CPM: Class-conditional Prompting Machine for Audio-visual Segmentation

0

Sign in to get full access
Overview
- The paper introduces a novel method called the Class-conditional Prompting Machine (CPM) for audio-visual segmentation tasks.
- CPM leverages class-conditional prompting to fuse audio and visual information, enabling robust and accurate segmentation.
- The proposed approach outperforms state-of-the-art methods on several benchmark datasets for audio-visual segmentation.
Plain English Explanation
The CPM: Class-conditional Prompting Machine for Audio-visual Segmentation paper presents a new technique called the Class-conditional Prompting Machine (CPM) for handling audio-visual segmentation problems. Audio-visual segmentation is the task of identifying and separating different objects or elements in an image or video based on both the visual and audio information.
The key idea behind CPM is to use class-conditional prompting to effectively combine the audio and visual data. Class-conditional prompting means that the model is given additional information about the class or category of the object it is trying to segment. This extra context helps the model make more accurate decisions when fusing the audio and visual inputs.
For example, if the model is trying to segment a cat in an image, it might receive a prompt telling it that the object is a "cat." This prompt, along with the audio and visual data, allows the model to better understand and localize the cat in the image.
The researchers show that this CPM approach outperforms other state-of-the-art methods for audio-visual segmentation on several benchmark datasets. This suggests that the class-conditional prompting technique is a valuable addition to the toolkit for audio-visual understanding and perception tasks.
Technical Explanation
The CPM: Class-conditional Prompting Machine for Audio-visual Segmentation paper introduces a novel method called the Class-conditional Prompting Machine (CPM) for audio-visual segmentation tasks.
The key innovation of CPM is the use of class-conditional prompting to effectively fuse audio and visual information. Specifically, the model receives not only the input audio and visual data, but also a class-conditional prompt that provides additional context about the object or category being segmented.
This class-conditional prompt is integrated into the model's architecture through a series of cross-modal attention mechanisms. The audio and visual features are first processed independently, then combined using the class-conditional prompt to produce the final segmentation output.
The researchers evaluate CPM on several benchmark datasets for audio-visual segmentation, including Progressive Confident Masking Attention Network for Audio-Visual, Cross-Modal Cognitive Consensus Guided Audio-Visual, Separate Speech Chain Cross-Modal Conditional Audio, and Multi-Prompt Depth Partitioned Cross-Modal Learning. The results show that CPM consistently outperforms state-of-the-art methods, demonstrating the effectiveness of the class-conditional prompting approach for audio-visual segmentation.
Critical Analysis
The CPM: Class-conditional Prompting Machine for Audio-visual Segmentation paper presents a well-designed and thoroughly evaluated method for audio-visual segmentation. The class-conditional prompting technique is a novel and promising approach that leverages additional contextual information to improve the fusion of audio and visual data.
However, the paper does not address certain limitations or potential concerns. For instance, the reliance on class-conditional prompts may limit the model's generalization to out-of-distribution or unseen object categories. Additionally, the paper does not explore the interpretability or explainability of the class-conditional prompting mechanisms, which could be valuable for understanding the model's decision-making process.
Furthermore, the paper focuses on evaluating CPM on existing benchmark datasets, but it does not provide insights into how the method might perform in real-world, unconstrained audio-visual scenarios. Extending the evaluation to more diverse and challenging settings could help assess the practical applicability and robustness of the proposed approach.
Despite these limitations, the CPM: Class-conditional Prompting Machine for Audio-visual Segmentation paper makes a valuable contribution to the field of audio-visual learning and segmentation. The class-conditional prompting technique presents an interesting direction for further research and development in this area.
Conclusion
The CPM: Class-conditional Prompting Machine for Audio-visual Segmentation paper introduces a novel method called the Class-conditional Prompting Machine (CPM) that leverages class-conditional prompting to effectively fuse audio and visual information for segmentation tasks. The proposed approach outperforms state-of-the-art methods on several benchmark datasets, demonstrating the effectiveness of the class-conditional prompting technique for audio-visual understanding and perception.
While the paper has some limitations in terms of generalization and interpretability, the CPM method presents an interesting and valuable contribution to the field of audio-visual learning. The class-conditional prompting approach could inspire further research and development in multimodal learning and segmentation, potentially leading to more robust and versatile models for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CPM: Class-conditional Prompting Machine for Audio-visual Segmentation
Yuanhong Chen, Chong Wang, Yuyuan Liu, Hu Wang, Gustavo Carneiro
Audio-visual segmentation (AVS) is an emerging task that aims to accurately segment sounding objects based on audio-visual cues. The success of AVS learning systems depends on the effectiveness of cross-modal interaction. Such a requirement can be naturally fulfilled by leveraging transformer-based segmentation architecture due to its inherent ability to capture long-range dependencies and flexibility in handling different modalities. However, the inherent training issues of transformer-based methods, such as the low efficacy of cross-attention and unstable bipartite matching, can be amplified in AVS, particularly when the learned audio query does not provide a clear semantic clue. In this paper, we address these two issues with the new Class-conditional Prompting Machine (CPM). CPM improves the bipartite matching with a learning strategy combining class-agnostic queries with class-conditional queries. The efficacy of cross-modal attention is upgraded with new learning objectives for the audio, visual and joint modalities. We conduct experiments on AVS benchmarks, demonstrating that our method achieves state-of-the-art (SOTA) segmentation accuracy.
Read more7/17/2024

0
Progressive Confident Masking Attention Network for Audio-Visual Segmentation
Yuxuan Wang, Feng Dong, Jinchao Zhu
Audio and visual signals typically occur simultaneously, and humans possess an innate ability to correlate and synchronize information from these two modalities. Recently, a challenging problem known as Audio-Visual Segmentation (AVS) has emerged, intending to produce segmentation maps for sounding objects within a scene. However, the methods proposed so far have not sufficiently integrated audio and visual information, and the computational costs have been extremely high. Additionally, the outputs of different stages have not been fully utilized. To facilitate this research, we introduce a novel Progressive Confident Masking Attention Network (PMCANet). It leverages attention mechanisms to uncover the intrinsic correlations between audio signals and visual frames. Furthermore, we design an efficient and effective cross-attention module to enhance semantic perception by selecting query tokens. This selection is determined through confidence-driven units based on the network's multi-stage predictive outputs. Experiments demonstrate that our network outperforms other AVS methods while requiring less computational resources.
Read more6/5/2024

0
Cross-modal Cognitive Consensus guided Audio-Visual Segmentation
Zhaofeng Shi, Qingbo Wu, Fanman Meng, Linfeng Xu, Hongliang Li
Audio-Visual Segmentation (AVS) aims to extract the sounding object from a video frame, which is represented by a pixel-wise segmentation mask for application scenarios such as multi-modal video editing, augmented reality, and intelligent robot systems. The pioneering work conducts this task through dense feature-level audio-visual interaction, which ignores the dimension gap between different modalities. More specifically, the audio clip could only provide a Global semantic label in each sequence, but the video frame covers multiple semantic objects across different Local regions, which leads to mislocalization of the representationally similar but semantically different object. In this paper, we propose a Cross-modal Cognitive Consensus guided Network (C3N) to align the audio-visual semantics from the global dimension and progressively inject them into the local regions via an attention mechanism. Firstly, a Cross-modal Cognitive Consensus Inference Module (C3IM) is developed to extract a unified-modal label by integrating audio/visual classification confidence and similarities of modality-agnostic label embeddings. Then, we feed the unified-modal label back to the visual backbone as the explicit semantic-level guidance via a Cognitive Consensus guided Attention Module (CCAM), which highlights the local features corresponding to the interested object. Extensive experiments on the Single Sound Source Segmentation (S4) setting and Multiple Sound Source Segmentation (MS3) setting of the AVSBench dataset demonstrate the effectiveness of the proposed method, which achieves state-of-the-art performance. Code is available at https://github.com/ZhaofengSHI/AVS-C3N.
Read more7/18/2024
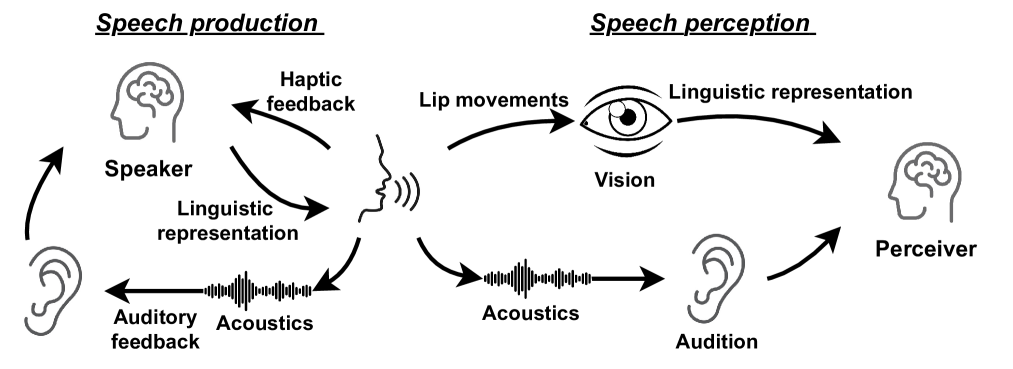
0
Separate in the Speech Chain: Cross-Modal Conditional Audio-Visual Target Speech Extraction
Zhaoxi Mu, Xinyu Yang
The integration of visual cues has revitalized the performance of the target speech extraction task, elevating it to the forefront of the field. Nevertheless, this multi-modal learning paradigm often encounters the challenge of modality imbalance. In audio-visual target speech extraction tasks, the audio modality tends to dominate, potentially overshadowing the importance of visual guidance. To tackle this issue, we propose AVSepChain, drawing inspiration from the speech chain concept. Our approach partitions the audio-visual target speech extraction task into two stages: speech perception and speech production. In the speech perception stage, audio serves as the dominant modality, while visual information acts as the conditional modality. Conversely, in the speech production stage, the roles are reversed. This transformation of modality status aims to alleviate the problem of modality imbalance. Additionally, we introduce a contrastive semantic matching loss to ensure that the semantic information conveyed by the generated speech aligns with the semantic information conveyed by lip movements during the speech production stage. Through extensive experiments conducted on multiple benchmark datasets for audio-visual target speech extraction, we showcase the superior performance achieved by our proposed method.
Read more5/7/2024