Investigating Decoder-only Large Language Models for Speech-to-text Translation

0
Sign in to get full access
Overview
- This paper investigates the use of decoder-only large language models (LLMs) for speech-to-text translation tasks.
- The researchers explore whether LLMs trained solely on text data, without any explicit speech or translation training, can effectively perform speech-to-text translation.
- The findings have implications for the development of more efficient and accessible speech translation systems.
Plain English Explanation
The paper looks at using large language models (LLMs) - powerful AI models trained on vast amounts of text data - to translate speech into text. Typically, speech translation systems require models trained on both speech and translation data. However, the researchers wanted to see if LLMs, which are only trained on text, could still perform this task effectively.
The idea is that LLMs may be able to leverage their general language understanding capabilities to translate speech, without the need for specialized speech-focused training. This could make speech translation systems simpler and more accessible to develop. The researchers conducted experiments to test this hypothesis and examine the performance of decoder-only LLMs on speech-to-text translation.
Technical Explanation
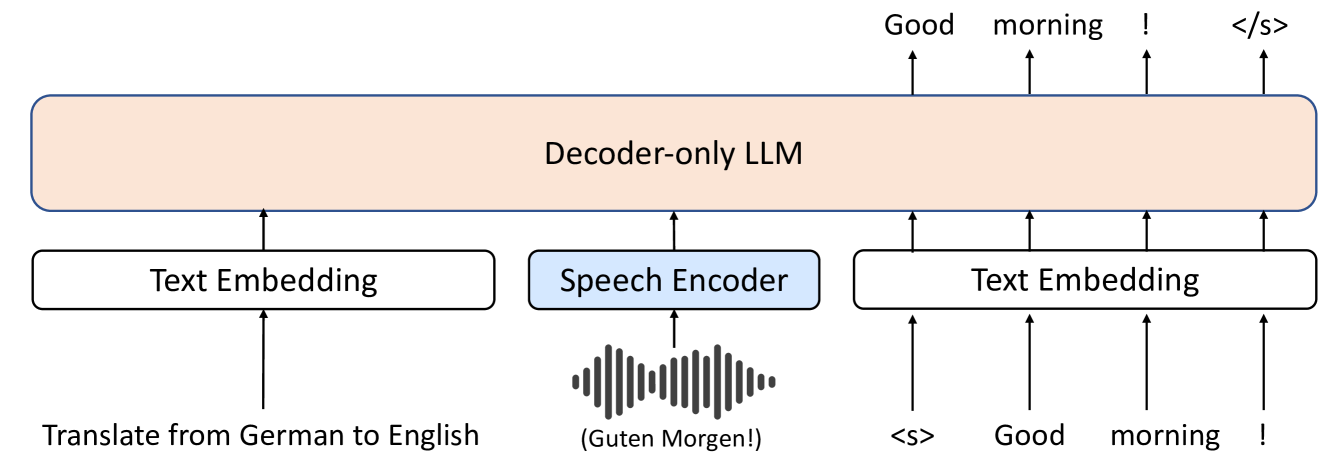
The paper explores the use of decoder-only large language models for speech-to-text translation. Unlike typical speech translation models, which require training on both speech and translation data, the researchers investigate whether LLMs trained solely on text data can effectively perform this task.
The key idea is that LLMs may be able to leverage their powerful language understanding capabilities to translate speech into text, without the need for explicit speech-focused training. This could lead to more efficient and accessible speech translation systems.
The researchers conduct experiments to evaluate the performance of decoder-only LLMs on speech-to-text translation tasks, comparing their results to traditional speech translation models. They also investigate the impact of various factors, such as the size and architecture of the LLMs, on the translation quality.
Critical Analysis
The paper presents a novel approach to speech-to-text translation by leveraging the capabilities of decoder-only LLMs. However, the researchers acknowledge that their findings may be limited by the specific datasets and models used in the experiments. Further research is needed to fully understand the potential and limitations of this approach.
One potential concern is the ability of these LLMs to handle complex or noisy speech input, which may require additional specialized training or preprocessing. The paper also does not explore the impact of language diversity or multilingual capabilities on the translation performance.
Overall, the research provides an interesting and promising direction for speech translation, but more comprehensive evaluation and further development are necessary to assess the practical viability of this approach in real-world applications.
Conclusion
This paper investigates the use of decoder-only large language models (LLMs) for speech-to-text translation. The key finding is that LLMs, trained solely on text data, can potentially perform speech translation tasks effectively, without the need for specialized speech-focused training.
This approach could lead to more efficient and accessible speech translation systems, as LLMs can leverage their general language understanding capabilities. The researchers present experimental results and discuss the implications of their findings, as well as potential areas for further research.
Overall, the paper offers a novel perspective on speech-to-text translation and suggests that LLMs may be a valuable tool for developing more efficient and widely available speech translation solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Investigating Decoder-only Large Language Models for Speech-to-text Translation
Chao-Wei Huang, Hui Lu, Hongyu Gong, Hirofumi Inaguma, Ilia Kulikov, Ruslan Mavlyutov, Sravya Popuri
Large language models (LLMs), known for their exceptional reasoning capabilities, generalizability, and fluency across diverse domains, present a promising avenue for enhancing speech-related tasks. In this paper, we focus on integrating decoder-only LLMs to the task of speech-to-text translation (S2TT). We propose a decoder-only architecture that enables the LLM to directly consume the encoded speech representation and generate the text translation. Additionally, we investigate the effects of different parameter-efficient fine-tuning techniques and task formulation. Our model achieves state-of-the-art performance on CoVoST 2 and FLEURS among models trained without proprietary data. We also conduct analyses to validate the design choices of our proposed model and bring insights to the integration of LLMs to S2TT.
Read more7/4/2024

0
Machine Translation with Large Language Models: Decoder Only vs. Encoder-Decoder
Abhinav P. M., SujayKumar Reddy M, Oswald Christopher
This project, titled Machine Translation with Large Language Models: Decoder-only vs. Encoder-Decoder, aims to develop a multilingual machine translation (MT) model. Focused on Indian regional languages, especially Telugu, Tamil, and Malayalam, the model seeks to enable accurate and contextually appropriate translations across diverse language pairs. By comparing Decoder-only and Encoder-Decoder architectures, the project aims to optimize translation quality and efficiency, advancing cross-linguistic communication tools.The primary objective is to develop a model capable of delivering high-quality translations that are accurate and contextually appropriate. By leveraging large language models, specifically comparing the effectiveness of Decoder-only and Encoder-Decoder architectures, the project seeks to optimize translation performance and efficiency across multilingual contexts. Through rigorous experimentation and analysis, this project aims to advance the field of machine translation, contributing valuable insights into the effectiveness of different model architectures and paving the way for enhanced cross-linguistic communication tools.
Read more9/24/2024

0
Decoder-only Architecture for Streaming End-to-end Speech Recognition
Emiru Tsunoo, Hayato Futami, Yosuke Kashiwagi, Siddhant Arora, Shinji Watanabe
Decoder-only language models (LMs) have been successfully adopted for speech-processing tasks including automatic speech recognition (ASR). The LMs have ample expressiveness and perform efficiently. This efficiency is a suitable characteristic for streaming applications of ASR. In this work, we propose to use a decoder-only architecture for blockwise streaming ASR. In our approach, speech features are compressed using CTC output and context embedding using blockwise speech subnetwork, and are sequentially provided as prompts to the decoder. The decoder estimates the output tokens promptly at each block. To this end, we also propose a novel training scheme using random-length prefix prompts to make the model robust to the truncated prompts caused by blockwise processing. An experimental comparison shows that our proposed decoder-only streaming ASR achieves 8% relative word error rate reduction in the LibriSpeech test-other set while being twice as fast as the baseline model.
Read more8/2/2024

0
Think Big, Generate Quick: LLM-to-SLM for Fast Autoregressive Decoding
Benjamin Bergner, Andrii Skliar, Amelie Royer, Tijmen Blankevoort, Yuki Asano, Babak Ehteshami Bejnordi
Large language models (LLMs) have become ubiquitous in practice and are widely used for generation tasks such as translation, summarization and instruction following. However, their enormous size and reliance on autoregressive decoding increase deployment costs and complicate their use in latency-critical applications. In this work, we propose a hybrid approach that combines language models of different sizes to increase the efficiency of autoregressive decoding while maintaining high performance. Our method utilizes a pretrained frozen LLM that encodes all prompt tokens once in parallel, and uses the resulting representations to condition and guide a small language model (SLM), which then generates the response more efficiently. We investigate the combination of encoder-decoder LLMs with both encoder-decoder and decoder-only SLMs from different model families and only require fine-tuning of the SLM. Experiments with various benchmarks show substantial speedups of up to $4times$, with minor performance penalties of $1-2%$ for translation and summarization tasks compared to the LLM.
Read more7/18/2024