CP-Prompt: Composition-Based Cross-modal Prompting for Domain-Incremental Continual Learning

0

Sign in to get full access
Overview
- This paper introduces a new technique called "CP-Prompt" for domain-incremental continual learning using cross-modal prompting.
- The key idea is to compose prompts from previously learned domains to adapt to new domains, enabling efficient learning without forgetting.
- The method is evaluated on various benchmarks and shows strong performance compared to existing continual learning approaches.
Plain English Explanation
CP-Prompt: Composition-Based Cross-modal Prompting for Domain-Incremental Continual Learning presents a novel approach to enable machine learning models to continuously learn new tasks or "domains" without forgetting what they've learned before. This is an important challenge known as "continual learning."
The core insight is that when a model needs to adapt to a new domain, it can compose prompts - short text descriptions that guide the model's behavior - from the prompts it has learned for previous domains. By combining these prompts in an intelligent way, the model can efficiently learn the new task without catastrophically forgetting the old ones.
This "cross-modal" prompting strategy allows the model to leverage knowledge from different modalities, like text and images, to better adapt to new scenarios. The authors evaluate this approach on various benchmarks and show that it outperforms existing continual learning methods.
The key advantage of this technique is that it enables continual learning in a scalable and flexible way. Rather than having to completely retrain a model from scratch every time a new task is introduced, the model can dynamically compose prompt-based adaptations to handle the new domain. This makes the learning process more efficient and helps the model retain its previous knowledge.
Technical Explanation
CP-Prompt: Composition-Based Cross-modal Prompting for Domain-Incremental Continual Learning introduces a new continual learning approach called "Composition-Based Cross-modal Prompting" (CP-Prompt). The core idea is to leverage prompts - short text descriptions that guide a model's behavior - to enable efficient adaptation to new domains without forgetting previous knowledge.
The authors propose a prompting-based framework where the model learns a set of domain-specific prompts during training. When a new domain is encountered, the model composes these prompts in an intelligent way to adapt to the new task. This "cross-modal" prompting strategy allows the model to leverage knowledge from different modalities, like text and images, to better handle the new domain.
The key components of the CP-Prompt approach include:
- Prompt Encoder: A neural network that encodes domain-specific prompts into a latent representation.
- Prompt Composer: A module that dynamically composes prompts from the learned latent representations to adapt to new domains.
- Task-Specific Prompt Adapter: An additional network that fine-tunes the composed prompt for the specific task.
The authors evaluate CP-Prompt on various domain-incremental learning benchmarks, including image classification, text classification, and multi-modal tasks. The results demonstrate that CP-Prompt outperforms existing continual learning techniques in terms of performance and parameter efficiency.
Critical Analysis
The CP-Prompt paper presents a promising approach to address the challenge of domain-incremental continual learning. The key strengths of the method include:
- Prompt-Based Adaptation: By leveraging prompts to adapt to new domains, the model can learn efficiently without catastrophically forgetting previous knowledge.
- Cross-Modal Prompting: The ability to compose prompts from different modalities allows the model to better leverage its accumulated knowledge.
- Scalability: The prompting-based framework enables continual learning in a more scalable way compared to full model retraining.
However, the paper also acknowledges some limitations and potential areas for future work:
- Prompt Composability: The authors note that the composability of prompts is an important factor in the performance of CP-Prompt, and further research is needed to understand the optimal ways to compose prompts.
- Task Similarity: The paper focuses on domain-incremental learning, where tasks are related, but it's unclear how the method would perform in more diverse, task-incremental scenarios.
- Computational Efficiency: While the prompting-based approach is more efficient than full model retraining, there may still be room for improvement in terms of computational cost, especially as the number of domains grows.
Overall, the CP-Prompt paper presents an innovative and promising approach to continual learning that leverages the power of prompts. The results are compelling, and the technique has the potential to advance the state-of-the-art in this important area of machine learning research.
Conclusion
CP-Prompt: Composition-Based Cross-modal Prompting for Domain-Incremental Continual Learning introduces a novel continual learning technique that uses cross-modal prompting to enable efficient adaptation to new domains without forgetting previous knowledge. By composing prompts learned from different modalities, the model can quickly adapt to new tasks while retaining its accumulated expertise.
The evaluation results demonstrate the effectiveness of this approach, which outperforms existing continual learning methods. The prompting-based framework also offers advantages in terms of scalability and computational efficiency compared to full model retraining.
While the paper identifies some areas for further research, such as understanding prompt composability and extending the method to more diverse task scenarios, the CP-Prompt technique represents an important contribution to the field of continual learning. As machine learning models continue to be deployed in real-world, dynamic environments, advances like this will be crucial for enabling models to learn and adapt in a flexible and robust manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CP-Prompt: Composition-Based Cross-modal Prompting for Domain-Incremental Continual Learning
Yu Feng, Zhen Tian, Yifan Zhu, Zongfu Han, Haoran Luo, Guangwei Zhang, Meina Song
The key challenge of cross-modal domain-incremental learning (DIL) is to enable the learning model to continuously learn from novel data with different feature distributions under the same task without forgetting old ones. However, existing top-performing methods still cause high forgetting rates, by lacking intra-domain knowledge extraction and inter-domain common prompting strategy. In this paper, we propose a simple yet effective framework, CP-Prompt, by training limited parameters to instruct a pre-trained model to learn new domains and avoid forgetting existing feature distributions. CP-Prompt captures intra-domain knowledge by compositionally inserting personalized prompts on multi-head self-attention layers and then learns the inter-domain knowledge with a common prompting strategy. CP-Prompt shows superiority compared with state-of-the-art baselines among three widely evaluated DIL tasks. The source code is available at https://github.com/dannis97500/CP_Prompt.
Read more8/6/2024
0
Adapting to Distribution Shift by Visual Domain Prompt Generation
Zhixiang Chi, Li Gu, Tao Zhong, Huan Liu, Yuanhao Yu, Konstantinos N Plataniotis, Yang Wang
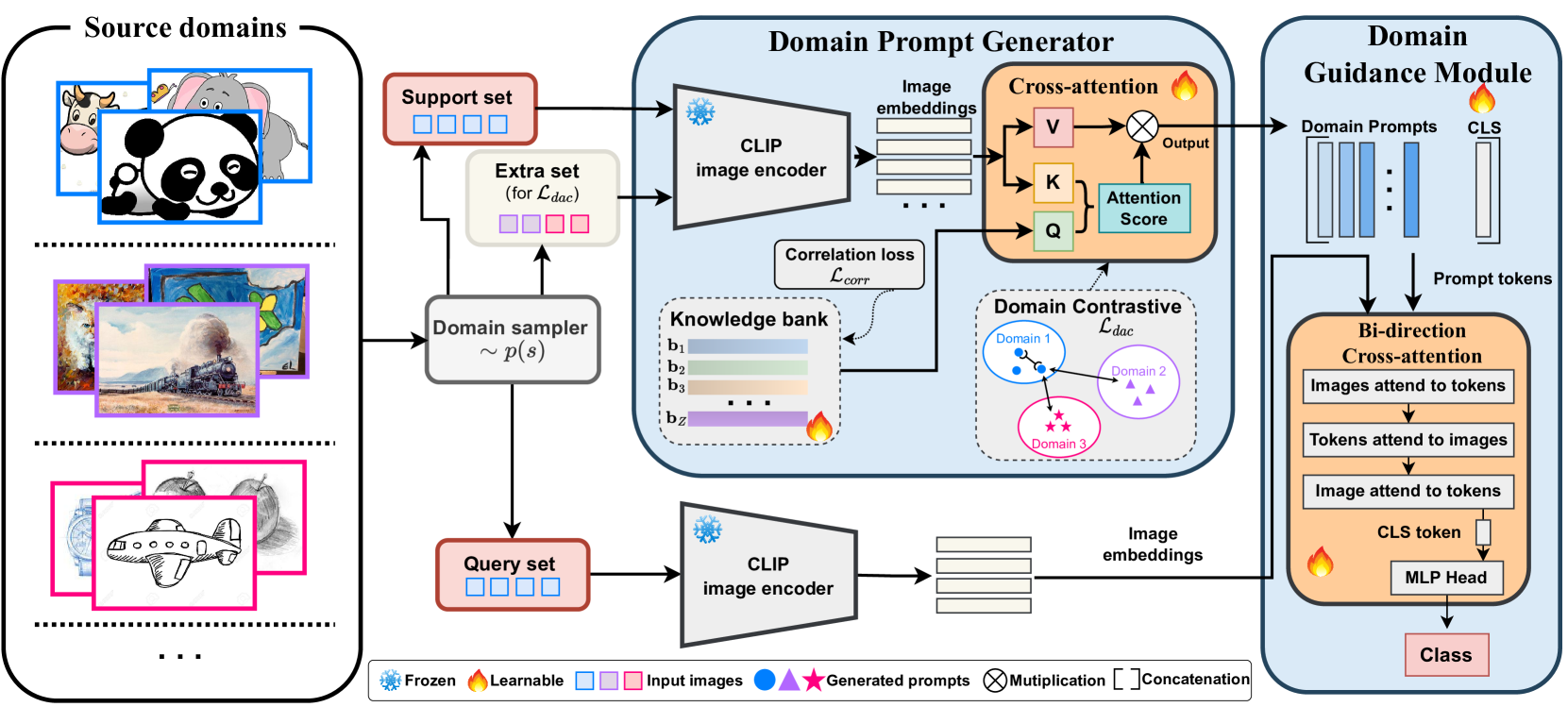
In this paper, we aim to adapt a model at test-time using a few unlabeled data to address distribution shifts. To tackle the challenges of extracting domain knowledge from a limited amount of data, it is crucial to utilize correlated information from pre-trained backbones and source domains. Previous studies fail to utilize recent foundation models with strong out-of-distribution generalization. Additionally, domain-centric designs are not flavored in their works. Furthermore, they employ the process of modelling source domains and the process of learning to adapt independently into disjoint training stages. In this work, we propose an approach on top of the pre-computed features of the foundation model. Specifically, we build a knowledge bank to learn the transferable knowledge from source domains. Conditioned on few-shot target data, we introduce a domain prompt generator to condense the knowledge bank into a domain-specific prompt. The domain prompt then directs the visual features towards a particular domain via a guidance module. Moreover, we propose a domain-aware contrastive loss and employ meta-learning to facilitate domain knowledge extraction. Extensive experiments are conducted to validate the domain knowledge extraction. The proposed method outperforms previous work on 5 large-scale benchmarks including WILDS and DomainNet.
Read more5/7/2024
0
Convolutional Prompting meets Language Models for Continual Learning
Anurag Roy, Riddhiman Moulick, Vinay K. Verma, Saptarshi Ghosh, Abir Das
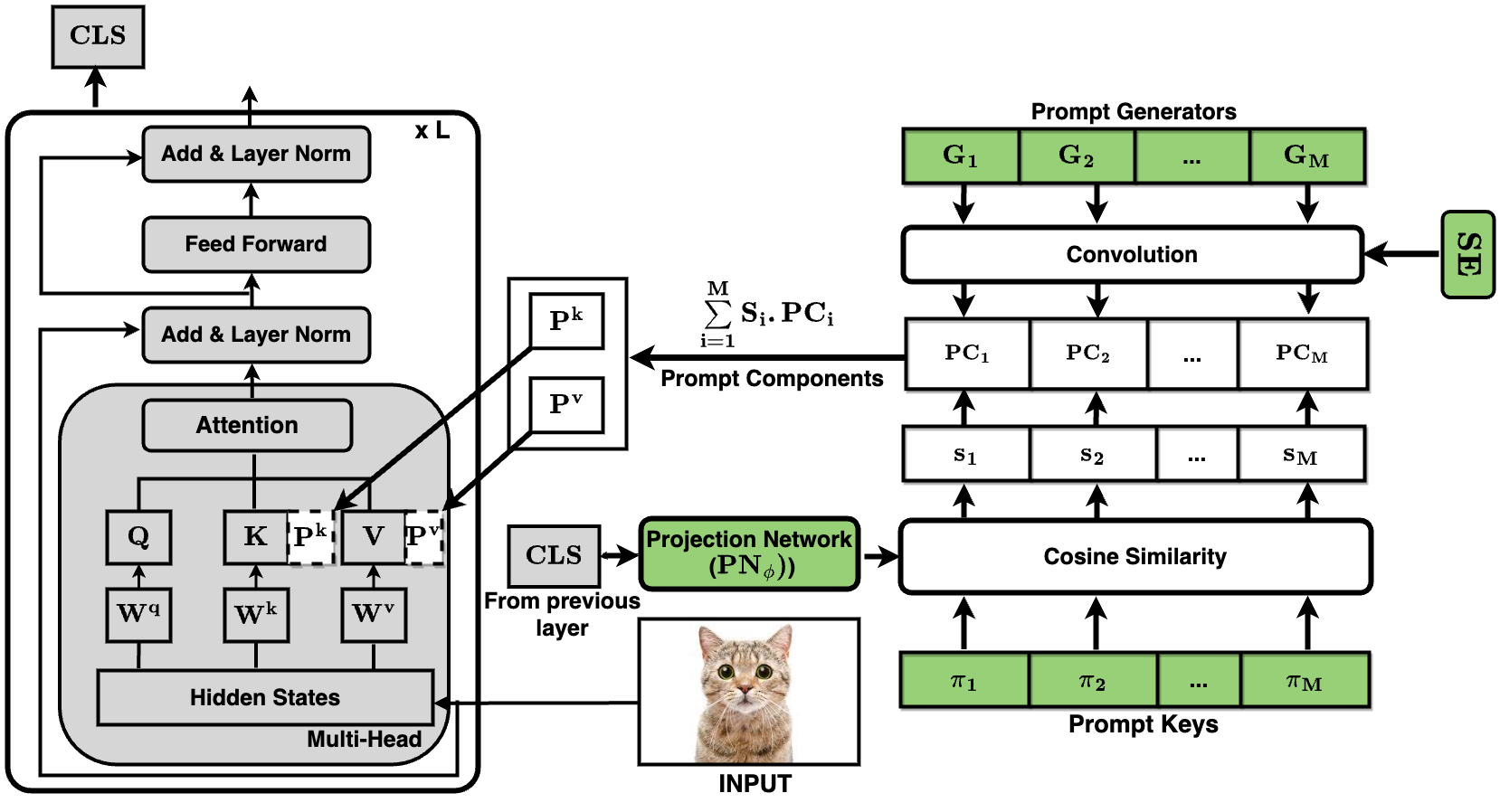
Continual Learning (CL) enables machine learning models to learn from continuously shifting new training data in absence of data from old tasks. Recently, pretrained vision transformers combined with prompt tuning have shown promise for overcoming catastrophic forgetting in CL. These approaches rely on a pool of learnable prompts which can be inefficient in sharing knowledge across tasks leading to inferior performance. In addition, the lack of fine-grained layer specific prompts does not allow these to fully express the strength of the prompts for CL. We address these limitations by proposing ConvPrompt, a novel convolutional prompt creation mechanism that maintains layer-wise shared embeddings, enabling both layer-specific learning and better concept transfer across tasks. The intelligent use of convolution enables us to maintain a low parameter overhead without compromising performance. We further leverage Large Language Models to generate fine-grained text descriptions of each category which are used to get task similarity and dynamically decide the number of prompts to be learned. Extensive experiments demonstrate the superiority of ConvPrompt and improves SOTA by ~3% with significantly less parameter overhead. We also perform strong ablation over various modules to disentangle the importance of different components.
Read more4/1/2024

0
PromptKD: Unsupervised Prompt Distillation for Vision-Language Models
Zheng Li, Xiang Li, Xinyi Fu, Xin Zhang, Weiqiang Wang, Shuo Chen, Jian Yang
Prompt learning has emerged as a valuable technique in enhancing vision-language models (VLMs) such as CLIP for downstream tasks in specific domains. Existing work mainly focuses on designing various learning forms of prompts, neglecting the potential of prompts as effective distillers for learning from larger teacher models. In this paper, we introduce an unsupervised domain prompt distillation framework, which aims to transfer the knowledge of a larger teacher model to a lightweight target model through prompt-driven imitation using unlabeled domain images. Specifically, our framework consists of two distinct stages. In the initial stage, we pre-train a large CLIP teacher model using domain (few-shot) labels. After pre-training, we leverage the unique decoupled-modality characteristics of CLIP by pre-computing and storing the text features as class vectors only once through the teacher text encoder. In the subsequent stage, the stored class vectors are shared across teacher and student image encoders for calculating the predicted logits. Further, we align the logits of both the teacher and student models via KL divergence, encouraging the student image encoder to generate similar probability distributions to the teacher through the learnable prompts. The proposed prompt distillation process eliminates the reliance on labeled data, enabling the algorithm to leverage a vast amount of unlabeled images within the domain. Finally, the well-trained student image encoders and pre-stored text features (class vectors) are utilized for inference. To our best knowledge, we are the first to (1) perform unsupervised domain-specific prompt-driven knowledge distillation for CLIP, and (2) establish a practical pre-storing mechanism of text features as shared class vectors between teacher and student. Extensive experiments on 11 datasets demonstrate the effectiveness of our method.
Read more8/14/2024