways, causing the model to misclassify the input. This poses a significant security risk for real-world applications of these models.
To address this, the authors propose several countermeasures:
-
Neural Rejection: The model is trained not only to classify the input signal, but also to detect whether the input is an adversarial example that should be rejected. This is done by adding an additional output logit to the model that represents the "rejection" class.
-
Label Smoothing: Instead of training the model to output a one-hot encoded label, the authors use a smoothed label distribution that assigns some probability mass to incorrect classes. This makes the model more robust to small perturbations.
-
Ensemble Methods: The authors train multiple models independently and then combine their outputs using majority voting. This ensures that if one model is fooled by an adversarial example, the others in the ensemble may still classify it correctly.
The authors evaluate these techniques on a dataset of radio signals and show that they are able to significantly improve the models' robustness against adversarial attacks, as measured by standard adversarial robustness metrics. They also demonstrate that the proposed techniques maintain good classification performance on unperturbed inputs.
Critical Analysis
The paper presents a thorough and well-designed study on improving the adversarial robustness of radio signal classification models. The proposed techniques are intuitive and well-grounded in existing literature on adversarial machine learning.
One potential limitation is that the evaluation is focused on a specific dataset and type of adversarial attack (white-box attacks using the Fast Gradient Sign Method). It would be valuable to see how the techniques perform against a broader range of adversarial attacks and on additional datasets to assess their generalizability.
Additionally, the paper does not provide much insight into the underlying reasons why the proposed techniques are effective. A deeper analysis of the model behavior and internal representations could lead to a better understanding of the mechanisms by which these countermeasures improve robustness.
Overall, this paper makes a valuable contribution to the field of adversarial machine learning, particularly in the context of radio signal classification. The techniques presented could be applied to improve the security and reliability of deep learning models in other domains as well.
Conclusion
This paper tackles the important problem of adversarial examples in radio signal classification using deep learning models. The authors propose several effective countermeasures, including neural rejection, label smoothing, and ensemble methods, that significantly improve the models' robustness against adversarial attacks while maintaining good performance on regular inputs.
The techniques presented in this work have the potential to enhance the reliability and trustworthiness of deep learning-based radio signal classification systems, which are crucial for a wide range of real-world applications. The insights and methods developed in this research could also be applied to address adversarial vulnerabilities in other machine learning domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Countermeasures Against Adversarial Examples in Radio Signal Classification
Lu Zhang, Sangarapillai Lambotharan, Gan Zheng, Basil AsSadhan, Fabio Roli
Deep learning algorithms have been shown to be powerful in many communication network design problems, including that in automatic modulation classification. However, they are vulnerable to carefully crafted attacks called adversarial examples. Hence, the reliance of wireless networks on deep learning algorithms poses a serious threat to the security and operation of wireless networks. In this letter, we propose for the first time a countermeasure against adversarial examples in modulation classification. Our countermeasure is based on a neural rejection technique, augmented by label smoothing and Gaussian noise injection, that allows to detect and reject adversarial examples with high accuracy. Our results demonstrate that the proposed countermeasure can protect deep-learning based modulation classification systems against adversarial examples.
Read more7/10/2024
0
A Hybrid Training-time and Run-time Defense Against Adversarial Attacks in Modulation Classification
Lu Zhang, Sangarapillai Lambotharan, Gan Zheng, Guisheng Liao, Ambra Demontis, Fabio Roli
Motivated by the superior performance of deep learning in many applications including computer vision and natural language processing, several recent studies have focused on applying deep neural network for devising future generations of wireless networks. However, several recent works have pointed out that imperceptible and carefully designed adversarial examples (attacks) can significantly deteriorate the classification accuracy. In this paper, we investigate a defense mechanism based on both training-time and run-time defense techniques for protecting machine learning-based radio signal (modulation) classification against adversarial attacks. The training-time defense consists of adversarial training and label smoothing, while the run-time defense employs a support vector machine-based neural rejection (NR). Considering a white-box scenario and real datasets, we demonstrate that our proposed techniques outperform existing state-of-the-art technologies.
Read more7/10/2024
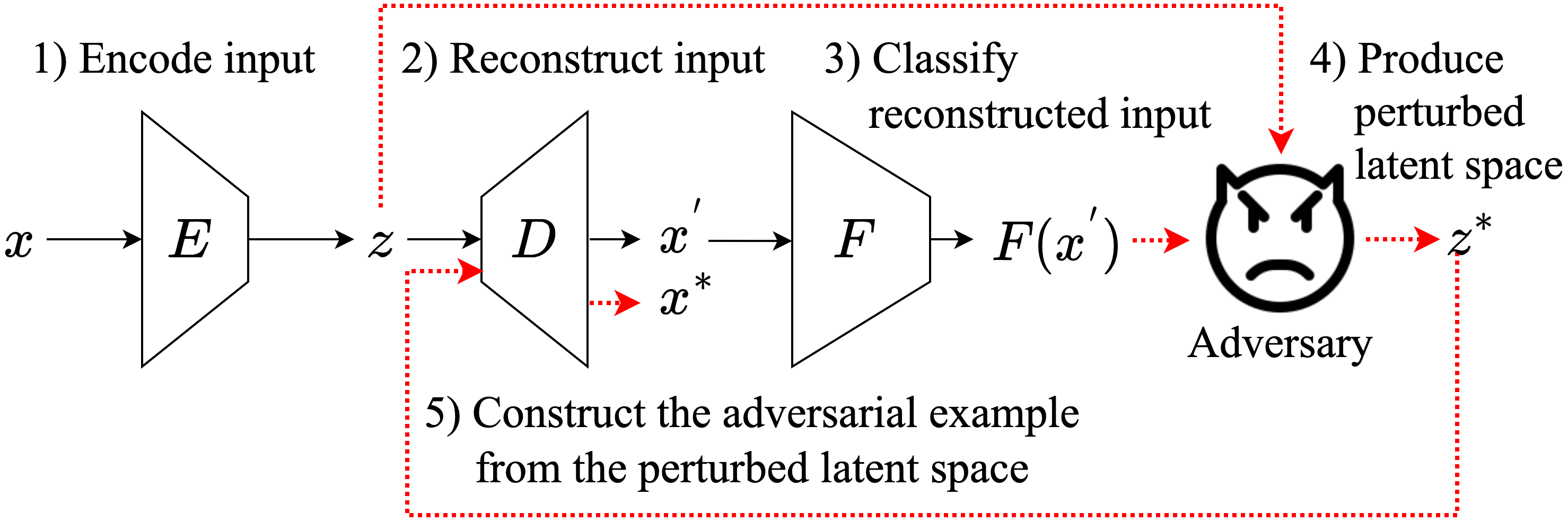
0
On Adversarial Examples for Text Classification by Perturbing Latent Representations
Korn Sooksatra, Bikram Khanal, Pablo Rivas
Recently, with the advancement of deep learning, several applications in text classification have advanced significantly. However, this improvement comes with a cost because deep learning is vulnerable to adversarial examples. This weakness indicates that deep learning is not very robust. Fortunately, the input of a text classifier is discrete. Hence, it can prevent the classifier from state-of-the-art attacks. Nonetheless, previous works have generated black-box attacks that successfully manipulate the discrete values of the input to find adversarial examples. Therefore, instead of changing the discrete values, we transform the input into its embedding vector containing real values to perform the state-of-the-art white-box attacks. Then, we convert the perturbed embedding vector back into a text and name it an adversarial example. In summary, we create a framework that measures the robustness of a text classifier by using the gradients of the classifier.
Read more5/8/2024
🎲
0
How adversarial attacks can disrupt seemingly stable accurate classifiers
Oliver J. Sutton, Qinghua Zhou, Ivan Y. Tyukin, Alexander N. Gorban, Alexander Bastounis, Desmond J. Higham
Adversarial attacks dramatically change the output of an otherwise accurate learning system using a seemingly inconsequential modification to a piece of input data. Paradoxically, empirical evidence indicates that even systems which are robust to large random perturbations of the input data remain susceptible to small, easily constructed, adversarial perturbations of their inputs. Here, we show that this may be seen as a fundamental feature of classifiers working with high dimensional input data. We introduce a simple generic and generalisable framework for which key behaviours observed in practical systems arise with high probability -- notably the simultaneous susceptibility of the (otherwise accurate) model to easily constructed adversarial attacks, and robustness to random perturbations of the input data. We confirm that the same phenomena are directly observed in practical neural networks trained on standard image classification problems, where even large additive random noise fails to trigger the adversarial instability of the network. A surprising takeaway is that even small margins separating a classifier's decision surface from training and testing data can hide adversarial susceptibility from being detected using randomly sampled perturbations. Counterintuitively, using additive noise during training or testing is therefore inefficient for eradicating or detecting adversarial examples, and more demanding adversarial training is required.
Read more9/10/2024