Scientific Opinion Summarization: Paper Meta-review Generation Dataset, Methods, and Evaluation

0
🛸
Sign in to get full access
Overview
- The paper addresses the challenge of summarizing divergent opinions in scientific research papers, which often contain controversies among reviewers.
- Existing datasets for opinion summarization are focused on product reviews, which tend to be less controversial than academic papers, political debates, or social media discussions.
- The paper proposes the task of scientific opinion summarization, where research paper reviews are synthesized into meta-reviews.
- The ORSUM dataset is introduced, covering 15,062 paper meta-reviews and 57,536 paper reviews from 47 conferences.
- The Checklist-guided Iterative Introspection approach is proposed, which breaks down scientific opinion summarization into several stages and iteratively refines the summary.
Plain English Explanation
When scientists publish their research, other scientists often review the paper and provide their opinions. These opinions can sometimes be quite different, leading to controversies among the reviewers. However, most existing datasets used for summarizing opinions only focus on product reviews, which tend to be less controversial than academic papers, political debates, or discussions on social media.
To address this gap, the researchers in this paper propose a new task called "scientific opinion summarization." The goal is to take the various reviews of a research paper and synthesize them into a single meta-review that captures the key points of agreement and disagreement among the reviewers.
To support this task, the researchers introduce a new dataset called ORSUM, which contains 15,062 paper meta-reviews and 57,536 individual paper reviews from 47 different academic conferences.
The researchers also propose a new approach called "Checklist-guided Iterative Introspection" to tackle the scientific opinion summarization task. This approach breaks down the summarization process into several stages and uses a checklist of questions to guide the refinement of the summary, iteratively improving it.
The key insights from the paper are:
- Human-written summaries don't always hit all the necessary criteria, like capturing the depth of discussion and identifying consensus and controversy.
- The combination of task decomposition and iterative self-refinement shows a lot of promise for enhancing opinion summaries, and this approach could be applied to other complex text generation tasks using large language models.
Technical Explanation
The paper first highlights the challenge of summarizing divergent opinions in scientific research papers, which often contain controversies among reviewers. In contrast, most existing datasets for opinion summarization focus on product reviews, which tend to have less controversy than academic papers, political debates, or social media discussions.
To address this gap, the researchers propose the task of "scientific opinion summarization," where the goal is to synthesize the various reviews of a research paper into a single meta-review that captures the key points of agreement and disagreement. To facilitate this task, the researchers introduce the ORSUM dataset, which covers 15,062 paper meta-reviews and 57,536 individual paper reviews from 47 different academic conferences.
The paper then presents the Checklist-guided Iterative Introspection approach, which breaks down the scientific opinion summarization task into several stages. This approach uses a checklist of questions to guide the iterative refinement of the summary, allowing the system to identify and address any missing or incomplete information.
The key experimental findings are:
- Human-written summaries do not always satisfy all the necessary criteria, such as depth of discussion and identification of consensus and controversy.
- The combination of task decomposition and iterative self-refinement shows strong potential for enhancing opinion summaries, and this approach could be applied to other complex text generation tasks using large language models.
Critical Analysis
The paper presents an important and timely research problem, as the ability to summarize divergent opinions in scientific research is crucial for understanding the nuances and controversies within a field. The introduction of the ORSUM dataset is a valuable contribution, as it provides a standardized benchmark for evaluating scientific opinion summarization systems.
The Checklist-guided Iterative Introspection approach proposed in the paper is an interesting and promising solution, as it acknowledges the inherent complexity of the task and attempts to address it through a structured, iterative process. However, the paper does not provide a detailed evaluation of the performance of this approach compared to other state-of-the-art methods, which would be helpful for assessing its effectiveness.
Additionally, the paper does not delve into the potential biases or limitations of the ORSUM dataset itself. It would be important to understand the representativeness of the dataset, as well as any potential skews or imbalances in the types of papers, reviews, or domains covered.
Overall, the paper presents a significant contribution to the field of opinion summarization, particularly in the context of scientific research. The proposed task and dataset, as well as the Checklist-guided Iterative Introspection approach, offer a valuable foundation for future research in this area.
Conclusion
This paper tackles the important and understudied problem of summarizing divergent opinions in scientific research papers, where controversies among reviewers are common. By introducing the task of scientific opinion summarization and the ORSUM dataset, the researchers have laid the groundwork for further advancements in this field.
The Checklist-guided Iterative Introspection approach presents a promising solution, leveraging task decomposition and iterative refinement to enhance the quality of opinion summaries. While more evaluation is needed, this approach could have broader applications for complex text generation tasks using large language models.
Overall, this paper makes a significant contribution to the field of opinion summarization, and its findings and resources could have important implications for how we synthesize and communicate the nuances of scientific discourse.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
Scientific Opinion Summarization: Paper Meta-review Generation Dataset, Methods, and Evaluation
Qi Zeng, Mankeerat Sidhu, Ansel Blume, Hou Pong Chan, Lu Wang, Heng Ji
Opinions in scientific research papers can be divergent, leading to controversies among reviewers. However, most existing datasets for opinion summarization are centered around product reviews and assume that the analyzed opinions are non-controversial, failing to account for the variability seen in other contexts such as academic papers, political debates, or social media discussions. To address this gap, we propose the task of scientific opinion summarization, where research paper reviews are synthesized into meta-reviews. To facilitate this task, we introduce the ORSUM dataset covering 15,062 paper meta-reviews and 57,536 paper reviews from 47 conferences. Furthermore, we propose the Checklist-guided Iterative Introspection approach, which breaks down scientific opinion summarization into several stages, iteratively refining the summary under the guidance of questions from a checklist. Our experiments show that (1) human-written summaries do not always satisfy all necessary criteria such as depth of discussion, and identifying consensus and controversy for the specific domain, and (2) the combination of task decomposition and iterative self-refinement shows strong potential for enhancing the opinions and can be applied to other complex text generation using black-box LLMs.
Read more6/18/2024

0
A Sentiment Consolidation Framework for Meta-Review Generation
Miao Li, Jey Han Lau, Eduard Hovy
Modern natural language generation systems with Large Language Models (LLMs) exhibit the capability to generate a plausible summary of multiple documents; however, it is uncertain if they truly possess the capability of information consolidation to generate summaries, especially on documents with opinionated information. We focus on meta-review generation, a form of sentiment summarisation for the scientific domain. To make scientific sentiment summarization more grounded, we hypothesize that human meta-reviewers follow a three-layer framework of sentiment consolidation to write meta-reviews. Based on the framework, we propose novel prompting methods for LLMs to generate meta-reviews and evaluation metrics to assess the quality of generated meta-reviews. Our framework is validated empirically as we find that prompting LLMs based on the framework -- compared with prompting them with simple instructions -- generates better meta-reviews.
Read more6/5/2024

0
SurveySum: A Dataset for Summarizing Multiple Scientific Articles into a Survey Section
Leandro Car'isio Fernandes, Gustavo Bartz Guedes, Thiago Soares Laitz, Thales Sales Almeida, Rodrigo Nogueira, Roberto Lotufo, Jayr Pereira
Document summarization is a task to shorten texts into concise and informative summaries. This paper introduces a novel dataset designed for summarizing multiple scientific articles into a section of a survey. Our contributions are: (1) SurveySum, a new dataset addressing the gap in domain-specific summarization tools; (2) two specific pipelines to summarize scientific articles into a section of a survey; and (3) the evaluation of these pipelines using multiple metrics to compare their performance. Our results highlight the importance of high-quality retrieval stages and the impact of different configurations on the quality of generated summaries.
Read more8/30/2024
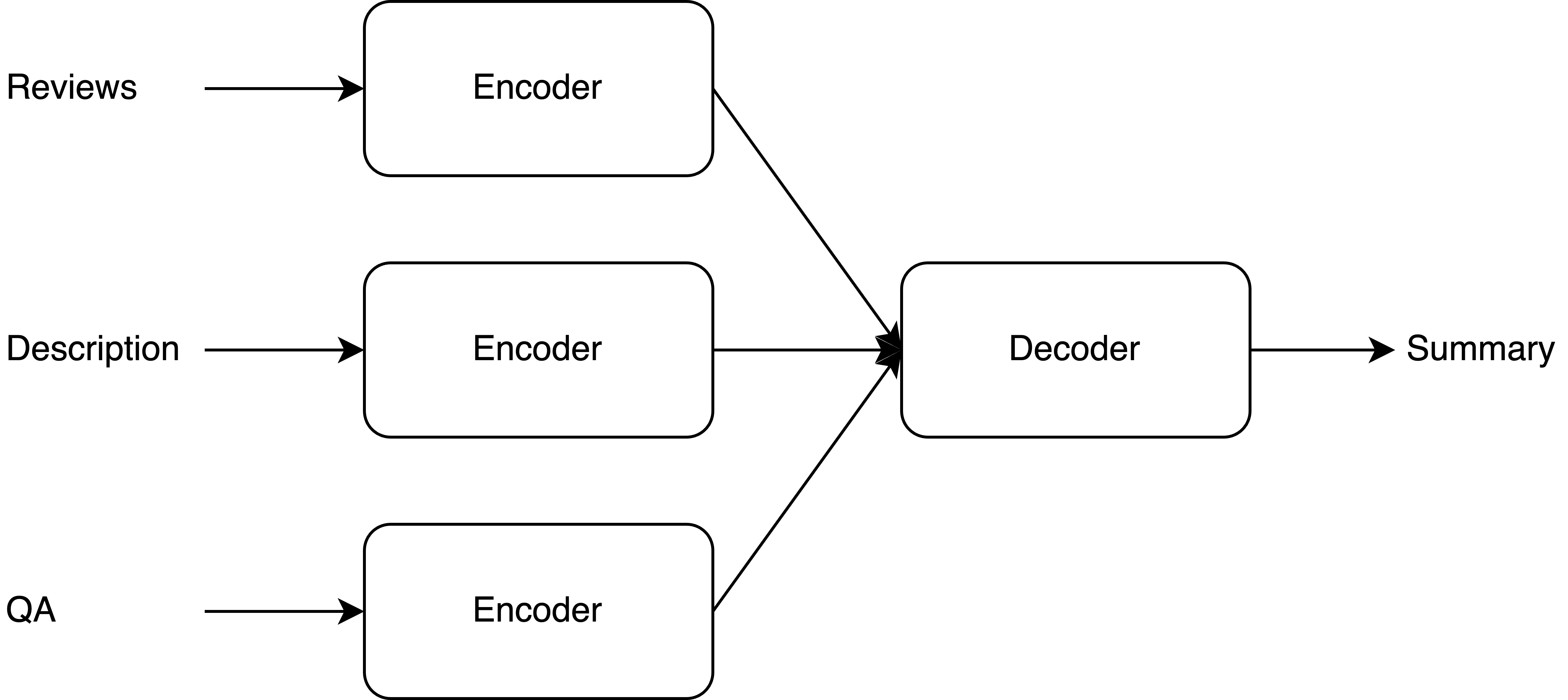
0
Product Description and QA Assisted Self-Supervised Opinion Summarization
Tejpalsingh Siledar, Rupasai Rangaraju, Sankara Sri Raghava Ravindra Muddu, Suman Banerjee, Amey Patil, Sudhanshu Shekhar Singh, Muthusamy Chelliah, Nikesh Garera, Swaprava Nath, Pushpak Bhattacharyya
In e-commerce, opinion summarization is the process of summarizing the consensus opinions found in product reviews. However, the potential of additional sources such as product description and question-answers (QA) has been considered less often. Moreover, the absence of any supervised training data makes this task challenging. To address this, we propose a novel synthetic dataset creation (SDC) strategy that leverages information from reviews as well as additional sources for selecting one of the reviews as a pseudo-summary to enable supervised training. Our Multi-Encoder Decoder framework for Opinion Summarization (MEDOS) employs a separate encoder for each source, enabling effective selection of information while generating the summary. For evaluation, due to the unavailability of test sets with additional sources, we extend the Amazon, Oposum+, and Flipkart test sets and leverage ChatGPT to annotate summaries. Experiments across nine test sets demonstrate that the combination of our SDC approach and MEDOS model achieves on average a 14.5% improvement in ROUGE-1 F1 over the SOTA. Moreover, comparative analysis underlines the significance of incorporating additional sources for generating more informative summaries. Human evaluations further indicate that MEDOS scores relatively higher in coherence and fluency with 0.41 and 0.5 (-1 to 1) respectively, compared to existing models. To the best of our knowledge, we are the first to generate opinion summaries leveraging additional sources in a self-supervised setting.
Read more4/9/2024