Russian-Language Multimodal Dataset for Automatic Summarization of Scientific Papers
2405.07886
0
0
🔍
Abstract
The paper discusses the creation of a multimodal dataset of Russian-language scientific papers and testing of existing language models for the task of automatic text summarization. A feature of the dataset is its multimodal data, which includes texts, tables and figures. The paper presents the results of experiments with two language models: Gigachat from SBER and YandexGPT from Yandex. The dataset consists of 420 papers and is publicly available on https://github.com/iis-research-team/summarization-dataset.
Create account to get full access
Overview
- The paper discusses the creation of a multimodal dataset of Russian-language scientific papers and testing of existing language models for the task of automatic text summarization.
- The dataset features multimodal data, including texts, tables, and figures.
- The paper presents the results of experiments with two language models: Gigachat from SBER and YandexGPT from Yandex.
- The dataset consists of 420 papers and is publicly available on GitHub.
Plain English Explanation
The researchers have developed a new dataset of Russian scientific papers that includes not only the text of the papers, but also any tables and figures that are included. This multimodal data could be useful for training language models to automatically summarize the key points of scientific papers, which could save researchers a lot of time.
The researchers tested two existing language models, Gigachat and YandexGPT, to see how well they could summarize the papers in the dataset. This case study provides insights into the strengths and limitations of current language models for this type of long-form summarization task.
Overall, this new dataset could be a valuable resource for researchers working on automatic text summarization of scientific literature, especially for the Russian-language domain, which has been less explored than other languages like Hungarian.
Technical Explanation
The researchers created a multimodal dataset of 420 Russian-language scientific papers, including not only the full text of the papers but also any tables and figures included. This dataset is publicly available on GitHub, allowing other researchers to use it for training and evaluating language models for automatic text summarization.
The researchers conducted experiments using two existing language models: Gigachat from SBER and YandexGPT from Yandex. These models were tested on the task of generating summaries of the papers in the dataset. The results provide insights into the performance of current state-of-the-art language models on this multimodal, long-form summarization task in the Russian-language domain.
Critical Analysis
The paper provides a useful benchmark dataset for evaluating language models on the task of summarizing Russian-language scientific literature. However, the dataset is relatively small, consisting of only 420 papers. Expanding the dataset size and diversity could help provide more robust evaluations of model performance.
Additionally, the paper does not delve deeply into the specific challenges posed by the multimodal nature of the dataset, such as how the models incorporated information from the tables and figures. Further analysis of this aspect could yield valuable insights for the development of more effective multimodal summarization models.
While the experiments with Gigachat and YandexGPT provide a starting point, exploring a wider range of language models, including more recent large language models, could uncover additional insights and help identify the most promising approaches for this task.
Conclusion
This paper presents a new multimodal dataset of Russian-language scientific papers and explores the performance of two existing language models on the task of automatically summarizing the content of these papers. The dataset could be a valuable resource for researchers working on text summarization in the Russian domain, and the insights from the experiments can inform the development of more effective multimodal summarization models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
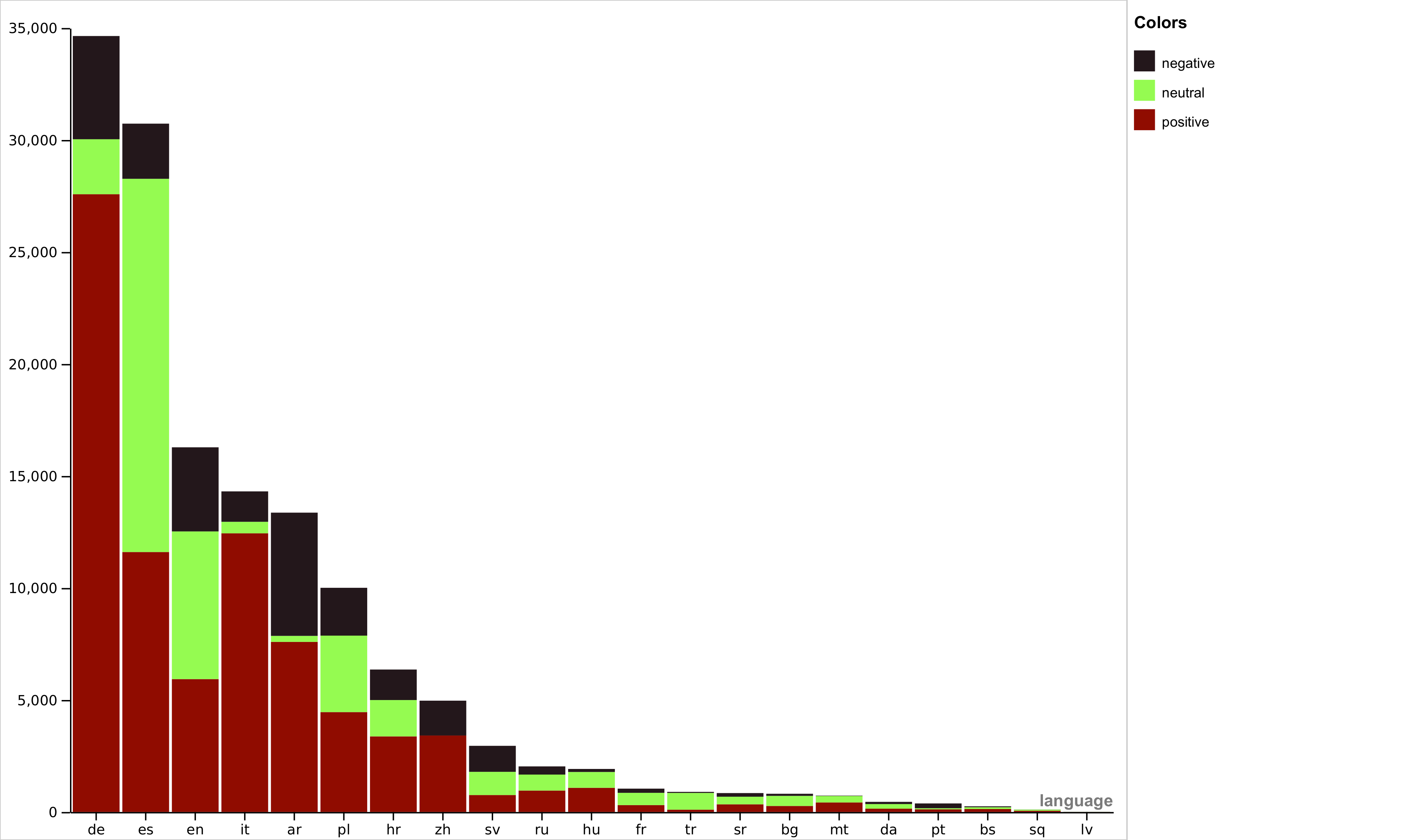
M2SA: Multimodal and Multilingual Model for Sentiment Analysis of Tweets
Gaurish Thakkar, Sherzod Hakimov, Marko Tadi'c
0
0
In recent years, multimodal natural language processing, aimed at learning from diverse data types, has garnered significant attention. However, there needs to be more clarity when it comes to analysing multimodal tasks in multi-lingual contexts. While prior studies on sentiment analysis of tweets have predominantly focused on the English language, this paper addresses this gap by transforming an existing textual Twitter sentiment dataset into a multimodal format through a straightforward curation process. Our work opens up new avenues for sentiment-related research within the research community. Additionally, we conduct baseline experiments utilising this augmented dataset and report the findings. Notably, our evaluations reveal that when comparing unimodal and multimodal configurations, using a sentiment-tuned large language model as a text encoder performs exceptionally well.
6/13/2024

cPAPERS: A Dataset of Situated and Multimodal Interactive Conversations in Scientific Papers
Anirudh Sundar, Jin Xu, William Gay, Christopher Richardson, Larry Heck
0
0
An emerging area of research in situated and multimodal interactive conversations (SIMMC) includes interactions in scientific papers. Since scientific papers are primarily composed of text, equations, figures, and tables, SIMMC methods must be developed specifically for each component to support the depth of inquiry and interactions required by research scientists. This work introduces Conversational Papers (cPAPERS), a dataset of conversational question-answer pairs from reviews of academic papers grounded in these paper components and their associated references from scientific documents available on arXiv. We present a data collection strategy to collect these question-answer pairs from OpenReview and associate them with contextual information from LaTeX source files. Additionally, we present a series of baseline approaches utilizing Large Language Models (LLMs) in both zero-shot and fine-tuned configurations to address the cPAPERS dataset.
6/13/2024
💬
Language and Multimodal Models in Sports: A Survey of Datasets and Applications
Haotian Xia, Zhengbang Yang, Yun Zhao, Yuqing Wang, Jingxi Li, Rhys Tracy, Zhuangdi Zhu, Yuan-fang Wang, Hanjie Chen, Weining Shen
0
0
Recent integration of Natural Language Processing (NLP) and multimodal models has advanced the field of sports analytics. This survey presents a comprehensive review of the datasets and applications driving these innovations post-2020. We overviewed and categorized datasets into three primary types: language-based, multimodal, and convertible datasets. Language-based and multimodal datasets are for tasks involving text or multimodality (e.g., text, video, audio), respectively. Convertible datasets, initially single-modal (video), can be enriched with additional annotations, such as explanations of actions and video descriptions, to become multimodal, offering future potential for richer and more diverse applications. Our study highlights the contributions of these datasets to various applications, from improving fan experiences to supporting tactical analysis and medical diagnostics. We also discuss the challenges and future directions in dataset development, emphasizing the need for diverse, high-quality data to support real-time processing and personalized user experiences. This survey provides a foundational resource for researchers and practitioners aiming to leverage NLP and multimodal models in sports, offering insights into current trends and future opportunities in the field.
6/19/2024
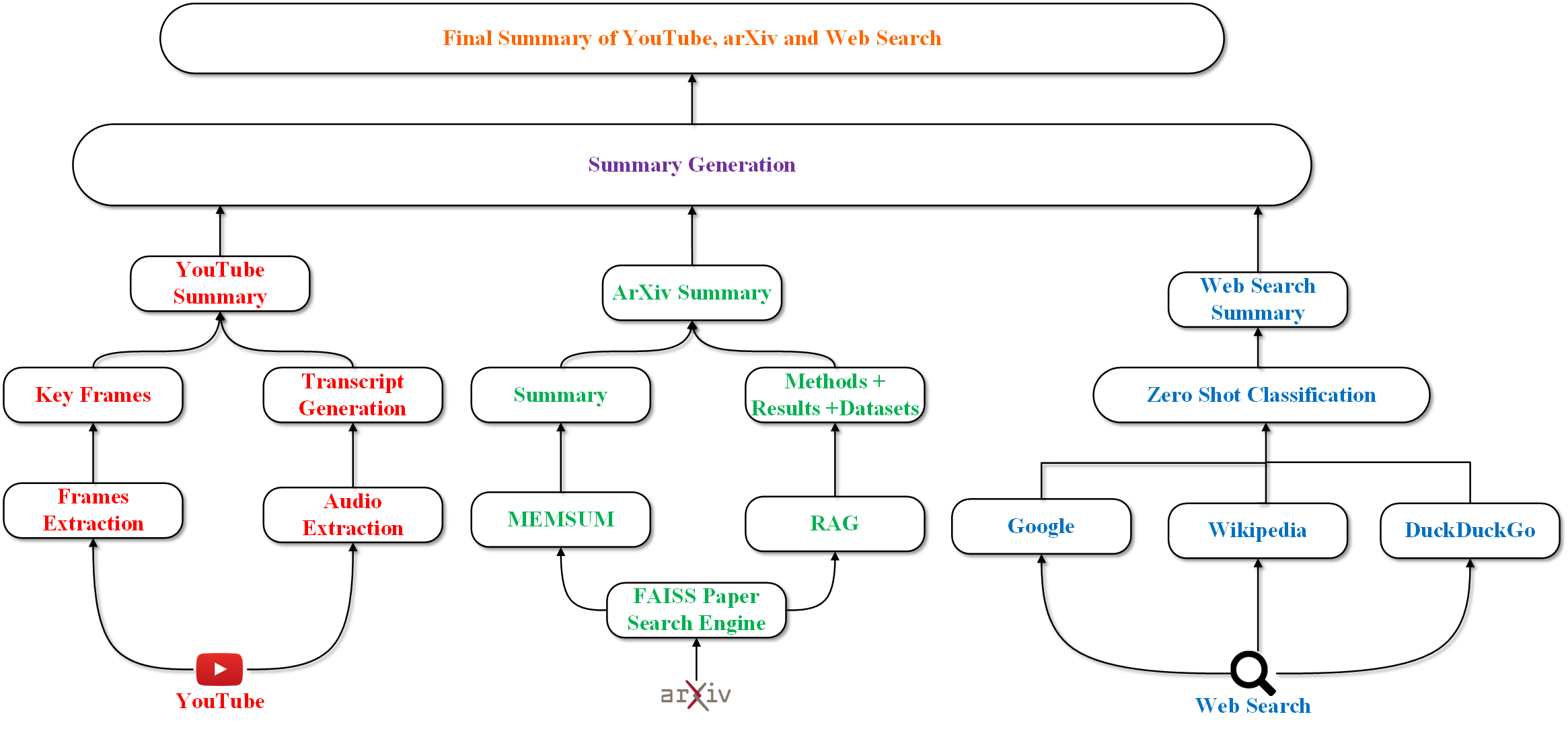
Converging Dimensions: Information Extraction and Summarization through Multisource, Multimodal, and Multilingual Fusion
Pranav Janjani, Mayank Palan, Sarvesh Shirude, Ninad Shegokar, Sunny Kumar, Faruk Kazi
0
0
Recent advances in large language models (LLMs) have led to new summarization strategies, offering an extensive toolkit for extracting important information. However, these approaches are frequently limited by their reliance on isolated sources of data. The amount of information that can be gathered is limited and covers a smaller range of themes, which introduces the possibility of falsified content and limited support for multilingual and multimodal data. The paper proposes a novel approach to summarization that tackles such challenges by utilizing the strength of multiple sources to deliver a more exhaustive and informative understanding of intricate topics. The research progresses beyond conventional, unimodal sources such as text documents and integrates a more diverse range of data, including YouTube playlists, pre-prints, and Wikipedia pages. The aforementioned varied sources are then converted into a unified textual representation, enabling a more holistic analysis. This multifaceted approach to summary generation empowers us to extract pertinent information from a wider array of sources. The primary tenet of this approach is to maximize information gain while minimizing information overlap and maintaining a high level of informativeness, which encourages the generation of highly coherent summaries.
6/21/2024