Progressive Confident Masking Attention Network for Audio-Visual Segmentation

0

Sign in to get full access
Overview
- This paper presents a novel audio-visual segmentation model called the Progressive Confident Masking Attention Network (PCMAN).
- PCMAN uses a cross-modal attention mechanism to fuse audio and visual information, enabling improved segmentation performance.
- The model dynamically adjusts its attention weights during inference, allowing it to focus on the most relevant modality at each step.
- Experiments on standard benchmarks demonstrate PCMAN's strong performance compared to prior audio-visual segmentation approaches.
Plain English Explanation
The researchers developed a new deep learning model called the Progressive Confident Masking Attention Network (PCMAN) that can perform audio-visual segmentation. Audio-visual segmentation is the task of identifying and separating different objects or elements in a video by using both the audio and visual information.
The key innovation of PCMAN is its cross-modal attention mechanism, which allows the model to dynamically focus on the most relevant audio or visual cues at each stage of the segmentation process. This helps the model make better use of the complementary information provided by the audio and visual modalities.
For example, when segmenting a video of a person speaking, the model might initially focus more on the visual features to locate the person's face and body. As it progresses, it might shift its attention more to the audio features to better distinguish the person's voice from background sounds. This flexibility allows PCMAN to achieve higher accuracy compared to prior audio-visual segmentation approaches that use more static fusion techniques.
The researchers evaluated PCMAN on standard benchmark datasets and found that it outperformed other state-of-the-art models. This suggests PCMAN is a promising approach for applications that require accurately separating and identifying different elements in audio-visual data, such as video editing, virtual reality, and autonomous driving.
Technical Explanation
The core of the PCMAN architecture is a cross-modal attention mechanism that dynamically fuses audio and visual features. This mechanism consists of several key components:
-
Audio and Visual Encoders: The model first processes the audio and visual inputs through separate encoder networks to extract relevant features from each modality.
-
Cross-Modal Attention: The audio and visual features are then passed through a cross-modal attention layer, which computes attention weights that indicate how much each modality should contribute to the final representation at each spatial location.
-
Progressive Confident Masking: To further improve the model's ability to focus on the most relevant information, PCMAN uses a progressive confident masking approach. This adjusts the attention weights over the course of the segmentation process, gradually increasing the emphasis on the more confident modality.
-
Segmentation Head: The fused audio-visual representation is then passed through a segmentation head, which produces the final pixel-wise segmentation output.
The researchers evaluated PCMAN on standard audio-visual segmentation benchmarks, including MUSIC and AVE. They found that PCMAN outperformed prior state-of-the-art models, such as MCAV and SeparateSpeechChain, demonstrating the effectiveness of its cross-modal attention and progressive confident masking approach.
Critical Analysis
One potential limitation of the PCMAN model is that it relies on the audio and visual encoders to separately extract features from each modality before fusing them. This could limit the model's ability to learn truly integrated audio-visual representations, as the initial feature extraction is still performed in a siloed manner.
Additionally, the progressive confident masking approach, while effective, may not be optimal for all types of audio-visual data. In some cases, a more balanced or dynamically adjusted fusion strategy could be more appropriate, depending on the specific characteristics of the input.
Further research could explore alternative cross-modal fusion techniques, such as those used in audio-visual person verification or other multi-modal learning problems, to see if they can further improve the performance of audio-visual segmentation models like PCMAN.
Conclusion
The Progressive Confident Masking Attention Network (PCMAN) presents a novel approach to audio-visual segmentation that leverages a dynamic cross-modal attention mechanism to effectively fuse audio and visual information. The model's strong performance on benchmark datasets suggests it is a promising step forward in developing robust and flexible audio-visual understanding systems, with potential applications in areas like video editing, virtual reality, and autonomous driving.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Progressive Confident Masking Attention Network for Audio-Visual Segmentation
Yuxuan Wang, Feng Dong, Jinchao Zhu
Audio and visual signals typically occur simultaneously, and humans possess an innate ability to correlate and synchronize information from these two modalities. Recently, a challenging problem known as Audio-Visual Segmentation (AVS) has emerged, intending to produce segmentation maps for sounding objects within a scene. However, the methods proposed so far have not sufficiently integrated audio and visual information, and the computational costs have been extremely high. Additionally, the outputs of different stages have not been fully utilized. To facilitate this research, we introduce a novel Progressive Confident Masking Attention Network (PMCANet). It leverages attention mechanisms to uncover the intrinsic correlations between audio signals and visual frames. Furthermore, we design an efficient and effective cross-attention module to enhance semantic perception by selecting query tokens. This selection is determined through confidence-driven units based on the network's multi-stage predictive outputs. Experiments demonstrate that our network outperforms other AVS methods while requiring less computational resources.
Read more6/5/2024

0
Cross-modal Cognitive Consensus guided Audio-Visual Segmentation
Zhaofeng Shi, Qingbo Wu, Fanman Meng, Linfeng Xu, Hongliang Li
Audio-Visual Segmentation (AVS) aims to extract the sounding object from a video frame, which is represented by a pixel-wise segmentation mask for application scenarios such as multi-modal video editing, augmented reality, and intelligent robot systems. The pioneering work conducts this task through dense feature-level audio-visual interaction, which ignores the dimension gap between different modalities. More specifically, the audio clip could only provide a Global semantic label in each sequence, but the video frame covers multiple semantic objects across different Local regions, which leads to mislocalization of the representationally similar but semantically different object. In this paper, we propose a Cross-modal Cognitive Consensus guided Network (C3N) to align the audio-visual semantics from the global dimension and progressively inject them into the local regions via an attention mechanism. Firstly, a Cross-modal Cognitive Consensus Inference Module (C3IM) is developed to extract a unified-modal label by integrating audio/visual classification confidence and similarities of modality-agnostic label embeddings. Then, we feed the unified-modal label back to the visual backbone as the explicit semantic-level guidance via a Cognitive Consensus guided Attention Module (CCAM), which highlights the local features corresponding to the interested object. Extensive experiments on the Single Sound Source Segmentation (S4) setting and Multiple Sound Source Segmentation (MS3) setting of the AVSBench dataset demonstrate the effectiveness of the proposed method, which achieves state-of-the-art performance. Code is available at https://github.com/ZhaofengSHI/AVS-C3N.
Read more7/18/2024

0
CPM: Class-conditional Prompting Machine for Audio-visual Segmentation
Yuanhong Chen, Chong Wang, Yuyuan Liu, Hu Wang, Gustavo Carneiro
Audio-visual segmentation (AVS) is an emerging task that aims to accurately segment sounding objects based on audio-visual cues. The success of AVS learning systems depends on the effectiveness of cross-modal interaction. Such a requirement can be naturally fulfilled by leveraging transformer-based segmentation architecture due to its inherent ability to capture long-range dependencies and flexibility in handling different modalities. However, the inherent training issues of transformer-based methods, such as the low efficacy of cross-attention and unstable bipartite matching, can be amplified in AVS, particularly when the learned audio query does not provide a clear semantic clue. In this paper, we address these two issues with the new Class-conditional Prompting Machine (CPM). CPM improves the bipartite matching with a learning strategy combining class-agnostic queries with class-conditional queries. The efficacy of cross-modal attention is upgraded with new learning objectives for the audio, visual and joint modalities. We conduct experiments on AVS benchmarks, demonstrating that our method achieves state-of-the-art (SOTA) segmentation accuracy.
Read more7/17/2024
0
Unveiling and Mitigating Bias in Audio Visual Segmentation
Peiwen Sun, Honggang Zhang, Di Hu
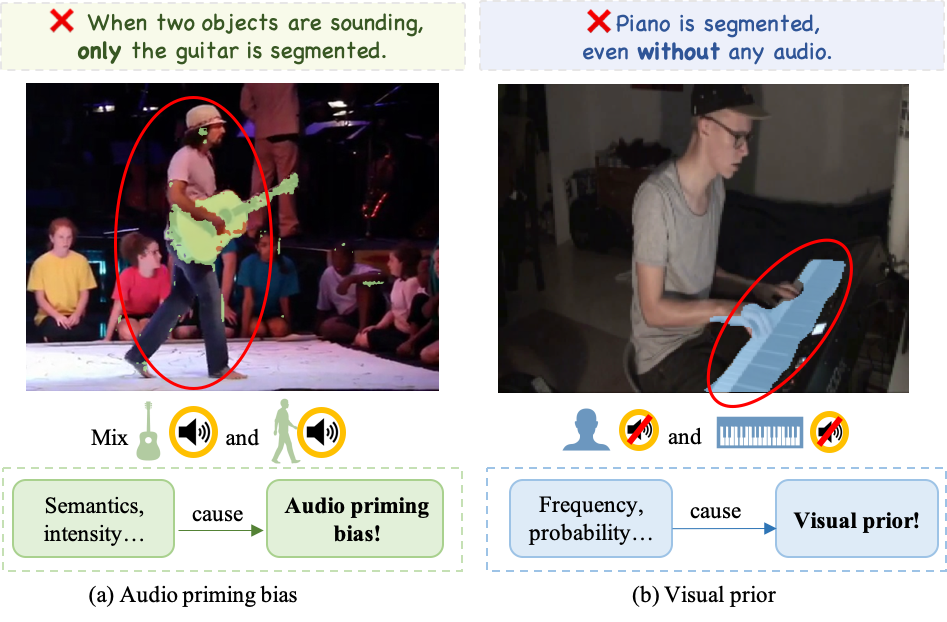
Community researchers have developed a range of advanced audio-visual segmentation models aimed at improving the quality of sounding objects' masks. While masks created by these models may initially appear plausible, they occasionally exhibit anomalies with incorrect grounding logic. We attribute this to real-world inherent preferences and distributions as a simpler signal for learning than the complex audio-visual grounding, which leads to the disregard of important modality information. Generally, the anomalous phenomena are often complex and cannot be directly observed systematically. In this study, we made a pioneering effort with the proper synthetic data to categorize and analyze phenomena as two types audio priming bias and visual prior according to the source of anomalies. For audio priming bias, to enhance audio sensitivity to different intensities and semantics, a perception module specifically for audio perceives the latent semantic information and incorporates information into a limited set of queries, namely active queries. Moreover, the interaction mechanism related to such active queries in the transformer decoder is customized to adapt to the need for interaction regulating among audio semantics. For visual prior, multiple contrastive training strategies are explored to optimize the model by incorporating a biased branch, without even changing the structure of the model. During experiments, observation demonstrates the presence and the impact that has been produced by the biases of the existing model. Finally, through experimental evaluation of AVS benchmarks, we demonstrate the effectiveness of our methods in handling both types of biases, achieving competitive performance across all three subsets.
Read more7/24/2024