A Course Shared Task on Evaluating LLM Output for Clinical Questions

0

Sign in to get full access
Overview
- This paper describes a shared task for evaluating the performance of large language models (LLMs) on answering clinical questions.
- The task aims to benchmark LLMs in a healthcare context and identify strengths and weaknesses.
- Participants will submit systems that generate answers to a set of clinical questions, which will then be evaluated by human raters.
Plain English Explanation
The paper proposes a shared task to assess how well large AI language models (LLMs) can answer medical questions. LLMs are powerful language-processing systems that have shown impressive abilities, but their performance in specialized domains like healthcare is not well understood.
The shared task involves participants developing AI systems that can generate answers to a set of sample clinical questions. These answers will then be evaluated by human experts to determine how accurate, relevant, and helpful they are. The goal is to better understand the strengths and limitations of LLMs when it comes to providing medical information, which could inform how they are used in real-world healthcare applications.
By creating a standardized benchmark, the researchers hope to advance the field and push LLMs to become more reliable and capable at assisting with clinical tasks. This could lead to LLMs being used to help doctors, nurses, and patients access medical knowledge more effectively.
Technical Explanation
The shared task involves participants developing systems that can answer a set of clinical questions. Participants will submit their systems, which will then be evaluated by human raters on criteria like accuracy, relevance, and helpfulness.
The task dataset will consist of a curated collection of questions covering various medical topics. Answers generated by participant systems will be compared to reference answers provided by medical experts.
The evaluation process will involve human raters assessing the quality of the submitted answers. Raters will provide scores based on factors like factual correctness, coherence, and usefulness. Aggregate scores will be used to rank the participating systems.
The task organizers hope that this benchmark will help identify strengths and weaknesses of LLMs in a healthcare context, guiding future research and development efforts.
Critical Analysis
The paper acknowledges potential limitations of the shared task, including the challenge of creating a dataset representative of real-world clinical questions and the subjectivity inherent in human evaluation.
Additionally, the task may not fully capture the nuances of how LLMs could be used in clinical settings, such as their ability to engage in back-and-forth dialogue or to integrate with other medical systems. Further research may be needed to address these broader practical considerations.
That said, the shared task approach represents a valuable step forward in empirically evaluating LLM performance in healthcare. By establishing a standardized benchmark, the research community can more effectively track progress and identify areas for improvement.
Conclusion
This paper proposes a shared task to assess the ability of large language models to answer clinical questions. The goal is to better understand the strengths and limitations of these powerful AI systems in a healthcare context, which could inform their future development and real-world applications.
By creating a standardized benchmark, the researchers hope to advance the field and push LLMs to become more reliable and capable at assisting with medical tasks. This could ultimately lead to LLMs being used to help healthcare providers and patients access medical knowledge more effectively.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Course Shared Task on Evaluating LLM Output for Clinical Questions
Yufang Hou, Thy Thy Tran, Doan Nam Long Vu, Yiwen Cao, Kai Li, Lukas Rohde, Iryna Gurevych
This paper presents a shared task that we organized at the Foundations of Language Technology (FoLT) course in 2023/2024 at the Technical University of Darmstadt, which focuses on evaluating the output of Large Language Models (LLMs) in generating harmful answers to health-related clinical questions. We describe the task design considerations and report the feedback we received from the students. We expect the task and the findings reported in this paper to be relevant for instructors teaching natural language processing (NLP) and designing course assignments.
Read more8/2/2024
💬
0
Evaluating large language models in medical applications: a survey
Xiaolan Chen, Jiayang Xiang, Shanfu Lu, Yexin Liu, Mingguang He, Danli Shi
Large language models (LLMs) have emerged as powerful tools with transformative potential across numerous domains, including healthcare and medicine. In the medical domain, LLMs hold promise for tasks ranging from clinical decision support to patient education. However, evaluating the performance of LLMs in medical contexts presents unique challenges due to the complex and critical nature of medical information. This paper provides a comprehensive overview of the landscape of medical LLM evaluation, synthesizing insights from existing studies and highlighting evaluation data sources, task scenarios, and evaluation methods. Additionally, it identifies key challenges and opportunities in medical LLM evaluation, emphasizing the need for continued research and innovation to ensure the responsible integration of LLMs into clinical practice.
Read more5/14/2024

0
A Survey on Large Language Models from General Purpose to Medical Applications: Datasets, Methodologies, and Evaluations
Jinqiang Wang, Huansheng Ning, Yi Peng, Qikai Wei, Daniel Tesfai, Wenwei Mao, Tao Zhu, Runhe Huang
Large Language Models (LLMs) have demonstrated surprising performance across various natural language processing tasks. Recently, medical LLMs enhanced with domain-specific knowledge have exhibited excellent capabilities in medical consultation and diagnosis. These models can smoothly simulate doctor-patient dialogues and provide professional medical advice. Most medical LLMs are developed through continued training of open-source general LLMs, which require significantly fewer computational resources than training LLMs from scratch. Additionally, this approach offers better patient privacy protection than API-based solutions. Given the above advantages, this survey systematically summarizes how to train medical LLMs based on open-source general LLMs from a more fine-grained perspective. It covers (a) how to acquire training corpus and construct customized medical training sets, (b) how to choose an appropriate training paradigm, (c) how to choose a suitable evaluation benchmark, and (d) existing challenges and promising research directions are discussed. This survey can provide guidance for the development of LLMs focused on various medical applications, such as medical education, diagnostic planning, and clinical assistants. Related resources and supplemental information can be found on the GitHub repository.
Read more9/24/2024
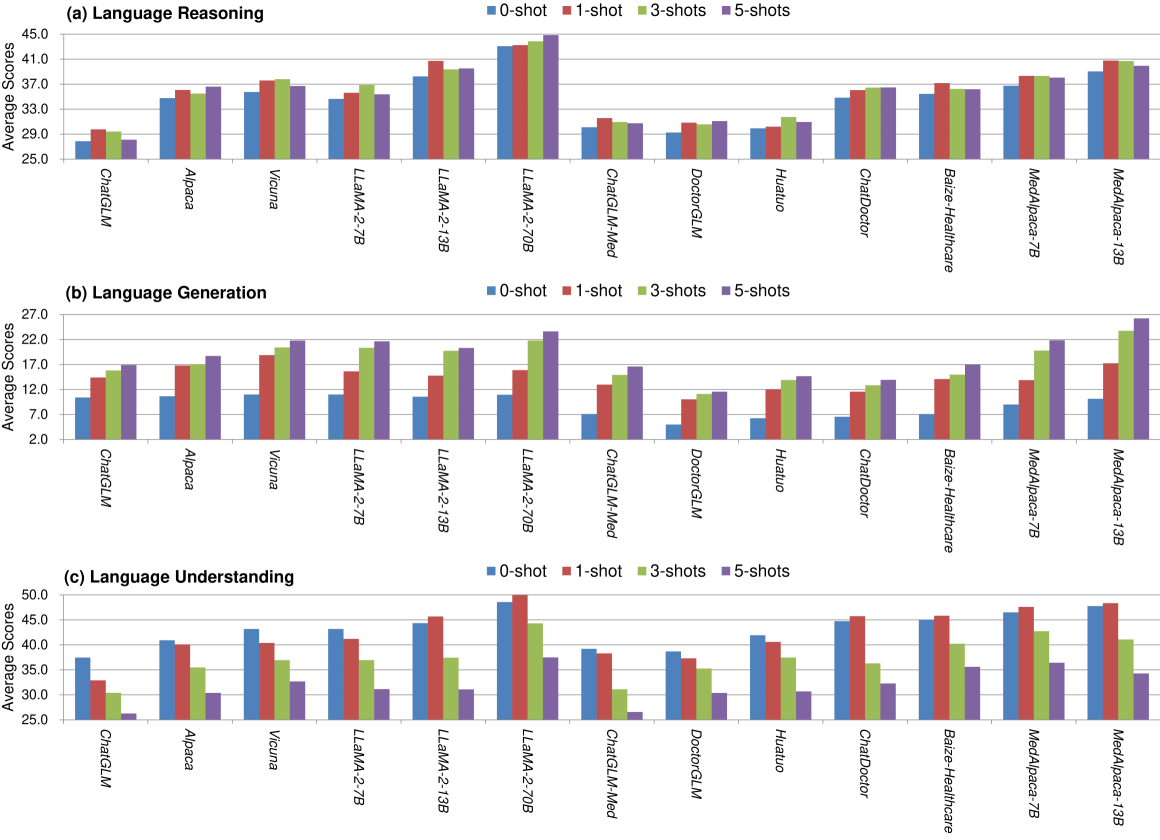
0
Large Language Models in Healthcare: A Comprehensive Benchmark
Andrew Liu, Hongjian Zhou, Yining Hua, Omid Rohanian, Anshul Thakur, Lei Clifton, David A. Clifton
The adoption of large language models (LLMs) to assist clinicians has attracted remarkable attention. Existing works mainly adopt the close-ended question-answering (QA) task with answer options for evaluation. However, many clinical decisions involve answering open-ended questions without pre-set options. To better understand LLMs in the clinic, we construct a benchmark ClinicBench. We first collect eleven existing datasets covering diverse clinical language generation, understanding, and reasoning tasks. Furthermore, we construct six novel datasets and complex clinical tasks that are close to real-world practice, i.e., referral QA, treatment recommendation, hospitalization (long document) summarization, patient education, pharmacology QA and drug interaction for emerging drugs. We conduct an extensive evaluation of twenty-two LLMs under both zero-shot and few-shot settings. Finally, we invite medical experts to evaluate the clinical usefulness of LLMs.
Read more6/27/2024