Course-Correction: Safety Alignment Using Synthetic Preferences

0

Sign in to get full access
Overview
- This paper explores a technique called "Course-Correction" to improve the safety and alignment of AI systems using "synthetic preferences".
- The authors propose a method to train AI models to behave in ways that are more closely aligned with human values and preferences, even when those preferences are not fully specified.
- The paper includes examples of text that may be considered unsafe, offensive, or upsetting.
Plain English Explanation
As AI systems become more advanced and powerful, it's crucial that they behave in ways that are aligned with human values and preferences. The authors of this paper explore a technique called "Course-Correction" to help achieve this goal.
The key idea behind Course-Correction is to train AI models not just on the desired behaviors, but also on "synthetic preferences" - artificial preferences that are designed to capture important aspects of human values that may not be fully specified. By doing this, the AI system can learn to behave in ways that are more closely aligned with what humans actually want, even in situations where the preferences are complex or ambiguous.
For example, imagine an AI assistant that is tasked with helping a human with their daily tasks. The assistant might be trained on a set of specific instructions, like "make coffee", "schedule a meeting", etc. But there are many other aspects of human values and preferences that are harder to capture, like the importance of being polite, respecting privacy, or avoiding harm. By incorporating synthetic preferences into the training process, the AI system can learn to behave in ways that better reflect these broader human values.
The authors acknowledge that their approach includes examples of text that may be considered unsafe, offensive, or upsetting. This is because they are exploring the boundaries of what is acceptable, in order to push the limits of safety and alignment in AI systems. By including these challenging examples, they hope to develop techniques that can handle a wide range of situations and preferences, even those that are difficult or controversial.
Technical Explanation
The course-correction approach proposed in this paper involves training AI models on both the desired behaviors (e.g., completing tasks) as well as "synthetic preferences" that capture important aspects of human values. These synthetic preferences are designed to influence the AI's decision-making process and push it towards more aligned and safe behaviors.
The authors describe a few key components of their approach:
- Preference Learning: The AI model is trained to predict human preferences, even in situations where those preferences are complex or ambiguous.
- Reward Modeling: The model is also trained to estimate the reward (or value) of different actions, based on the predicted preferences.
- Course-Correction: During deployment, the AI system continuously monitors its own behavior and "corrects" its actions if they deviate too far from the predicted preferences and reward estimates.
The experimental results presented in the paper demonstrate that this course-correction approach can lead to more aligned and safe behavior in AI systems, even in the face of challenging or controversial situations.
Critical Analysis
The authors acknowledge that their approach includes examples of text that may be considered unsafe, offensive, or upsetting. This is a necessary part of their research, as they are exploring the boundaries of what is acceptable in order to develop more robust and comprehensive safety mechanisms for AI systems.
One potential limitation of the course-correction approach is that it relies heavily on the accuracy of the preference learning and reward modeling components. If these components are not sufficiently accurate or comprehensive, the AI system may still make suboptimal or unsafe decisions, despite the course-correction mechanism.
Additionally, the authors note that their approach may be vulnerable to adversarial attacks, where an adversary tries to manipulate the AI system's behavior by exploiting weaknesses in the preference learning or reward modeling components. Further research may be needed to address these potential vulnerabilities.
Overall, the course-correction approach presented in this paper represents an important step forward in the field of AI safety and alignment. By incorporating synthetic preferences into the training process, the authors have demonstrated a promising technique for developing AI systems that are more closely aligned with human values and preferences.
Conclusion
The course-correction technique proposed in this paper offers a novel approach to improving the safety and alignment of AI systems. By training models not just on desired behaviors, but also on synthetic preferences that capture important aspects of human values, the authors have developed a method that can help push AI systems towards more aligned and safe behavior, even in challenging or controversial situations.
While the paper acknowledges that its approach includes examples that may be considered unsafe or offensive, this is a necessary part of the research process. By exploring the boundaries of what is acceptable, the authors hope to develop more robust and comprehensive safety mechanisms for AI systems, which could have far-reaching implications for the future of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Course-Correction: Safety Alignment Using Synthetic Preferences
Rongwu Xu, Yishuo Cai, Zhenhong Zhou, Renjie Gu, Haiqin Weng, Yan Liu, Tianwei Zhang, Wei Xu, Han Qiu
The risk of harmful content generated by large language models (LLMs) becomes a critical concern. This paper presents a systematic study on assessing and improving LLMs' capability to perform the task of textbf{course-correction}, ie, the model can steer away from generating harmful content autonomously. To start with, we introduce the textsc{C$^2$-Eval} benchmark for quantitative assessment and analyze 10 popular LLMs, revealing varying proficiency of current safety-tuned LLMs in course-correction. To improve, we propose fine-tuning LLMs with preference learning, emphasizing the preference for timely course-correction. Using an automated pipeline, we create textsc{C$^2$-Syn}, a synthetic dataset with 750K pairwise preferences, to teach models the concept of timely course-correction through data-driven preference learning. Experiments on 2 LLMs, textsc{Llama2-Chat 7B} and textsc{Qwen2 7B}, show that our method effectively enhances course-correction skills without affecting general performance. Additionally, it effectively improves LLMs' safety, particularly in resisting jailbreak attacks.
Read more7/24/2024
0
A Framework for Real-time Safeguarding the Text Generation of Large Language
Ximing Dong, Dayi Lin, Shaowei Wang, Ahmed E. Hassan
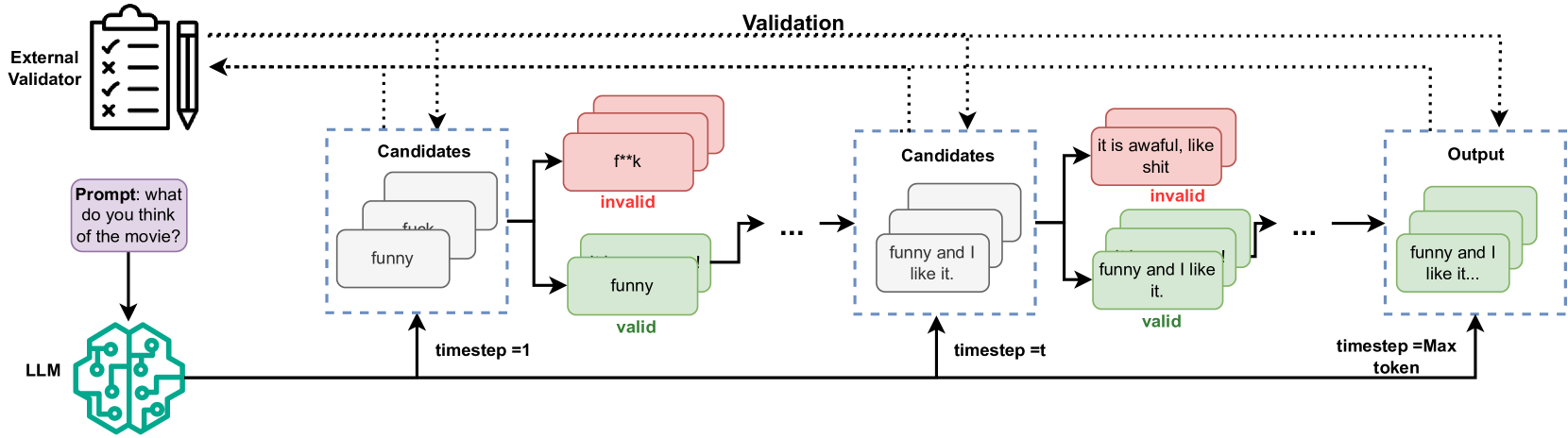
Large Language Models (LLMs) have significantly advanced natural language processing (NLP) tasks but also pose ethical and societal risks due to their propensity to generate harmful content. To address this, various approaches have been developed to safeguard LLMs from producing unsafe content. However, existing methods have limitations, including the need for training specific control models and proactive intervention during text generation, that lead to quality degradation and increased computational overhead. To mitigate those limitations, we propose LLMSafeGuard, a lightweight framework to safeguard LLM text generation in real-time. LLMSafeGuard integrates an external validator into the beam search algorithm during decoding, rejecting candidates that violate safety constraints while allowing valid ones to proceed. We introduce a similarity based validation approach, simplifying constraint introduction and eliminating the need for control model training. Additionally, LLMSafeGuard employs a context-wise timing selection strategy, intervening LLMs only when necessary. We evaluate LLMSafeGuard on two tasks, detoxification and copyright safeguarding, and demonstrate its superior performance over SOTA baselines. For instance, LLMSafeGuard reduces the average toxic score of. LLM output by 29.7% compared to the best baseline meanwhile preserving similar linguistic quality as natural output in detoxification task. Similarly, in the copyright task, LLMSafeGuard decreases the Longest Common Subsequence (LCS) by 56.2% compared to baselines. Moreover, our context-wise timing selection strategy reduces inference time by at least 24% meanwhile maintaining comparable effectiveness as validating each time step. LLMSafeGuard also offers tunable parameters to balance its effectiveness and efficiency.
Read more5/3/2024

0
Robustifying Safety-Aligned Large Language Models through Clean Data Curation
Xiaoqun Liu, Jiacheng Liang, Muchao Ye, Zhaohan Xi
Large language models (LLMs) are vulnerable when trained on datasets containing harmful content, which leads to potential jailbreaking attacks in two scenarios: the integration of harmful texts within crowdsourced data used for pre-training and direct tampering with LLMs through fine-tuning. In both scenarios, adversaries can compromise the safety alignment of LLMs, exacerbating malfunctions. Motivated by the need to mitigate these adversarial influences, our research aims to enhance safety alignment by either neutralizing the impact of malicious texts in pre-training datasets or increasing the difficulty of jailbreaking during downstream fine-tuning. In this paper, we propose a data curation framework designed to counter adversarial impacts in both scenarios. Our method operates under the assumption that we have no prior knowledge of attack details, focusing solely on curating clean texts. We introduce an iterative process aimed at revising texts to reduce their perplexity as perceived by LLMs, while simultaneously preserving their text quality. By pre-training or fine-tuning LLMs with curated clean texts, we observe a notable improvement in LLM robustness regarding safety alignment against harmful queries. For instance, when pre-training LLMs using a crowdsourced dataset containing 5% harmful instances, adding an equivalent amount of curated texts significantly mitigates the likelihood of providing harmful responses in LLMs and reduces the attack success rate by 71%. Our study represents a significant step towards mitigating the risks associated with training-based jailbreaking and fortifying the secure utilization of LLMs.
Read more6/3/2024

0
Multitask Mayhem: Unveiling and Mitigating Safety Gaps in LLMs Fine-tuning
Essa Jan, Nouar AlDahoul, Moiz Ali, Faizan Ahmad, Fareed Zaffar, Yasir Zaki
Recent breakthroughs in Large Language Models (LLMs) have led to their adoption across a wide range of tasks, ranging from code generation to machine translation and sentiment analysis, etc. Red teaming/Safety alignment efforts show that fine-tuning models on benign (non-harmful) data could compromise safety. However, it remains unclear to what extent this phenomenon is influenced by different variables, including fine-tuning task, model calibrations, etc. This paper explores the task-wise safety degradation due to fine-tuning on downstream tasks such as summarization, code generation, translation, and classification across various calibration. Our results reveal that: 1) Fine-tuning LLMs for code generation and translation leads to the highest degradation in safety guardrails. 2) LLMs generally have weaker guardrails for translation and classification, with 73-92% of harmful prompts answered, across baseline and other calibrations, falling into one of two concern categories. 3) Current solutions, including guards and safety tuning datasets, lack cross-task robustness. To address these issues, we developed a new multitask safety dataset effectively reducing attack success rates across a range of tasks without compromising the model's overall helpfulness. Our work underscores the need for generalized alignment measures to ensure safer and more robust models.
Read more9/25/2024