Coupling Speech Encoders with Downstream Text Models

0
Sign in to get full access
Overview
- This paper explores ways to effectively combine speech encoders with downstream text models.
- The authors propose several strategies for coupling these models to improve speech-to-text and other language-based tasks.
- Key findings include the benefits of joint training, using speech representations as input to text models, and leveraging model distillation techniques.
Plain English Explanation
The paper discusses how to effectively connect speech recognition models, which turn audio into text, with natural language processing models, which can perform various language-based tasks. The researchers investigate different approaches to integrate these two types of models and explore the potential benefits.
One key idea is joint training, where the speech and text models are trained together on relevant data. This allows the models to learn from each other and potentially perform better on downstream tasks like speech-to-text translation.
Another approach is to use the speech representations - the internal features extracted by the speech model - as input to the text model. This can help the text model better understand the original audio information.
The authors also explore model distillation, a technique where a smaller, more efficient text model is trained to mimic the behavior of a larger, more complex model. This can result in a text model that maintains good performance while being faster and more lightweight.
Overall, the paper provides insights into how to effectively couple speech and text models to improve a variety of language-based applications, from speech recognition to language understanding.
Technical Explanation
The paper investigates different strategies for coupling speech encoders with downstream text models. The authors explore three main approaches:
-
Joint Training: The speech encoder and text model are trained together on relevant data, allowing the models to learn from each other and potentially improve performance on tasks like speech-to-text translation.
-
Using Speech Representations: The internal features extracted by the speech encoder are used as input to the text model, rather than just the final text output. This can help the text model better leverage the original audio information.
-
Model Distillation: A smaller, more efficient text model is trained to mimic the behavior of a larger, more complex model. This can result in a text model that maintains good performance while being faster and more lightweight.
The authors evaluate these approaches on a variety of speech-to-text and language understanding tasks, demonstrating the benefits of these coupling strategies. For example, they show that joint training can lead to improvements in speech recognition accuracy, while using speech representations can enhance text model performance on downstream tasks.
Critical Analysis
The paper provides a comprehensive exploration of different techniques for coupling speech encoders and text models. However, the authors acknowledge several limitations and areas for further research:
- The experiments are conducted on relatively constrained datasets, and the authors suggest evaluating the approaches on more diverse and large-scale datasets.
- The specific architectures and hyperparameters used for the speech encoders and text models are not always clearly specified, making it difficult to fully reproduce the results.
- The paper does not delve into the trade-offs between model complexity, performance, and efficiency, which would be valuable for practical applications.
Additionally, one could argue that the paper focuses primarily on technical aspects and does not provide a deeper discussion of the broader implications and potential societal impact of these coupling strategies. For example, the use of speech-to-text models in sensitive domains like healthcare or finance could raise ethical concerns around privacy and bias that deserve further consideration.
Conclusion
This paper presents a comprehensive exploration of techniques for effectively coupling speech encoders with downstream text models. The authors demonstrate the benefits of joint training, using speech representations as input to text models, and leveraging model distillation. These strategies can lead to improvements in speech-to-text translation, language understanding, and other language-based applications.
The findings in this paper contribute to the ongoing efforts to bridge the gap between speech and language processing, which is crucial for developing more natural and intuitive human-computer interaction systems. As the authors suggest, further research on larger and more diverse datasets, as well as deeper consideration of the practical and ethical implications, could further advance this important area of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Coupling Speech Encoders with Downstream Text Models
Ciprian Chelba, Johan Schalkwyk
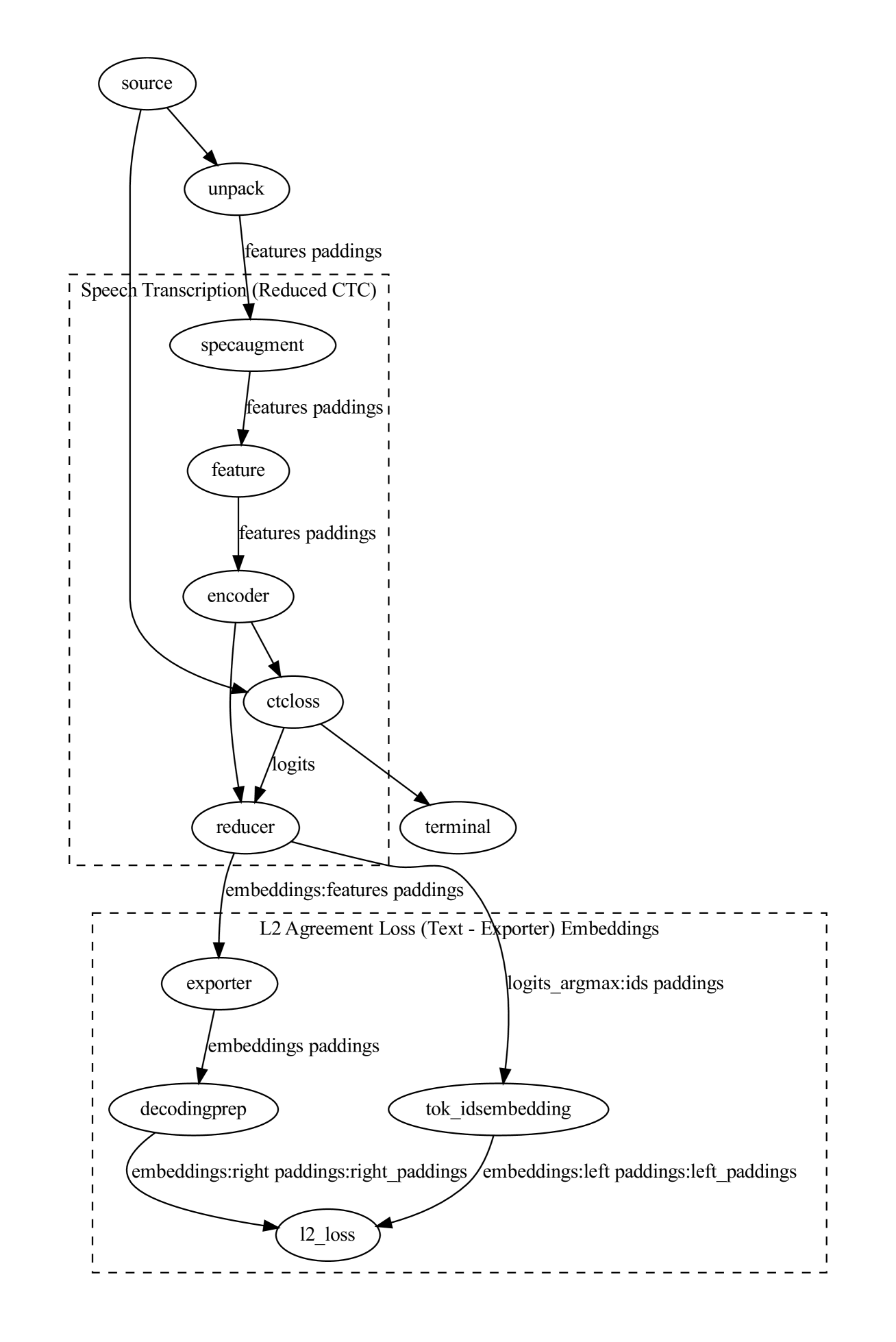
We present a modular approach to building cascade speech translation (AST) models that guarantees that the resulting model performs no worse than the 1-best cascade baseline while preserving state-of-the-art speech recognition (ASR) and text translation (MT) performance for a given task. Our novel contribution is the use of an ``exporter'' layer that is trained under L2-loss to ensure a strong match between ASR embeddings and the MT token embeddings for the 1-best sequence. The ``exporter'' output embeddings are fed directly to the MT model in lieu of 1-best token embeddings, thus guaranteeing that the resulting model performs no worse than the 1-best cascade baseline, while allowing back-propagation gradient to flow from the MT model into the ASR components. The matched-embeddings cascade architecture provide a significant improvement over its 1-best counterpart in scenarios where incremental training of the MT model is not an option and yet we seek to improve quality by leveraging (speech, transcription, translated transcription) data provided with the AST task. The gain disappears when the MT model is incrementally trained on the parallel text data available with the AST task. The approach holds promise for other scenarios that seek to couple ASR encoders and immutable text models, such at large language models (LLM).
Read more7/26/2024

0
Cascaded Cross-Modal Transformer for Audio-Textual Classification
Nicolae-Catalin Ristea, Andrei Anghel, Radu Tudor Ionescu
Speech classification tasks often require powerful language understanding models to grasp useful features, which becomes problematic when limited training data is available. To attain superior classification performance, we propose to harness the inherent value of multimodal representations by transcribing speech using automatic speech recognition (ASR) models and translating the transcripts into different languages via pretrained translation models. We thus obtain an audio-textual (multimodal) representation for each data sample. Subsequently, we combine language-specific Bidirectional Encoder Representations from Transformers (BERT) with Wav2Vec2.0 audio features via a novel cascaded cross-modal transformer (CCMT). Our model is based on two cascaded transformer blocks. The first one combines text-specific features from distinct languages, while the second one combines acoustic features with multilingual features previously learned by the first transformer block. We employed our system in the Requests Sub-Challenge of the ACM Multimedia 2023 Computational Paralinguistics Challenge. CCMT was declared the winning solution, obtaining an unweighted average recall (UAR) of 65.41% and 85.87% for complaint and request detection, respectively. Moreover, we applied our framework on the Speech Commands v2 and HarperValleyBank dialog data sets, surpassing previous studies reporting results on these benchmarks. Our code is freely available for download at: https://github.com/ristea/ccmt.
Read more7/26/2024

0
Blending LLMs into Cascaded Speech Translation: KIT's Offline Speech Translation System for IWSLT 2024
Sai Koneru, Thai-Binh Nguyen, Ngoc-Quan Pham, Danni Liu, Zhaolin Li, Alexander Waibel, Jan Niehues
Large Language Models (LLMs) are currently under exploration for various tasks, including Automatic Speech Recognition (ASR), Machine Translation (MT), and even End-to-End Speech Translation (ST). In this paper, we present KIT's offline submission in the constrained + LLM track by incorporating recently proposed techniques that can be added to any cascaded speech translation. Specifically, we integrate Mistral-7Bfootnote{mistralai/Mistral-7B-Instruct-v0.1} into our system to enhance it in two ways. Firstly, we refine the ASR outputs by utilizing the N-best lists generated by our system and fine-tuning the LLM to predict the transcript accurately. Secondly, we refine the MT outputs at the document level by fine-tuning the LLM, leveraging both ASR and MT predictions to improve translation quality. We find that integrating the LLM into the ASR and MT systems results in an absolute improvement of $0.3%$ in Word Error Rate and $0.65%$ in COMET for tst2019 test set. In challenging test sets with overlapping speakers and background noise, we find that integrating LLM is not beneficial due to poor ASR performance. Here, we use ASR with chunked long-form decoding to improve context usage that may be unavailable when transcribing with Voice Activity Detection segmentation alone.
Read more6/26/2024
0
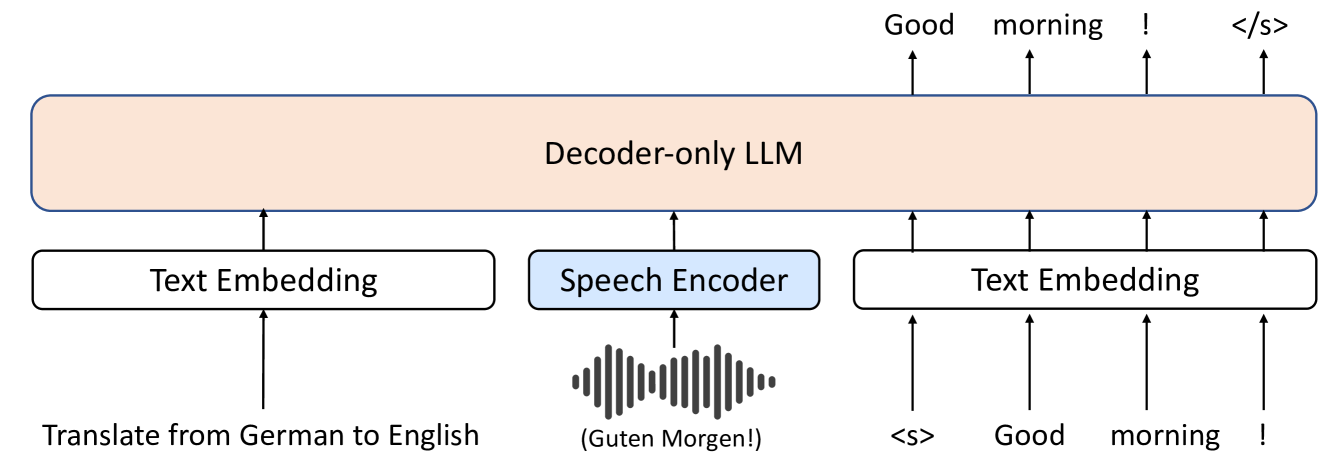
Investigating Decoder-only Large Language Models for Speech-to-text Translation
Chao-Wei Huang, Hui Lu, Hongyu Gong, Hirofumi Inaguma, Ilia Kulikov, Ruslan Mavlyutov, Sravya Popuri
Large language models (LLMs), known for their exceptional reasoning capabilities, generalizability, and fluency across diverse domains, present a promising avenue for enhancing speech-related tasks. In this paper, we focus on integrating decoder-only LLMs to the task of speech-to-text translation (S2TT). We propose a decoder-only architecture that enables the LLM to directly consume the encoded speech representation and generate the text translation. Additionally, we investigate the effects of different parameter-efficient fine-tuning techniques and task formulation. Our model achieves state-of-the-art performance on CoVoST 2 and FLEURS among models trained without proprietary data. We also conduct analyses to validate the design choices of our proposed model and bring insights to the integration of LLMs to S2TT.
Read more7/4/2024