Robustifying Safety-Aligned Large Language Models through Clean Data Curation

0

Sign in to get full access
Overview
- This paper presents a method for "robustifying" safety-aligned large language models (LLMs) through clean data curation.
- The researchers aim to improve the safety and robustness of LLMs by carefully curating the training data to remove harmful content.
- This builds on prior work on safeguarding text generation, defending against jailbreak attacks, and other AI safety techniques.
Plain English Explanation
The paper focuses on making large language models (LLMs) - powerful AI systems that can generate human-like text - more safe and reliable. These LLMs are trained on huge datasets of online text, which can sometimes contain harmful or biased information. The researchers propose a method to "clean up" the training data, removing content that could lead the LLM to say or do undesirable things.
By carefully curating the training data, the goal is to produce LLMs that are more robustly aligned with important human values and safety considerations. This builds on previous work on techniques like content defense and comprehensive assessment to make LLMs more trustworthy and aligned with human interests.
The key idea is that by starting with cleaner training data, the LLM will learn patterns and behaviors that are more inherently safe and beneficial, rather than having to be "patched" or "fine-tuned" later on. This proactive approach to AI safety could lead to more reliably safe and helpful language models in the long run.
Technical Explanation
The paper describes a data curation pipeline that aims to remove harmful, biased, or otherwise undesirable content from the training data used to build large language models (LLMs). The core steps include:
- Content Filtering: Employing a series of filters to detect and remove text containing explicit sexual content, violence, hate speech, and other problematic material.
- Toxicity Scoring: Using a toxicity classifier to assign a "harmfulness" score to each training example, allowing the researchers to selectively remove the most toxic content.
- Bias Mitigation: Applying techniques to reduce demographic biases and ensure more balanced representation in the training data.
- Manual Curation: Having human experts review samples of the filtered data to catch any remaining issues.
The researchers evaluate the impact of this data curation pipeline on the safety and performance of the resulting LLM, comparing it to models trained on unfiltered data. They find that the curated models demonstrate improved safety and robustness across a range of metrics, without significant degradation in core language modeling capabilities.
Critical Analysis
The paper makes a compelling case for the importance of carefully curating the training data used to build large language models. By proactively removing harmful content, the researchers were able to produce models that are more inherently aligned with important safety and ethical considerations.
That said, the authors acknowledge that their approach is not a panacea. The data curation pipeline relies on imperfect toxicity and bias detection models, which could inadvertently remove content that is not actually problematic. There are also inherent challenges in defining and identifying "harmful" or "biased" text, which can be subjective and context-dependent.
Additionally, the paper focuses primarily on the safety and robustness of the resulting language models, but does not explore the potential downstream impacts on real-world applications and end-users. It would be valuable to see further research on how these curated models perform in practical deployment scenarios, and whether they are truly more beneficial and trustworthy than their uncurated counterparts.
Conclusion
This paper presents an important step forward in the quest to build large language models that are reliably safe and beneficial. By carefully curating the training data to remove harmful content, the researchers have demonstrated a pathway to creating LLMs that are more inherently aligned with human values and interests.
While not a perfect solution, this work highlights the critical importance of proactive approaches to AI safety, rather than relying solely on reactive "patching" or "fine-tuning" after the fact. As the capabilities of language models continue to grow, ensuring their safety and trustworthiness will be paramount. This research represents an important contribution towards that goal.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Robustifying Safety-Aligned Large Language Models through Clean Data Curation
Xiaoqun Liu, Jiacheng Liang, Muchao Ye, Zhaohan Xi
Large language models (LLMs) are vulnerable when trained on datasets containing harmful content, which leads to potential jailbreaking attacks in two scenarios: the integration of harmful texts within crowdsourced data used for pre-training and direct tampering with LLMs through fine-tuning. In both scenarios, adversaries can compromise the safety alignment of LLMs, exacerbating malfunctions. Motivated by the need to mitigate these adversarial influences, our research aims to enhance safety alignment by either neutralizing the impact of malicious texts in pre-training datasets or increasing the difficulty of jailbreaking during downstream fine-tuning. In this paper, we propose a data curation framework designed to counter adversarial impacts in both scenarios. Our method operates under the assumption that we have no prior knowledge of attack details, focusing solely on curating clean texts. We introduce an iterative process aimed at revising texts to reduce their perplexity as perceived by LLMs, while simultaneously preserving their text quality. By pre-training or fine-tuning LLMs with curated clean texts, we observe a notable improvement in LLM robustness regarding safety alignment against harmful queries. For instance, when pre-training LLMs using a crowdsourced dataset containing 5% harmful instances, adding an equivalent amount of curated texts significantly mitigates the likelihood of providing harmful responses in LLMs and reduces the attack success rate by 71%. Our study represents a significant step towards mitigating the risks associated with training-based jailbreaking and fortifying the secure utilization of LLMs.
Read more6/3/2024
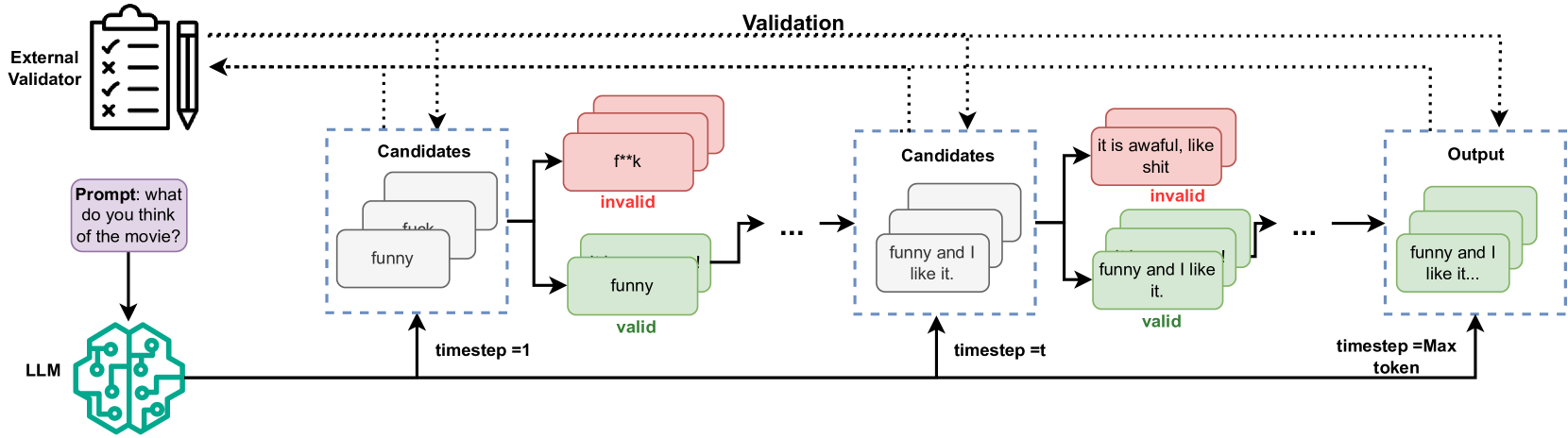
0
A Framework for Real-time Safeguarding the Text Generation of Large Language
Ximing Dong, Dayi Lin, Shaowei Wang, Ahmed E. Hassan
Large Language Models (LLMs) have significantly advanced natural language processing (NLP) tasks but also pose ethical and societal risks due to their propensity to generate harmful content. To address this, various approaches have been developed to safeguard LLMs from producing unsafe content. However, existing methods have limitations, including the need for training specific control models and proactive intervention during text generation, that lead to quality degradation and increased computational overhead. To mitigate those limitations, we propose LLMSafeGuard, a lightweight framework to safeguard LLM text generation in real-time. LLMSafeGuard integrates an external validator into the beam search algorithm during decoding, rejecting candidates that violate safety constraints while allowing valid ones to proceed. We introduce a similarity based validation approach, simplifying constraint introduction and eliminating the need for control model training. Additionally, LLMSafeGuard employs a context-wise timing selection strategy, intervening LLMs only when necessary. We evaluate LLMSafeGuard on two tasks, detoxification and copyright safeguarding, and demonstrate its superior performance over SOTA baselines. For instance, LLMSafeGuard reduces the average toxic score of. LLM output by 29.7% compared to the best baseline meanwhile preserving similar linguistic quality as natural output in detoxification task. Similarly, in the copyright task, LLMSafeGuard decreases the Longest Common Subsequence (LCS) by 56.2% compared to baselines. Moreover, our context-wise timing selection strategy reduces inference time by at least 24% meanwhile maintaining comparable effectiveness as validating each time step. LLMSafeGuard also offers tunable parameters to balance its effectiveness and efficiency.
Read more5/3/2024

0
Cross-Task Defense: Instruction-Tuning LLMs for Content Safety
Yu Fu, Wen Xiao, Jia Chen, Jiachen Li, Evangelos Papalexakis, Aichi Chien, Yue Dong
Recent studies reveal that Large Language Models (LLMs) face challenges in balancing safety with utility, particularly when processing long texts for NLP tasks like summarization and translation. Despite defenses against malicious short questions, the ability of LLMs to safely handle dangerous long content, such as manuals teaching illicit activities, remains unclear. Our work aims to develop robust defenses for LLMs in processing malicious documents alongside benign NLP task queries. We introduce a defense dataset comprised of safety-related examples and propose single-task and mixed-task losses for instruction tuning. Our empirical results demonstrate that LLMs can significantly enhance their capacity to safely manage dangerous content with appropriate instruction tuning. Additionally, strengthening the defenses of tasks most susceptible to misuse is effective in protecting LLMs against processing harmful information. We also observe that trade-offs between utility and safety exist in defense strategies, where Llama2, utilizing our proposed approach, displays a significantly better balance compared to Llama1.
Read more5/27/2024

0
Course-Correction: Safety Alignment Using Synthetic Preferences
Rongwu Xu, Yishuo Cai, Zhenhong Zhou, Renjie Gu, Haiqin Weng, Yan Liu, Tianwei Zhang, Wei Xu, Han Qiu
The risk of harmful content generated by large language models (LLMs) becomes a critical concern. This paper presents a systematic study on assessing and improving LLMs' capability to perform the task of textbf{course-correction}, ie, the model can steer away from generating harmful content autonomously. To start with, we introduce the textsc{C$^2$-Eval} benchmark for quantitative assessment and analyze 10 popular LLMs, revealing varying proficiency of current safety-tuned LLMs in course-correction. To improve, we propose fine-tuning LLMs with preference learning, emphasizing the preference for timely course-correction. Using an automated pipeline, we create textsc{C$^2$-Syn}, a synthetic dataset with 750K pairwise preferences, to teach models the concept of timely course-correction through data-driven preference learning. Experiments on 2 LLMs, textsc{Llama2-Chat 7B} and textsc{Qwen2 7B}, show that our method effectively enhances course-correction skills without affecting general performance. Additionally, it effectively improves LLMs' safety, particularly in resisting jailbreak attacks.
Read more7/24/2024