cPAPERS: A Dataset of Situated and Multimodal Interactive Conversations in Scientific Papers
2406.08398
0
0

Abstract
An emerging area of research in situated and multimodal interactive conversations (SIMMC) includes interactions in scientific papers. Since scientific papers are primarily composed of text, equations, figures, and tables, SIMMC methods must be developed specifically for each component to support the depth of inquiry and interactions required by research scientists. This work introduces Conversational Papers (cPAPERS), a dataset of conversational question-answer pairs from reviews of academic papers grounded in these paper components and their associated references from scientific documents available on arXiv. We present a data collection strategy to collect these question-answer pairs from OpenReview and associate them with contextual information from LaTeX source files. Additionally, we present a series of baseline approaches utilizing Large Language Models (LLMs) in both zero-shot and fine-tuned configurations to address the cPAPERS dataset.
Create account to get full access
Overview
• This paper introduces cPAPERS, a dataset of situated and multimodal interactive conversations in scientific papers.
• The dataset consists of conversations between researchers, students, and AI assistants discussing the content and context of research papers.
• The conversations cover a range of topics, including clarifying concepts, elaborating on methodologies, and reflecting on implications of the research.
• The dataset aims to support the development of AI systems that can engage in natural, contextual dialogue about scientific literature.
Plain English Explanation
The researchers have created a dataset called cPAPERS that contains conversations about scientific papers. In these conversations, researchers, students, and AI assistants discuss the content and context of the research. They ask questions, clarify concepts, talk about the methods used, and reflect on what the findings might mean.
The goal is to help develop AI systems that can engage in natural, meaningful dialogue about scientific literature. This is useful because it could allow people to better understand research papers by discussing them with an AI assistant, just like they would with another human. The conversations cover a wide range of topics related to the papers, so the AI can learn to handle many different types of questions and discussions.
Technical Explanation
The cPAPERS dataset consists of over 10,000 conversations between researchers, students, and AI assistants discussing the content and context of scientific papers. The conversations cover a broad range of topics, including clarifying concepts, elaborating on methodologies, and reflecting on the implications of the research.
The dataset was collected using a multi-stage crowdsourcing pipeline. First, researchers and students were asked to write conversations based on provided paper abstracts. Then, AI assistants were introduced into the conversations to provide responses. Finally, the conversations were revised and expanded through further iterations.
The resulting dataset captures the situated and multimodal nature of human-AI dialogue about scientific literature. It includes not only the text of the conversations, but also references to figures, equations, and other paper elements that are discussed. This contextual information is intended to support the development of AI systems that can engage in more natural and grounded discussions.
Critical Analysis
The cPAPERS dataset represents a valuable resource for advancing the state of the art in AI-based scientific literature understanding and discussion. By capturing realistic conversations about research papers, it provides important training data for developing systems that can communicate about complex technical topics in a more natural and contextual way.
However, the dataset does have some limitations. The conversations are still somewhat constrained and idealized, as they were generated through a multi-stage process rather than occurring organically. Additionally, the dataset only covers a specific set of research papers, so the range of topics may not be fully representative of the broader scientific literature.
Further research would be needed to fully evaluate the usefulness of the cPAPERS dataset for training AI systems. Potential areas for exploration include assessing the generalization of models trained on the data, as well as investigating ways to extend the dataset to capture even more natural and open-ended conversations.
Conclusion
The cPAPERS dataset represents an important step forward in creating AI systems that can engage in situated, multimodal dialogue about scientific literature. By providing a rich set of conversations covering a variety of research topics and contexts, the dataset has the potential to support the development of more natural and intuitive AI assistants for scientific understanding and communication.
While the dataset has some limitations, it serves as a valuable resource for researchers and developers working to advance the field of AI-based scientific literature understanding. As the dataset is further expanded and refined, it could lead to significant improvements in how people interact with and learn from the growing body of scientific knowledge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
Russian-Language Multimodal Dataset for Automatic Summarization of Scientific Papers
Alena Tsanda, Elena Bruches
0
0
The paper discusses the creation of a multimodal dataset of Russian-language scientific papers and testing of existing language models for the task of automatic text summarization. A feature of the dataset is its multimodal data, which includes texts, tables and figures. The paper presents the results of experiments with two language models: Gigachat from SBER and YandexGPT from Yandex. The dataset consists of 420 papers and is publicly available on https://github.com/iis-research-team/summarization-dataset.
5/14/2024
Context-Enhanced Language Models for Generating Multi-Paper Citations
Avinash Anand, Kritarth Prasad, Ujjwal Goel, Mohit Gupta, Naman Lal, Astha Verma, Rajiv Ratn Shah
0
0
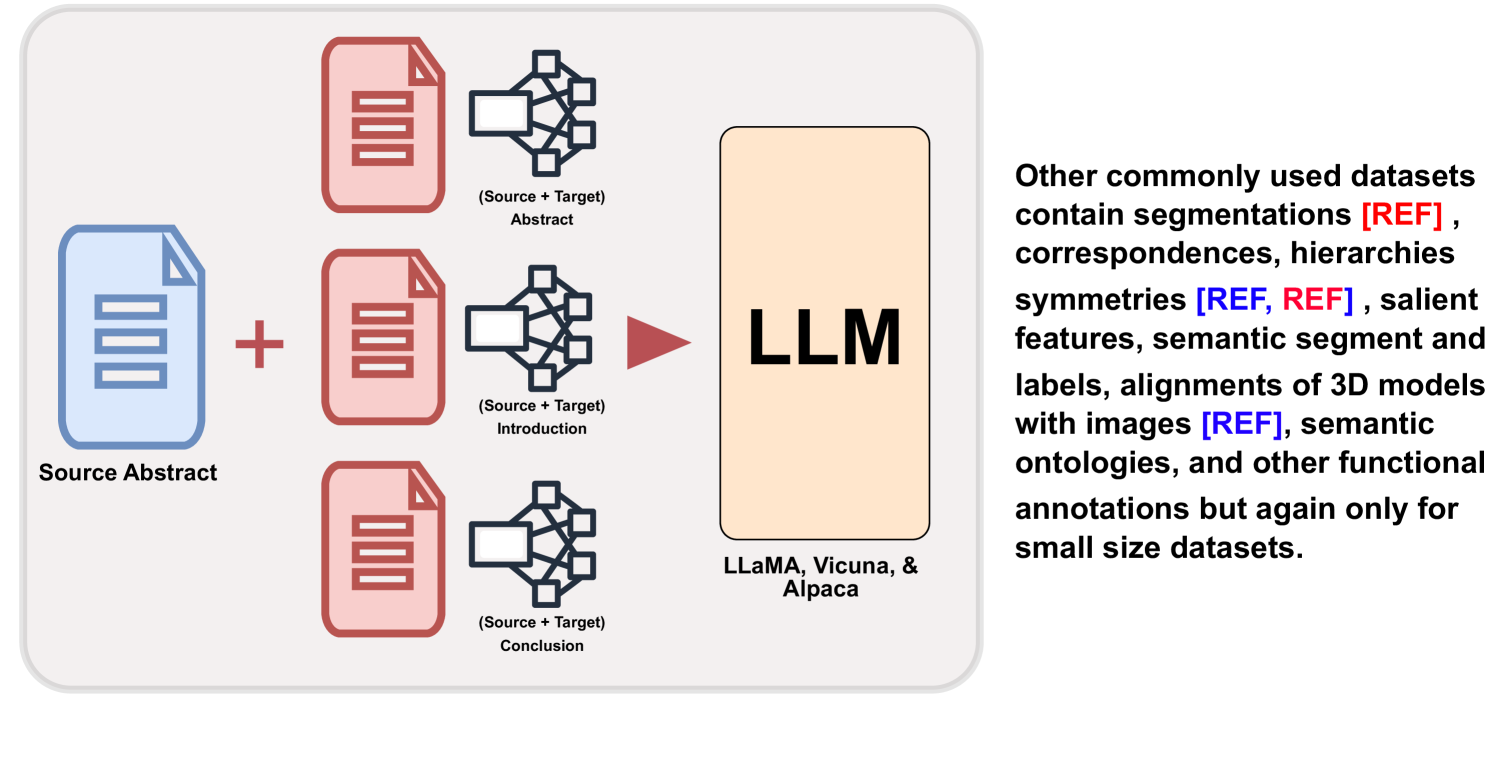
Citation text plays a pivotal role in elucidating the connection between scientific documents, demanding an in-depth comprehension of the cited paper. Constructing citations is often time-consuming, requiring researchers to delve into extensive literature and grapple with articulating relevant content. To address this challenge, the field of citation text generation (CTG) has emerged. However, while earlier methods have primarily centered on creating single-sentence citations, practical scenarios frequently necessitate citing multiple papers within a single paragraph. To bridge this gap, we propose a method that leverages Large Language Models (LLMs) to generate multi-citation sentences. Our approach involves a single source paper and a collection of target papers, culminating in a coherent paragraph containing multi-sentence citation text. Furthermore, we introduce a curated dataset named MCG-S2ORC, composed of English-language academic research papers in Computer Science, showcasing multiple citation instances. In our experiments, we evaluate three LLMs LLaMA, Alpaca, and Vicuna to ascertain the most effective model for this endeavor. Additionally, we exhibit enhanced performance by integrating knowledge graphs from target papers into the prompts for generating citation text. This research underscores the potential of harnessing LLMs for citation generation, opening a compelling avenue for exploring the intricate connections between scientific documents.
4/23/2024
🛸
Scientific Opinion Summarization: Paper Meta-review Generation Dataset, Methods, and Evaluation
Qi Zeng, Mankeerat Sidhu, Ansel Blume, Hou Pong Chan, Lu Wang, Heng Ji
0
0
Opinions in scientific research papers can be divergent, leading to controversies among reviewers. However, most existing datasets for opinion summarization are centered around product reviews and assume that the analyzed opinions are non-controversial, failing to account for the variability seen in other contexts such as academic papers, political debates, or social media discussions. To address this gap, we propose the task of scientific opinion summarization, where research paper reviews are synthesized into meta-reviews. To facilitate this task, we introduce the ORSUM dataset covering 15,062 paper meta-reviews and 57,536 paper reviews from 47 conferences. Furthermore, we propose the Checklist-guided Iterative Introspection approach, which breaks down scientific opinion summarization into several stages, iteratively refining the summary under the guidance of questions from a checklist. Our experiments show that (1) human-written summaries do not always satisfy all necessary criteria such as depth of discussion, and identifying consensus and controversy for the specific domain, and (2) the combination of task decomposition and iterative self-refinement shows strong potential for enhancing the opinions and can be applied to other complex text generation using black-box LLMs.
6/18/2024

Conversations as a Source for Teaching Scientific Concepts at Different Education Levels
Donya Rooein, Dirk Hovy
0
0
Open conversations are one of the most engaging forms of teaching. However, creating those conversations in educational software is a complex endeavor, especially if we want to address the needs of different audiences. While language models hold great promise for educational applications, there are substantial challenges in training them to engage in meaningful and effective conversational teaching, especially when considering the diverse needs of various audiences. No official data sets exist for this task to facilitate the training of language models for conversational teaching, considering the diverse needs of various audiences. This paper presents a novel source for facilitating conversational teaching of scientific concepts at various difficulty levels (from preschooler to expert), namely dialogues taken from video transcripts. We analyse this data source in various ways to show that it offers a diverse array of examples that can be used to generate contextually appropriate and natural responses to scientific topics for specific target audiences. It is a freely available valuable resource for training and evaluating conversation models, encompassing organically occurring dialogues. While the raw data is available online, we provide additional metadata for conversational analysis of dialogues at each level in all available videos.
4/17/2024