How adversarial attacks can disrupt seemingly stable accurate classifiers

0
🎲
Sign in to get full access
Overview
- Adversarial attacks can dramatically change the output of an otherwise accurate learning system with a seemingly small modification to the input data.
- Paradoxically, systems that are robust to large random perturbations can still be susceptible to small, easily constructed adversarial perturbations.
- This paper introduces a simple framework that explains this phenomenon as a fundamental feature of classifiers working with high-dimensional input data.
Plain English Explanation
Even the most accurate machine learning models can be fooled by adversarial attacks. These are small, intentional changes to the input data that cause the model to output completely different results. The surprising part is that these models are often robust to large, random changes to the input, but can still be easily tricked by carefully crafted adversarial perturbations.
This paper proposes a simple framework that explains why this phenomenon occurs. The key idea is that even small "margins" or gaps between a classifier's decision boundaries and the training/testing data can hide the system's susceptibility to adversarial attacks. In other words, the model may appear to work well on normal data, but have hidden vulnerabilities that are only exposed by these carefully designed adversarial examples.
The paper shows that using random noise during training or testing is not an effective way to detect or eliminate these adversarial vulnerabilities. More demanding "adversarial training" is required to truly make the models robust.
Technical Explanation
The paper introduces a simple theoretical framework to explain the simultaneous robustness to random perturbations and susceptibility to adversarial attacks observed in practical neural network classifiers.
The key insight is that even a small margin separating a classifier's decision surface from the training and testing data can hide the system's adversarial vulnerability. This means the model may perform well on normal data, but still have hidden weaknesses that can be exposed by carefully crafted adversarial examples.
The paper confirms that this phenomenon is directly observed in practical neural networks trained on standard image classification tasks. Even large amounts of additive random noise fail to trigger the network's adversarial instability, while small adversarial perturbations can drastically change the output.
The key takeaway is that using random noise during training or testing is an inefficient way to detect or eliminate adversarial vulnerabilities. More demanding adversarial training is required to truly make models robust to these types of attacks.
Critical Analysis
The paper provides a compelling theoretical framework to explain the paradoxical behavior of neural network classifiers - their robustness to random perturbations yet susceptibility to adversarial attacks. The simplicity and generalizability of the proposed model are strengths, as they suggest these phenomena may indeed be fundamental features of high-dimensional classifiers.
However, the paper does not explore the practical limitations or potential issues with this approach. For example, the framework assumes an idealized setting, and it's unclear how well it translates to real-world, higher-complexity neural networks. Additionally, the paper does not discuss potential countermeasures beyond adversarial training, which may have its own limitations and challenges.
Further research is needed to fully understand the implications and broader applicability of these insights. Investigating the role of network architecture, training data, and other factors in the emergence of adversarial vulnerabilities could yield important insights and more effective defense strategies.
Conclusion
This paper presents a simple theoretical framework that explains the paradoxical behavior of neural network classifiers - their robustness to random perturbations yet susceptibility to adversarial attacks. The key insight is that even small margins between a classifier's decision boundaries and the training/testing data can hide underlying adversarial vulnerabilities.
The implications of this research are significant, as it suggests that traditional techniques like random noise addition may not be effective in detecting or eliminating adversarial examples. Instead, more demanding adversarial training is required to truly make models robust to these types of attacks.
While the proposed framework is elegant and generalizable, further research is needed to fully understand its practical limitations and explore additional countermeasures. Nonetheless, this work provides important insights into the fundamental nature of adversarial vulnerabilities in high-dimensional classifiers, paving the way for more effective defenses against these dangerous attacks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
0
How adversarial attacks can disrupt seemingly stable accurate classifiers
Oliver J. Sutton, Qinghua Zhou, Ivan Y. Tyukin, Alexander N. Gorban, Alexander Bastounis, Desmond J. Higham
Adversarial attacks dramatically change the output of an otherwise accurate learning system using a seemingly inconsequential modification to a piece of input data. Paradoxically, empirical evidence indicates that even systems which are robust to large random perturbations of the input data remain susceptible to small, easily constructed, adversarial perturbations of their inputs. Here, we show that this may be seen as a fundamental feature of classifiers working with high dimensional input data. We introduce a simple generic and generalisable framework for which key behaviours observed in practical systems arise with high probability -- notably the simultaneous susceptibility of the (otherwise accurate) model to easily constructed adversarial attacks, and robustness to random perturbations of the input data. We confirm that the same phenomena are directly observed in practical neural networks trained on standard image classification problems, where even large additive random noise fails to trigger the adversarial instability of the network. A surprising takeaway is that even small margins separating a classifier's decision surface from training and testing data can hide adversarial susceptibility from being detected using randomly sampled perturbations. Counterintuitively, using additive noise during training or testing is therefore inefficient for eradicating or detecting adversarial examples, and more demanding adversarial training is required.
Read more9/10/2024
0
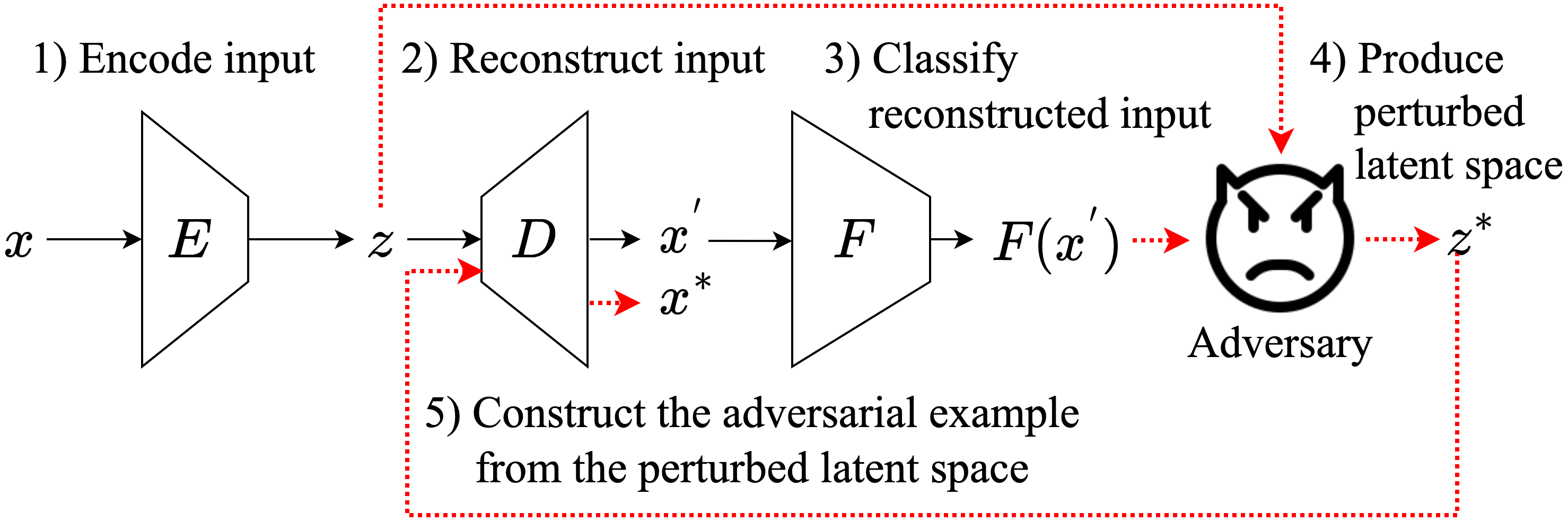
On Adversarial Examples for Text Classification by Perturbing Latent Representations
Korn Sooksatra, Bikram Khanal, Pablo Rivas
Recently, with the advancement of deep learning, several applications in text classification have advanced significantly. However, this improvement comes with a cost because deep learning is vulnerable to adversarial examples. This weakness indicates that deep learning is not very robust. Fortunately, the input of a text classifier is discrete. Hence, it can prevent the classifier from state-of-the-art attacks. Nonetheless, previous works have generated black-box attacks that successfully manipulate the discrete values of the input to find adversarial examples. Therefore, instead of changing the discrete values, we transform the input into its embedding vector containing real values to perform the state-of-the-art white-box attacks. Then, we convert the perturbed embedding vector back into a text and name it an adversarial example. In summary, we create a framework that measures the robustness of a text classifier by using the gradients of the classifier.
Read more5/8/2024

0
Adversarial Attacks and Dimensionality in Text Classifiers
Nandish Chattopadhyay, Atreya Goswami, Anupam Chattopadhyay
Adversarial attacks on machine learning algorithms have been a key deterrent to the adoption of AI in many real-world use cases. They significantly undermine the ability of high-performance neural networks by forcing misclassifications. These attacks introduce minute and structured perturbations or alterations in the test samples, imperceptible to human annotators in general, but trained neural networks and other models are sensitive to it. Historically, adversarial attacks have been first identified and studied in the domain of image processing. In this paper, we study adversarial examples in the field of natural language processing, specifically text classification tasks. We investigate the reasons for adversarial vulnerability, particularly in relation to the inherent dimensionality of the model. Our key finding is that there is a very strong correlation between the embedding dimensionality of the adversarial samples and their effectiveness on models tuned with input samples with same embedding dimension. We utilize this sensitivity to design an adversarial defense mechanism. We use ensemble models of varying inherent dimensionality to thwart the attacks. This is tested on multiple datasets for its efficacy in providing robustness. We also study the problem of measuring adversarial perturbation using different distance metrics. For all of the aforementioned studies, we have run tests on multiple models with varying dimensionality and used a word-vector level adversarial attack to substantiate the findings.
Read more4/4/2024
0
Towards unlocking the mystery of adversarial fragility of neural networks
Jingchao Gao, Raghu Mudumbai, Xiaodong Wu, Jirong Yi, Catherine Xu, Hui Xie, Weiyu Xu
In this paper, we study the adversarial robustness of deep neural networks for classification tasks. We look at the smallest magnitude of possible additive perturbations that can change the output of a classification algorithm. We provide a matrix-theoretic explanation of the adversarial fragility of deep neural network for classification. In particular, our theoretical results show that neural network's adversarial robustness can degrade as the input dimension $d$ increases. Analytically we show that neural networks' adversarial robustness can be only $1/sqrt{d}$ of the best possible adversarial robustness. Our matrix-theoretic explanation is consistent with an earlier information-theoretic feature-compression-based explanation for the adversarial fragility of neural networks.
Read more6/26/2024